如何访问df的第一行元素?
 社区干货
社区干货
阿里巴巴的 Java 开发手册(黄山版)来了
怎么样?"**,我仔细一看这不是孤尽老师的著作吗?居然已经更新到了黄山版。上次看这本小册子的时候还是上次——19年的时候我看的华山版的。再往前那就是17年的第一版了,当时是在阿里的公众号下载的,后来还买了实体... ### 2.2 访问权限控制从严> 类成员与方法访问控制从严。- 如果不允许外部直接通过 new 来创建对象,那么构造方法必须是 private。- 工具类不允许有 public 或 default 构造方法。- 类非 static 成员变量并且与子...
golang pprof
然后我们再执行 `go tool pprof cpu.pprof`,就可以进入到pprof的交互式终端。首先有... 所以第一行的sum%会等于第一行的flat%,而第二行的sum%就会是第一行的flat%加第二行的flat%,后边依次类推 || cum | cumulative,当前函数及当前函数的子函数占用的cpu时间 ...
DataLeap 数据资产实战:如何实现存储优化?
聚集索引 B+树排序访问,支持基于 Key 或者 Key-Column 的 Range Query,所有查询都走索引,且避免内存中重排序,效率初步判断可接受。- 中台内的其他系统,最大的 MySQL 单表已经到达亿级别,且 MySQL 有成熟的分库分... 则需要另行适配,适配时数据模型有两种方式:Key-Column-Value 和 Key-Value。**2、流程记录器:**通过流程记录器可以快速录制您在网页端的一系列操作,自动生成并保存自动化流程...
 特惠活动
特惠活动
 如何访问df的第一行元素?
-优选内容
如何访问df的第一行元素?
-优选内容
 如何访问df的第一行元素?
-相关内容
如何访问df的第一行元素?
-相关内容
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
以氪元素命名**” **引言** 近些年, 在复杂的分析需求之外,字节内部的业务对于实时数据的在线服务能力也提出了更高的要求。大部分业务不得不采用多套系统来应对不同... 存储-HDFS & NoSQL 团队共同合作研发的新一代面向复杂业务的实时服务分析系统(HSAP: Hybrid Serving and Analytical Processing),希望能在应对大数据复杂分析场景的同时,也能满足业务对于实时数据在线服务的需求。...
社区征文|ChatGPT教我如何面试
可以并发执行多个线程,提高程序的执行效率。###### Q:谈谈对线程安全的理解线程安全是指在多线程环境下,程序或者数据结构所提供的操作,在不需要额外同步手段的情况下,能够正确地处理并发访问,并且不会出现数据... 其中每个元素都是函数的应用。底层实现上,map() 函数会遍历可迭代对象中的每个元素,并对每个元素调用函数,然后将返回值存储在一个迭代器中。因此,通过使用 map() 函数,可以很容易地将某个函数应用到可迭代对象中的...
前端AST详解,手写babel插件|社区征文
表示数组的多个元素,每一个元素都是一个表达式节点。- VariableDeclaration(变量声明表达式):kind 属性表示是什么类型的声明,值可能是var/const/let。declarations表示声明的多个描述,因为我们可以这样:`let a = 2,b=3`。- VariableDecla...
火山引擎 Iceberg 数据湖的应用与实践
> 在云原生计算时代,云存储使得海量数据能以低成本进行存储,但是这也给如何访问、管理和使用这些云上的数据提出了挑战。而 Iceberg 作为一种云原生的表格式,可以很好地应对这些挑战。本文将介绍火山引擎在云原生计... Iceberg 是一种适用于 HDFS 或者对象存储的表格式,把底层的 Parquet、ORC 等数据文件组织成一张表,向上层的 Spark,Flink 计算引擎提供表层面的语义,作用类似于 Hive Meta Store,但是和 Hive Meta Store 相比:- ...
火山引擎 Iceberg 数据湖的应用与实践
云存储使得海量数据能以低成本进行存储,但是这也给如何访问、管理和使用这些云上的数据提出了挑战。而 Iceberg 作为一种云原生的表格式,可以很好地应对这些挑战。本文将介绍火山引擎在云原生计算产品上使用 Ice... Iceberg 是一种适用于 HDFS 或者对象存储的表格式,把底层的 Parquet、ORC 等数据文件组织成一张表,向上层的 Spark,Flink 计算引擎提供表层面的语义,作用类似于 Hive Meta Store,但是和 Hive Meta Store 相比:*...
干货|湖仓一体架构在火山引擎LAS的探索与实践
再往下就是 LAS基于火山引擎对象存储服务TOS和CloudFS ,来提供EB级的数据存储能力和数据访问的缓存加速能力。 以上就是 LAS整体的技术架构。 ,连续多行构成一个页,页的尾部通常会存储索引来解决record不定长时的快速查找问题,数据排列结构如下图所示: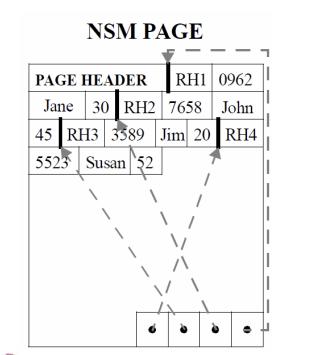列存和行存的区别主要是在...
基于 LoserTree 的 Paimon 多路归并优化
如果父子节点进行比较后发生了数据交换,那么会产生自顶向下的调整,这种调整每次都需要和两个子节点同时进行比较。1. **建堆**假设有 5 个待排序列,第一步需要将这 5 个待排序列的按照头元素的大小调整为小... =&rk3s=8031ce6d&x-expires=1715012454&x-signature=HMetGThDFcOAg642TX6sAt%2B924o%3D)2. **堆调整**每次排序时会从头节点取出当前最小的数据,将对应序列的下一个元素放到头结点,然后再自顶向下不断进行调整...
