代码如何在cuda上运行
 社区干货
社区干货
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 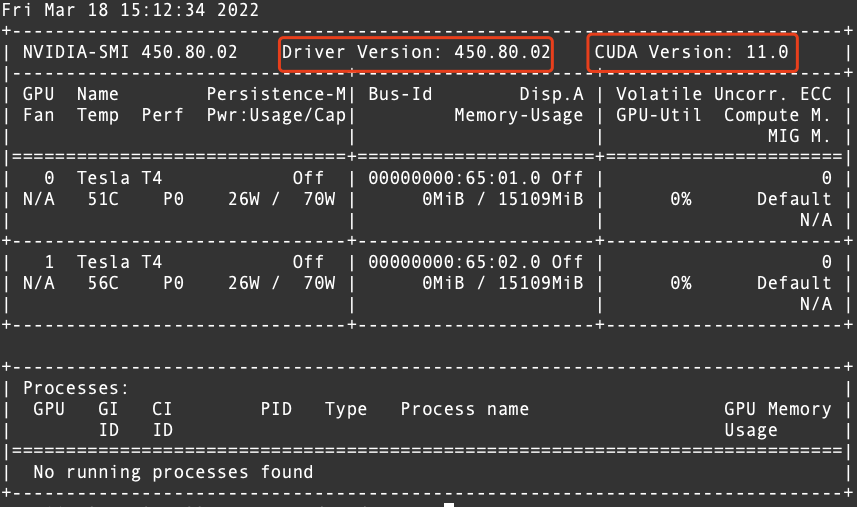 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
GPU推理服务性能优化之路
CUDA的架构中引入了主机端(host, cpu)和设备(device, gpu)的概念。CUDA的Kernel函数既可以运行在主机端,也可以运行在设备端。同时主机端与设备端之间可以进行数据拷贝。CUDA Kernel函数:是数据并行处理函数(核函数),在GPU上执行时,一个Kernel对应一个Grid,基于GPU逻辑架构分发成众多thread去并行执行。CUDA Stream流:Cuda stream是指一堆异步的cuda操作,他们按照host代码调用的顺序执行在device上。典型的CUDA代码执行流程...
【发布】代码模型 CodeGeeX2-6B 开源,最低6GB显存,性能优于StarCoder
**「代码生成模型 CodeGeeX2-6B」****开源**。同时我们也将对该模型持续进行迭代升级,以提供更加强大的代码辅助能力。CodeGeeX2 是多语言代码生成模型 CodeGeeX 的第二代模型,基于 ChatGLM2 架构注入代码实现... 量化后仅需6GB显存即可运行,支持轻量级本地化部署。**更全面的AI编程助手:**CodeGeeX插件(VS Code, Jetbrains)后端升级,支持超过100种编程语言,新增上下文补全、跨文件补全等实用功能。结合 Ask CodeGeeX 交互...
【高效视频处理】体验火山引擎多媒体处理框架 BMF |社区征文
在我的机器上,CUDA 和 cuDNN 的版本与 BMF 的要求不一致。解决方法:通过更新 GPU 驱动、安装适配版本的 CUDA 和 cuDNN,我成功将系统环境调整到与 BMF 兼容的状态。这一步骤对于保证 GPU 加速的正常运行非常关键。... 特别是在处理高分辨率视频和大规模视频数据集时,GPU 加速体现出了它的强大性能。- 编写支持 GPU 加速的代码——BMF 提供了与 GPU 加速兼容的 API,使得开发人员可以轻松地利用 GPU 加速的优势。在我的体验中,我编...
 特惠活动
特惠活动
 代码如何在cuda上运行-优选内容
代码如何在cuda上运行-优选内容
 代码如何在cuda上运行-相关内容
代码如何在cuda上运行-相关内容
【发布】代码模型 CodeGeeX2-6B 开源,最低6GB显存,性能优于StarCoder
**「代码生成模型 CodeGeeX2-6B」****开源**。同时我们也将对该模型持续进行迭代升级,以提供更加强大的代码辅助能力。CodeGeeX2 是多语言代码生成模型 CodeGeeX 的第二代模型,基于 ChatGLM2 架构注入代码实现... 量化后仅需6GB显存即可运行,支持轻量级本地化部署。**更全面的AI编程助手:**CodeGeeX插件(VS Code, Jetbrains)后端升级,支持超过100种编程语言,新增上下文补全、跨文件补全等实用功能。结合 Ask CodeGeeX 交互...
