c语言语音识别技术实现
 社区干货
社区干货
vue3+vite+ts项目集成科大讯飞语音识别|社区征文
APISecret、APIkey,在项目中会用到这三个参数,新用户有500条免费的服务量。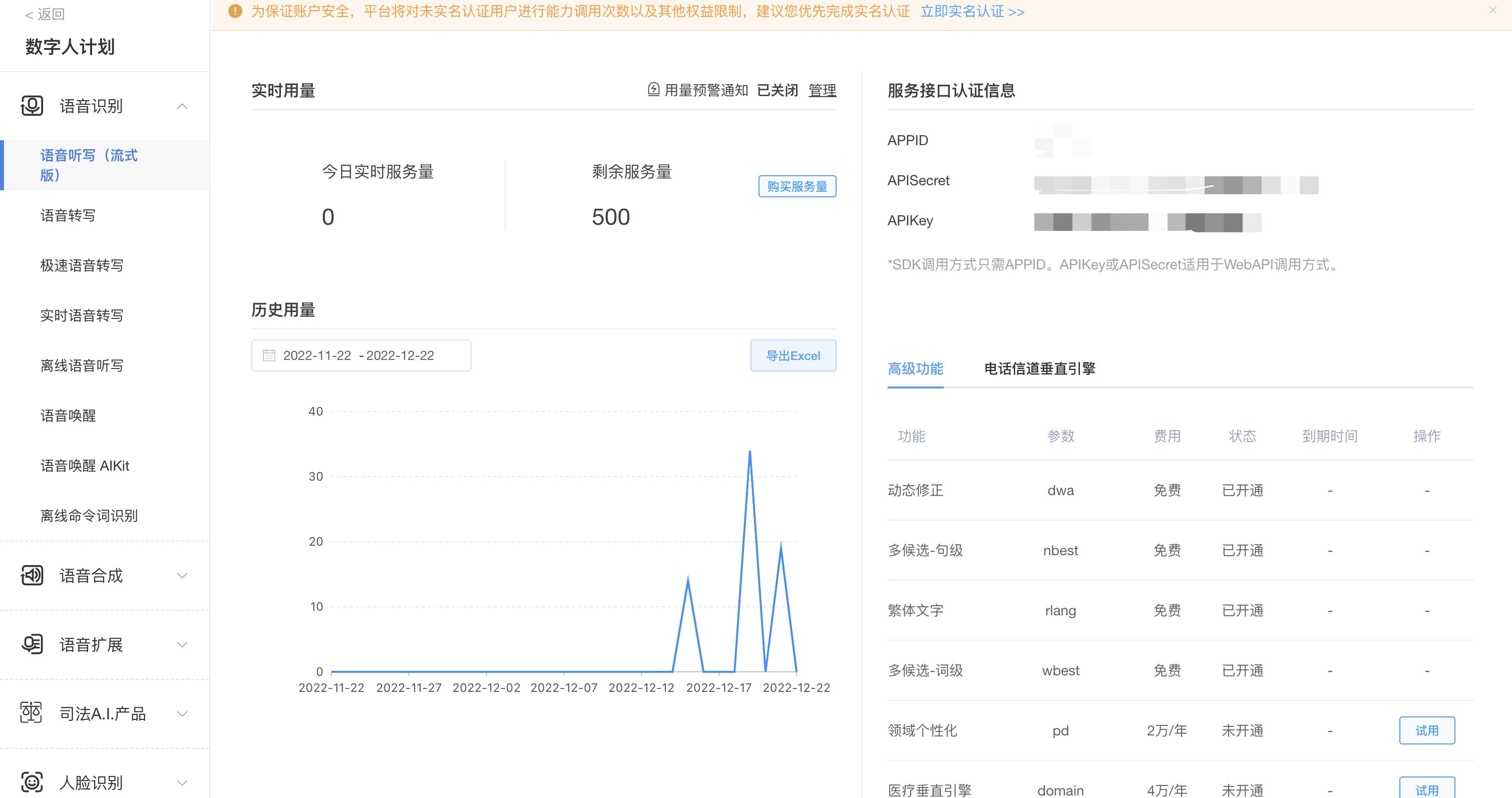## 三、下载语音识别demo[科大讯飞文档中心](https://www.xfyun.cn/doc/asr/voicedictation/API.html#%E6%8E%A5%E5%8F%A3%E8%AF%B4%E6%98%8E)中示例demo,博主选择的是js语言,注意该demo项目环境为webpack+js 特惠活动
特惠活动
 c语言语音识别技术实现-优选内容
c语言语音识别技术实现-优选内容
 c语言语音识别技术实现-相关内容
c语言语音识别技术实现-相关内容
【流式语音识别SDK】隐私政策
或您不想继续使用集成了【流式语音识别SDK】的应用,请直接与相应开发者(个人信息处理者)联系。 开发者作为“个人信息处理者”决定用户数据的处理目的、方式,我们在为开发者提供【实现流式语音识别SDK特定业务功能... 我们采集的信息不能单独识别特定自然人的身份,并且基于本SDK的技术特性,其在运行过程客观上无法获取任何能够单独识别特定自然人身份的信息。我们可能会对【流式语音识别SDK】的功能和提供的服务有所调整变化,但请您...
语音识别-本地化部署方案
让先进的语音识别技术摆脱云端依赖,为您快速提供私有化语音识别能力。支持本地部署和云端部署多种形式,广泛适用于呼叫中心质检、智能会议记录等多种使用场景。数据更安全,使用更放心
模型效果FAQ
Q:语音识别的准确率是如何衡量的,目前火山引擎的准确率大概是在什么水平?A:语音识别的准确率用字/词错误率(Char / Word Error Rate,CER / WER)来衡量,准确率 = 1 - 字错率。目前火山引擎的语音识别,在大部分的场景... 识别效果不好的情况,可考虑通过添加热词,提高该类词语的识别效果。您可以在 控制台-语音技术-自学习平台-热词管理中自主添加、使用、管理热词。详细使用方法可见:自学习平台-热词 方案二:语言模型优化 若您已添加...
vue3+vite+ts项目集成科大讯飞语音识别|社区征文
APISecret、APIkey,在项目中会用到这三个参数,新用户有500条免费的服务量。## 三、下载语音识别demo[科大讯飞文档中心](https://www.xfyun.cn/doc/asr/voicedictation/API.html#%E6%8E%A5%E5%8F%A3%E8%AF%B4%E6%98%8E)中示例demo,博主选择的是js语言,注意该demo项目环境为webpack+js