注册schema时出错。通过KafkaREST无法生成AVRO消息。错误代码:40801。
 社区干货
社区干货
Pulsar 在云原生消息引擎领域为何如此流行?| 社区征文
消息携带的数据,所有 Pulsar 的消息携带原始 bytes,但是消息数据也需要遵循数据 schemas。 || Key | 消息可以被 Key 打标签。这可以对 topic 压缩之类的事情起作用。 || Properties | 可选的,用户定义属性的 ke... 比如消息键、消息值。设置TypedMessageBuilder时,将键设置为字符串。如果您将键设置为其他类型,例如,AVRO对象,则键将作为字节发送,并且很难从消费者处取回AVRO对象。 |消息的默认大小为 5 MB,可以通过以下方式配...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
生成逻辑执行计划,优化执行计划,调度和执行 query,并将最终结果返回给用户。服务节点是无状态的,意味着用户可以接入任意一个服务节点(当然如果有需要,也可以隔离开),并且可以水平扩展,意味着平台具备支持高并发查询的能力。- **元数据服务**元数据服务(Catalog Service)提供对查询相关元数据信息的读写。Metadata 主要包括 2 部分:Table 的元数据和 Part 的元数据。表的元数据信息主要包括表的 Schema,partitioning sche...
干货|十分钟读懂字节跳动的Doris湖仓分析实践
Presto,Trino等多种计算引擎。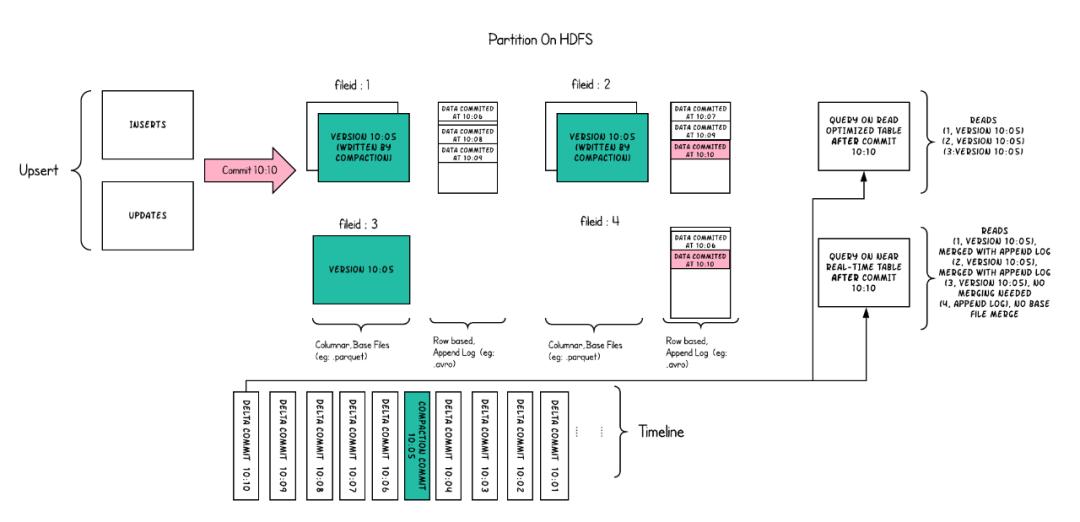Hudi根据数据更新时行为不同分为两种表类型:!... 在线分析处理实时数据,使用Flink/Spark Streaming处理流式数据,分析处理秒级或分钟级流式数据,数据保存在Kafka或定期(分钟级)保存到HDFS中。该套方案存在以下缺点:- 同一套指标可能需要开发两份代码来进行在...
由浅入深,揭秘企业级 OLAP 数据引擎 ByteHouse
schema,statistics,数据的索引等信息。元数据信息会持久化保存在状态存储池里面,为了降低对元数据库的访问压力,对于访问频度高的元数据会进行缓存。元数据服务自身只负责处理对元数据的请求,自身是无状态的,可以水平扩展。- 安全管理权限控制和安全管理,包括入侵检测、用户角色管理、授权管理、访问白名单管理、安全审计等功能。### 计算层通过容器编排平台(如 Kubernetes)来实现计算资源管理,所有计算资源都放在...
