c语言语音识别技术
 社区干货
社区干货
智能语音技术在字节跳动内容平台的演进和应用实践
通过无监督预训练 + 少量有监督的技术,参加国际低资源多语言语音识别挑战赛(MUCS21),取得多语言语音识别赛道第二名;音 **乐技术** 方面,我们参加了 MIREX2020 翻唱识别竞赛,取得第一名,mAP 领先第二名 8%; **语音合成** 上,我们发表了业界首个基于 seq2seq 链路的中文歌唱合成系统 ByteSing 以及搭建了 seq2seq 的中文前端多任务模型并用于线上业务。**InfoQ:端到端语音识别时代已来临,端到端识别技术近些年成为了学术界和...
技术人的 2023 漫谈 AI 语音体验之路|社区征文
# 目录- **谷歌的"谷歌文档语音输入"**- **小米的小爱同学**- **百度的“百度翻译”**- **苹果的“Siri”*** * *# 引言在这个时代,人工智能(AI)和音视频技术的深度融合成为一场科技变革的焦点。通过对AI与音视频的使用体验,我深刻感受到了这场变革所带来的深远影响。在过去的几年中,AI技术的进步为音视频领域注入了前所未有的活力。随着深度学习等技术的崛起,我们目睹了语音识别、人脸识别、自然语言处理等领...
vue3+vite+ts项目集成科大讯飞语音识别|社区征文
APISecret、APIkey,在项目中会用到这三个参数,新用户有500条免费的服务量。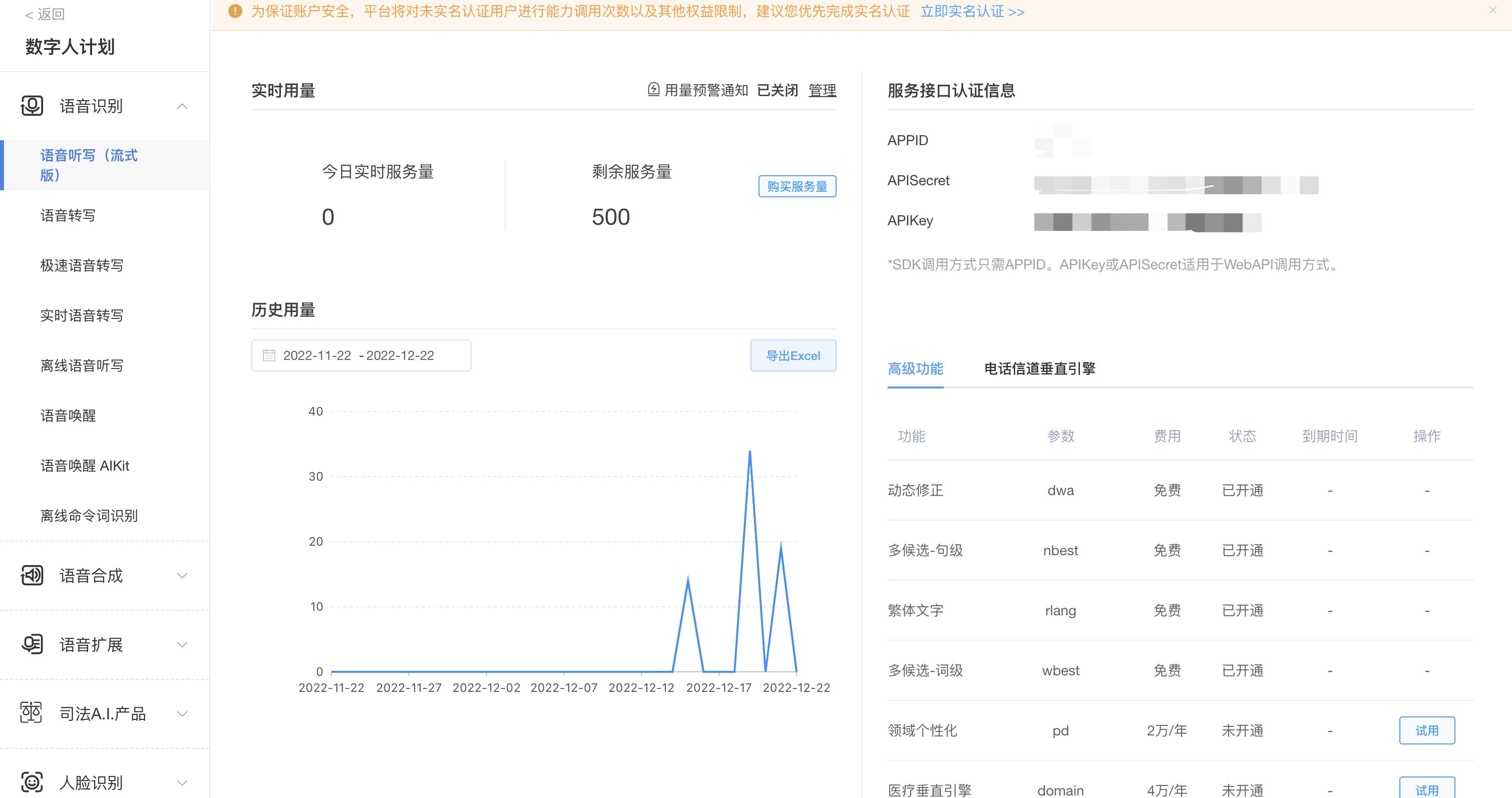## 三、下载语音识别demo[科大讯飞文档中心](https://www.xfyun.cn/doc/asr/voicedictation/API.html#%E6%8E%A5%E5%8F%A3%E8%AF%B4%E6%98%8E)中示例demo,博主选择的是js语言,注意该demo项目环境为webpack+js 特惠活动
特惠活动
 c语言语音识别技术-优选内容
c语言语音识别技术-优选内容
 c语言语音识别技术-相关内容
c语言语音识别技术-相关内容
调用流程
初始化 环境依赖创建流式语音识别 SDK 引擎实例前调用,完成网络环境等相关依赖配置。本方法每个进程生命周期内仅需调用一次。 java int ret = SpeechEngineGenerator.prepareEnvironment();if (ret != SpeechEngin... 会导致技术人员无法还原问题发生时的现场状况,从而难以定位、解决问题。 配置方法如下: java speechEngine.setOptionString(SpeechEngineDefines.PARAMS_KEY_UID_STRING, "{UID}");鉴权请先到火山控制台申请 Appid...
