庭审语音识别
 社区干货
社区干货
技术人的 2023 总结之无处不在的 AI|社区征文
再比如说 智能语音交互(Intelligent Speech Interaction),就是你所理解的基于语音识别、语音合成、自然语言理解等技术,对于企业来说适用于智能问答、智能质检、法庭庭审实时记录、实时演讲字幕、访谈录音转写等场景,可以应用在金融、司法、电商等多个领域,这里对于自然语言理解以及智能相关,也正是 AI 的特点。再比如 人机协同翻译,基于客户不断累积数据智能训练最合适客户的机器翻译模型,持续提高客户人工翻译效率,不是简单的...
vue3+vite+ts项目集成科大讯飞语音识别|社区征文
## 背景本人最近在做数字人项目,用到科大讯飞的语音识别功能,遇到了许多坑,做个总结,给兄弟们铺铺路。[科大讯飞语音识别](https://www.xfyun.cn/services/voicedictation)主要通过识别声音然后转换成文字,具体展示如下图所示:## 一、项目环境vue3+ts+vite## 二、注册科大讯飞注册后新建个应...
技术人的 2023 漫谈 AI 语音体验之路|社区征文
# 目录- **谷歌的"谷歌文档语音输入"**- **小米的小爱同学**- **百度的“百度翻译”**- **苹果的“Siri”*** * *# 引言在这个时代,人工智能(AI)和音视频技术的深度融合成为一场科技变革的焦点。通过对AI与音视频的使用体验,我深刻感受到了这场变革所带来的深远影响。在过去的几年中,AI技术的进步为音视频领域注入了前所未有的活力。随着深度学习等技术的崛起,我们目睹了语音识别、人脸识别、自然语言处理等领...
WebRTC 流媒体常见开源方案综述 | 社区征文
增强现实和语音分析。 Kurento 模块化架构简化了第三方媒体处理算法(即语音识别、情感分析、面部识别等)的集成,这些功能都可以作为 Kurento 的可选内置特性存在,非常方便。###### 架构图解Kurento 非常经典的架构图如下图所示: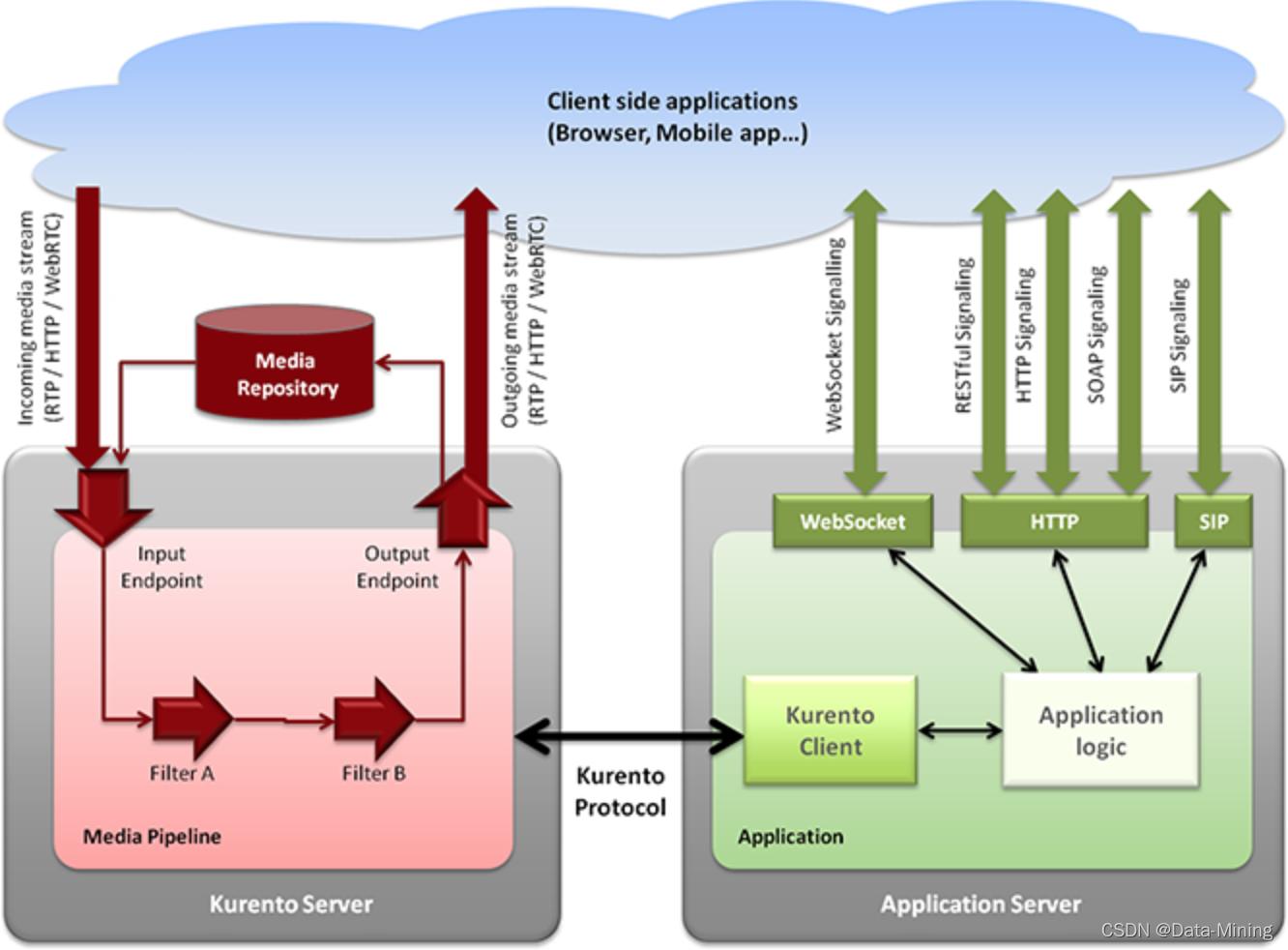### 发展现状最近整体上,Kurento 活跃度呈下降趋势。原因可...