【高效视频处理】体验火山引擎多媒体处理框架 BMF |社区征文
在我的机器上,CUDA 和 cuDNN 的版本与 BMF 的要求不一致。解决方法:通过更新 GPU 驱动、安装适配版本的 CUDA 和 cuDNN,我成功将系统环境调整到与 BMF 兼容的状态。这一步骤对于保证 GPU 加速的正常运行非常关键。... 特别是在处理高分辨率视频和大规模视频数据集时,GPU 加速体现出了它的强大性能。- 编写支持 GPU 加速的代码——BMF 提供了与 GPU 加速兼容的 API,使得开发人员可以轻松地利用 GPU 加速的优势。在我的体验中,我编...
GPU-部署基于DeepSpeed-Chat的行业大模型
本文以搭载了一张A100显卡的ecs.pni2.3xlarge为例,介绍如何在GPU云服务器上进行DeepSpeed-Chat模型的微调训练。 背景信息DeepSpeed-Chat简介 DeepSpeed-Chat是微软新公布的用来训练类ChatGPT模型的一套代码,该套代... 微调的优点在于节省时间和资源,提高性能,适用于数据受限或计算资源有限的情况。 通过在特定领域的数据上进行微调,模型可以逐渐学习到特定领域的特征和模式,从而提高在该领域的性能和泛化能力。 软件要求CUDA:使GPU...
HPC裸金属-基于NCCL的单机/多机RDMA网络性能测试
本文介绍如何在虚拟环境或容器环境中,使用NCCL测试ebmhpcpni2l实例的RDMA网络性能。 背景信息ebmhpcpni2l实例搭载NVIDIA A800显卡,同时支持800Gbps RDMA高速网络,大幅提升集群通信性能,提高大规模训练加速比。更多... 可以用来评估NCCL的运行性能和正确性。 OFED MLNX OFED(OpenFabrics Enterprise Distribution)是一组开源软件驱动、核心内核代码、中间件和支持InfiniBand Fabric的用户级接口程序,用于监视InfiniBand网络的运行情...
【发布】LongBench:衡量模型的「长」
2 个代码任务。多数任务的平均长度在5k-15k之间,共包含约4500条测试数据。从主要任务分类上,LongBench包含单文档QA、多文档QA、摘要、Few-shot学习、代码补全和合成任务等六大类任务 20 个不同子... 我们以ChatGLM2-6B为例提供了一份评测代码。首先,运行仓库下的pred.py``` `CUDA\_VISIBLE\_DEVICES=0 python pred.py` ```可以在`pred/`文件夹下得到模型在所有数据集下的输出,此...
GPU-基于Diffusers和Gradio搭建SDXL推理应用
本文以搭载了一张V100显卡的ecs.g1ve.2xlarge实例,介绍如何在GPU云服务器上基于Diffusers搭建SDXL 1.0的base + refiner组合模型。 背景信息SDXL Stable Diffusion XL(简称SDXL)是最新的图像生成模型,与之前的SD模型... Pytorch使用CUDA进行GPU加速时,在GPU驱动已经安装的情况下,依然不能使用,很可能是版本不匹配的问题,请严格关注虚拟环境中CUDA与Pytorch的版本匹配情况。 Anaconda:获取包且对包能够进行管理的工具,包含了Conda、P...
火山引擎部署ChatGLM-6B实战指导
在实例类型中,选择GPU计算型,可以看到有A30、A10、V100等GPU显卡的ECS云主机,操作系统镜像选择Ubuntu 带GPU驱动的镜像,火山引擎默认提供的GPU驱动版本为CUDA11.3,如果需要升级版本的话可以参考后面的步骤,配置GP... 从英伟达官网https://developer.nvidia.com/cuda-downloads下载所需版本的CUDA工具包到ECS本地云盘中的某个文件中,工具下载页面会自动生成下载和安装运行命令,下图下载了11.6版本的cuda_11.6.0_510.39.01_linux....
通过工作流串联训练与评测任务
并在训练结束将模型文件存储到TOS。然后拉起一个单机CPU任务,读取训练好的模型文件,在测试数据集上进行模型效果的评估。 开发训练与评估代码 假设用户已在开发机或本地电脑内编写好模型的训练与评估代码。如下是一... args = parser.parse_args() device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') print(f"use device={device}, local_rank={args.local_rank}") if args.local_rank >= 0: ...
内置应用:GPT代码执行器(code interpreter)上线,写代码,执行代码,轻松搞定
[picture.image](https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/f06013dc124a4c99b4d6b9eba1d53ca7~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1715012425&x-signature=w4WZig0DrfXQ6LAH7HCErn4h9Eg%3D) **什么是GPT代码执行器(Code Interpreter)**GPT代码执行器赋予了语言模型运行Python代码的能力,用户只需用自然语言告诉模型任务是什么,模型就能编写相对应的P...
