数据库上下文的依赖注入错误
 社区干货
社区干货
达梦@记一次国产数据库适配思考过程|社区征文
若是通过**Mysql或Oracle或其他数据库,文件等方式迁移导入**。这里记录一下迁移过程中遇到的问题,**在迁移的时候,报某些字段超长**。于是,查看了MySql中那些字段的类型及长度,都是varchar(50) 。这里应该是迁移有些... 达梦数据库环境安装,相关版本及其依赖的选取跟引入,配置信息完毕。## Q-A NO.2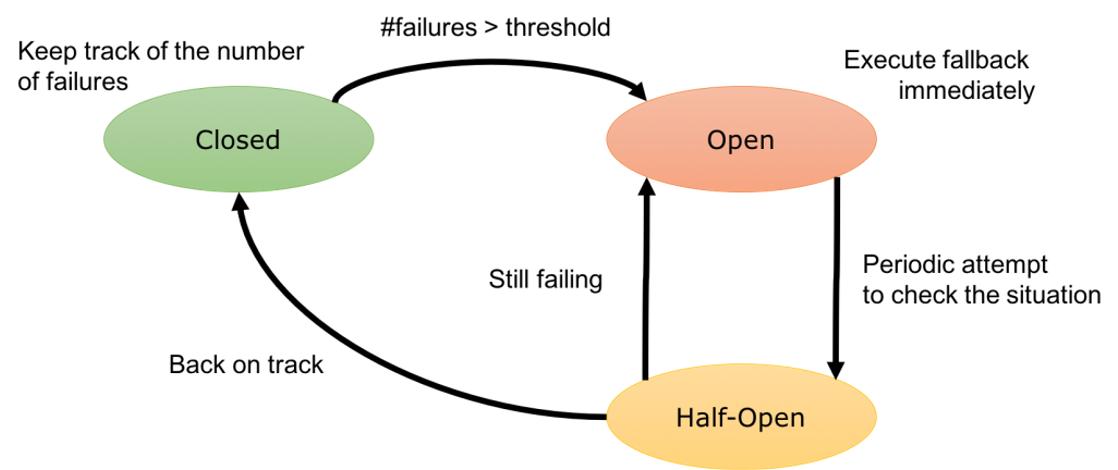#### Centralized met...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
因而也衍生出很多数据库连接池,例如C3P0,DBCP等。# Hive的JDBC实现构建SparkSQL服务器最好的方式是用如上Java接口,且大数据生态下行业已有标杆例子,即Hive Server2。Hive Server2在遵循Java JDBC接口规范上,通... 通过如下的依赖便可引入:``` org.apache.hive hive-jdbc version/version> ```在HiveConnection类中实现了将Java中定义的SQL访问接口转化为调用Hive Server2的RPC接口的实现,并且扩充了一部分Java定义中没有的...
VikingDB:大规模云原生向量数据库的前沿实践与应用
通过检索为大模型提供相关数据作为上下文信息。由于向量数据库能够高效存储和检索模型生成的向量,从而提供语义上更具有相关性的检索结果,因此向量数据库成了 ES 之外的 RAG 必不可少的检索工具,RAG 也成为了向量数... * 自研 UDF 过滤函数注入机制,实现图灵完备的过滤计算。**极端规模场景**除了在线检索相关的性能问题外,离线建库中会有一些极端场景,诸如亿级数据天级建库、10k QPS 突发写入等超大规模的数据量和超大吞吐的...
 特惠活动
特惠活动
 数据库上下文的依赖注入错误
-优选内容
数据库上下文的依赖注入错误
-优选内容
 数据库上下文的依赖注入错误
-相关内容
数据库上下文的依赖注入错误
-相关内容
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
因而也衍生出很多数据库连接池,例如C3P0,DBCP等。# **3. Hive 的 JDBC 实现**构建SparkSQL服务器最好的方式是用如上Java接口,且大数据生态下行业已有标杆例子,即Hive Server2。Hive Server2在遵循Java JDBC接口... 通过如下的依赖便可引入: ``` org.apache.hive hive-jdbc version/version> ```在HiveConnection类中实现了将Java中定义的SQL访问接口转化为调用Hive Server2的RPC接口的实现,并且扩充了一部分Java定义中缺乏...
替换 Spring Cloud,使用基于 Cloud Native 的服务治理
文件或启动参数的方式注入到应用中去,就像敲 Linux 命令一样方便。我们会发现 **Spring Cloud Config Server 更像是一个独立的软件,Kubernetes 的 ConfigMap 更像是软件内的功能** ,这就是两者之间的区别。... 错误多少次之后会被拒绝、进行 Half-Open 重试的间隔等。