 特惠活动
特惠活动
 庭审语音识别-优选内容
庭审语音识别-优选内容
 庭审语音识别-相关内容
庭审语音识别-相关内容
实时语音识别 ASR
在 RTC 通信时,如果你希望自动识别语音并转换为文本,可以使用实时语音识别(Automatic Speech Recognition) 相关接口实现。 功能详情在客户端 SDK 开启 ASR 能力后,你可以在 RTC 的回调中实时获取语音识别的文本结果。 功能变更日志自客户端 SDK 3.25 起,ASR 的功能可用。 功能边界无论音频输入是通过 RTC 内部音频采集还是自定义音频采集,都可以使用 RTC 集成的 ASR 能力。 不同场景下语音识别的效果以及对输入语音和输出语言的支...
产品概述
产品简介语音识别(Automatic Speech Recognition,ASR)采用业内领先的端到端算法模型,准确地将语音内容转写成文字。产品支持时间戳,区分讲话人,数字格式智能转换,智能标点等功能。适用于录音质检、会议总结、音频内容分析、课堂内容分析等场景。 一句话识别 支持将短语音(≤60秒)实时识别成文字,达到“边说话边出文字”的效果。适用于音频小于60秒,需要实时出结果的场景,如语音消息转写、语音搜索、语音弹幕、语音评论、智能语音交...
SDK概览
欢迎使用火山引擎!本文档主要面向首次使用 流式语音识别SDK 的新用户,方便您快速了解产品并用于实践。注:一句话识别组件和流式识别组件已于2023.9.15合并,当前流式语音识别SDK也可同时支持一句话场景。 SDK名称:流式语音识别SDK SDK开发者:北京火山引擎科技有限公司 主要功能:流式语音识别SDK支持将音频实时识别成文字,达到“边说话边出文字”的效果,适用于实时语音识别的场景,如实时会议字幕、直播字幕、智能外呼等等。 SDK接入...
vue3+vite+ts项目集成科大讯飞语音识别|社区征文
## 背景本人最近在做数字人项目,用到科大讯飞的语音识别功能,遇到了许多坑,做个总结,给兄弟们铺铺路。[科大讯飞语音识别](https://www.xfyun.cn/services/voicedictation)主要通过识别声音然后转换成文字,具体展示如下图所示:## 一、项目环境vue3+ts+vite## 二、注册科大讯飞注册后新建个应...
客户端 SDK
SubscribeAllStreams UnsubscribeAllStreams 范围语音 增加音量衰减模式的选择接口,可根据场景需要,选择音量根据距离线性衰减或非线形衰减。音量随距离增大进行非线性衰减更符合真实世界中声音的表现。 支持... 可对房间内说话人的语音进行识别,转成文字或者进行翻译。使用该功能前,你需要开通机器翻译服务并前往 RTC 控制台,在功能配置页面开启字幕功能。接口参看: 平台 Android iOS macOS Windows Linux Electron 接口 st...
语音技术-火山引擎
基于业界领先的语音识别、语音合成、自然语言理解等技术,广泛应用于智能客服、小说阅读、在线教育、会议纪要、视频字幕等多个企业应用场景,赋能开发者,让您的产品能“听”会“说”
集成指南
data 文件夹: asr_rec_file.pcm:一句话识别测试音频文件,16k采样频率、16bit采样位数、单通道PCM文件。 asr_long_rec_file.pcm:流式语音识别测试音频文件,16k采样频率、16bit采样位数、单通道PCM文件。 include 文件夹:SDK 头文件,和对应版本SDK包一致。 lib 文件夹:SDK 动态库,和对应版本SDK包一致。 models 文件夹:模型资源文件夹,与对应版本的模型资源一致。 src 文件夹:Demo 源代码。 asr.cc:音频数据来源为File的一...
调用流程
初始化 环境依赖创建流式语音识别 SDK 引擎实例前调用,完成网络环境等相关依赖配置。本方法每个进程生命周期内仅需调用一次。 java int ret = SpeechEngineGenerator.prepareEnvironment();if (ret != SpeechEngineDefines.ERR_NO_ERROR) { System.out.println("Prepare Environment Failed: " + ret); return;}创建引擎实例流式语音识别 SDK 通过如下方式获取相关实例。每个实例在某一时刻只能处理一次识别任务,如需同时处...
调用流程
初始化 环境依赖创建流式语音识别 SDK 引擎实例前调用,完成网络环境等相关依赖配置。本方法每个进程生命周期内仅需调用一次。 cpp int ret = SpeechSDK_PrepareEnvironment();if (ret) { std::cout << "Fail to prepare engine environment!" < speechEngine.setOptionString(SpeechEngineDefines.OPTIONS_KEY_ASR_RESULT_TYPE_STRING, SpeechEngineDefines.ASR_RESULT_TYPE_SINGLE);一句话场景下可以选用全量返回模式: cpp /...