语音识别-火山引擎
语音识别基于深度学习技术,将音频中的语音转成文字。可用于识别多种音频编码格式、多种场景和不同长短的语音。广泛应用于呼叫中心录音质检、会议内容总结、音频内容分析、课堂内容分析等场景
模型效果FAQ
录音文件转写的效果要优于流式语音识别。 Q:如何优化指定业务场景的识别准确率?A:可以通过以下两种方案优化指定场景的识别准确率。 方案一:添加热词优化 如果您的识别结果中存在部分词汇识别效果不好的情况,可考虑通过添加热词,提高该类词语的识别效果。您可以在 控制台-语音技术-自学习平台-热词管理中自主添加、使用、管理热词。详细使用方法可见:自学习平台-热词 方案二:语言模型优化 若您已添加热词,但仍对识别效果不满意,且...
语音识别-本地化部署方案
让先进的语音识别技术摆脱云端依赖,为您快速提供私有化语音识别能力。支持本地部署和云端部署多种形式,广泛适用于呼叫中心质检、智能会议记录等多种使用场景。数据更安全,使用更放心
【流式语音识别SDK】隐私政策
发布日期:2023年【10】月【24】日生效日期:2023年【10】月【24】日 作为【流式语音识别SDK】产品/服务的提供方,北京火山引擎科技有限公司及其关联公司北京抖音信息服务有限公司(以下简称“我们”)高度重视个人信息... 我们采集的信息不能单独识别特定自然人的身份,并且基于本SDK的技术特性,其在运行过程客观上无法获取任何能够单独识别特定自然人身份的信息。我们可能会对【流式语音识别SDK】的功能和提供的服务有所调整变化,但请您...
产品计费
语音识别目前提供以下三种类型服务: 一句话识别 流式语音识别 录音文件识别 计费模式 试用额度语音识别提供一定量的试用额度,试用额度的用量、可使用范围、有效期等详情以控制台领取页面显示为准。试用额度在额... 默认并发 并发扩容 500 1年 1500 3 默认10路并发 100元/路/月 1000 2200 2.2 10000 16000 1.6 100000 130000 1.3 500000 500000 1 说明: QPS: QPS (query per second) 是一秒内查询服务接口的次数。 并发:并发数...
调用流程
初始化 环境依赖创建语音识别 SDK 引擎实例前调用,完成网络环境等相关依赖配置。 Java SpeechEngineGenerator.PrepareEnvironment(getApplicationContext(), getApplication());创建引擎实例语音识别 SDK ,通过如下方式获取相关实例。 Java SpeechEngine engine = SpeechEngineGenerator.getInstance();long engineHandler = engine.createEngine();参数配置引擎类型Java engine.setOptionString(SpeechEngineDefines.PARAMS_KEY...
智能语音技术在字节跳动内容平台的演进和应用实践
通过无监督预训练 + 少量有监督的技术,参加国际低资源多语言语音识别挑战赛(MUCS21),取得多语言语音识别赛道第二名;音 **乐技术** 方面,我们参加了 MIREX2020 翻唱识别竞赛,取得第一名,mAP 领先第二名 8%; **语音合成** 上,我们发表了业界首个基于 seq2seq 链路的中文歌唱合成系统 ByteSing 以及搭建了 seq2seq 的中文前端多任务模型并用于线上业务。**InfoQ:端到端语音识别时代已来临,端到端识别技术近些年成为了学术界和...
调用流程
前置操作 环境依赖创建语音识别 SDK 引擎实例前调用,完成网络环境等相关依赖配置。 Java SpeechEngineGenerator.PrepareEnvironment(getApplicationContext(), getApplication());创建引擎实例语音识别 SDK ,通过如下方式获取相关实例。 Java SpeechEngine engine = SpeechEngineGenerator.getInstance();long engineHandler = engine.createEngine();参数配置引擎类型Java engine.setOptionString(engineHandler, SpeechEngineD...