 特惠活动
特惠活动
 注册schema时出错。通过KafkaREST无法生成AVRO消息。错误代码:40801。
-优选内容
注册schema时出错。通过KafkaREST无法生成AVRO消息。错误代码:40801。
-优选内容
 注册schema时出错。通过KafkaREST无法生成AVRO消息。错误代码:40801。
-相关内容
注册schema时出错。通过KafkaREST无法生成AVRO消息。错误代码:40801。
-相关内容
干货|十分钟读懂字节跳动的Doris湖仓分析实践
Presto,Trino等多种计算引擎。Hudi根据数据更新时行为不同分为两种表类型:!... 在线分析处理实时数据,使用Flink/Spark Streaming处理流式数据,分析处理秒级或分钟级流式数据,数据保存在Kafka或定期(分钟级)保存到HDFS中。该套方案存在以下缺点:- 同一套指标可能需要开发两份代码来进行在...
由浅入深,揭秘企业级 OLAP 数据引擎 ByteHouse
schema,statistics,数据的索引等信息。元数据信息会持久化保存在状态存储池里面,为了降低对元数据库的访问压力,对于访问频度高的元数据会进行缓存。元数据服务自身只负责处理对元数据的请求,自身是无状态的,可以水平扩展。- 安全管理权限控制和安全管理,包括入侵检测、用户角色管理、授权管理、访问白名单管理、安全审计等功能。### 计算层通过容器编排平台(如 Kubernetes)来实现计算资源管理,所有计算资源都放在...
干货|十分钟读懂字节跳动的Doris湖仓分析实践
实时更新聚合指标。* **提供了高可用,**容错处理,高扩展的企业级特性。FE Leader错误异常,FE Follower秒级切换为新Leader继续对外提供服务。* **支持聚合表和物化视图。**多种数据模型,支持aggregate,repl... 在线分析处理实时数据,使用Flink/Spark Streaming处理流式数据,分析处理秒级或分钟级流式数据,数据保存在Kafka或定期(分钟级)保存到HDFS中。该套方案存在以下缺点:* 同一套指标可能需要开发两份代码来进行...
观点 | 如何构建面向海量数据、高实时要求的企业级OLAP数据引擎?
schema,statistics,数据的索引等信息。元数据信息会持久化保存在状态存储池里面,为了降低对元数据库的访问压力,对于访问频度高的元数据会进行缓存。元数据服务自身只负责处理对元数据的请求,自身是无状态的,可以水平扩展。* **安全管理**权限控制和安全管理,包括入侵检测、用户角色管理、授权管理、访问白名单管理、安全审计等功能。计算层通过容器编排平台(如 Kubernetes)来实现计算资源管理,所有...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
ByteHouse 支持离线数据导入和实时数据导入。### 离线导入离线导入数据源:- Object Storage:S3、OSS、Minio- Hive (1.0+)- Apache Kafka /Confluent Cloud/AWS Kinesis- 本地文件- RDS ... Avro- Parquet- Excel (xls)### 实时导入ByteHouse 能够连接到 Kafka,并将数据持续传输到目标数据表中。与离线导入不同,Kafka 任务一旦启动将持续运行。ByteHouse 的 Kafka 导入任务能够提供 exactl...
字节跳动湖平台在批计算和特征场景的实践
RestCatalog 等不同的实现方式,其底层存储信息会略有不同;RestCatalog 方式无需对接任何一种具体的存储,而是通过提供 Restful API 接口,借助 Web 服务实现 Catalog,进一步实现了底层存储的解耦。- **Metadata File**:用来存储表的元数据信息,包括表的 Schema、分区信息、快照信息( Snapshot )等。Snapshot 是快照信息,表示表在某一时刻的状态;用户每次对 Table 进行一次写操作,均会生成一个新的 SnapShot。 Manifestlist 是清...
十分钟读懂字节跳动的 Doris 湖仓分析实践
Presto,Trino 等多种计算引擎。保存到 HDFS 中。该套方案存在以下缺点:- 同一套指标可能需要开发两份代码来...
Flink 使用 Proton
Schema;import org.apache.flink.api.common.typeinfo.Types;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.api.java.utils.ParameterTool;import org.apache.flink.connector.kafka.source.KafkaSource;import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;import org.apache.flink.core.fs.Path;import org.apache.flink.formats.parquet.avro.AvroParquetW...
字节跳动湖平台在批计算和特征场景的实践
RestCatalog 等+ 不同的实现方式,其底层存储信息会略有不同;RestCatalog 方式无需对接任何一种具体的存储,而是通过提供 Restful API 接口,借助 Web 服务实现 Catalog,进一步实现了底层存储的解耦。* Metadata File:存储表的元数据信息,包括表的 Schema、分区信息、快照信息( Snapshot )等。+ Snapshot 是快照信息,表示表在某一时刻的状态;用户每次对 Table 进行一次写操作,均会生成一个新的 SnapShot。+ Manifestlist 是清单...
