索尼电脑nvidiacuda
 社区干货
社区干货
nvidia-cuda镜像
## 简介CUDA-X AI 是软件加速库的集合,这些库建立在 CUDA® (NVIDIA 的开创性并行编程模型)之上,提供对于深度学习、机器学习和高性能计算 (HPC) 必不可少的优化功能。下载地址:- 火山引擎访问地址:https://mirrors.ivolces.com/nvidia_all/- 公网访问地址:https://mirrors.volces.com/nvidia_all/## 相关链接官方主页:[https://www.nvidia.cn/technologies/cuda-x/](https://www.nvidia.cn/technologies/cuda-x/?spm=a...
Docker容器中使用GPU资源
# 问题描述在安装了 Nvidia驱动和docker的主机上直接启动容器报错提示如下信息:```shelldocker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smidocker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].```# 问题分析需要安装nvidia-docker2或nvidia-container-runtime插件驱动,以便docker容器能够使用Nvidia驱动。# 问题解决## 一、安装nvidia-docker21.设置仓库和...
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 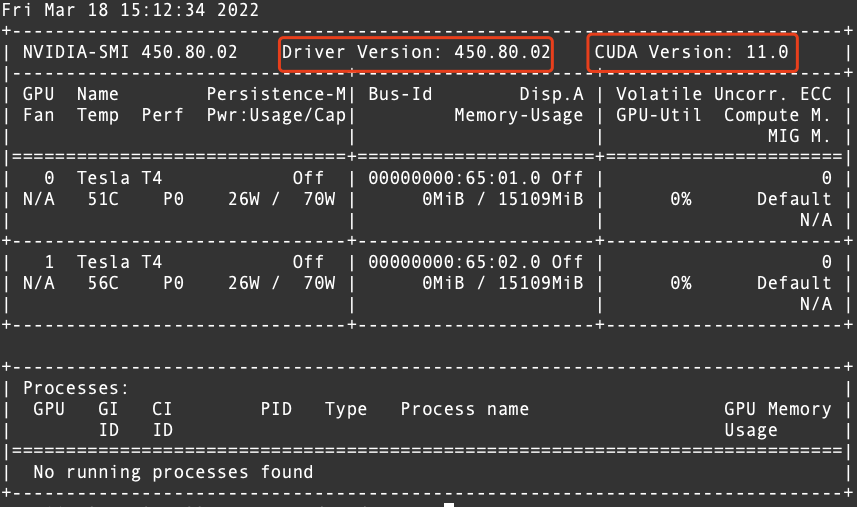 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
如何在Docker容器中使用GPU资源
# 问题描述在安装了 Nvidia 驱动和 docker 的主机上直接启动容器报错提示如下信息:```shelldocker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smidocker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].```# 问题分析需要安装 nvidia-docker2 或 nvidia-container-runtime 插件驱动,以便 docker 容器能够使用 Nvidia 驱动。# 问题解决## 一、安装nvidia-docker2...
 特惠活动
特惠活动
 索尼电脑nvidiacuda-优选内容
索尼电脑nvidiacuda-优选内容
 索尼电脑nvidiacuda-相关内容
索尼电脑nvidiacuda-相关内容
VirtualBox制作ubuntu14镜像
实验介绍CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。 Pytorch使用CUDA进行GPU加速时,在CUDA、GPU驱动已经安装的情况下,依然不能使用,很可能是版本不匹配的问题。本文从GPU驱动开始从头彻底解决版本不匹配问题。 关于实验级别:初级 相关产品:云服务器镜像,TOS桶 受众:通用 操作系...
NVIDIA驱动FAQ
请参考安装GPU驱动和安装CUDA工具包手动安装GPU驱动。 Nvidia驱动安装成功,但执行nvidia-smi命令无效,显示驱动未安装,该如何排查?问题分析:可能是kernel-devel和kernel版本不一致,导致在安装RPM包过程中驱动程序编译出错。 解决方案:在实例内运行rpm -qa grep $(uname -r)命令查看kernel和kernel-devel的版本号,检测版本是否一致。若不一致,请从正规渠道下载对应的kernel-devel包,再重新安装驱动。 执行nvidia-smi命令查看的CU...
安装NVIDIA-Fabric Manager软件包
操作场景NVIDIA-Fabric Manager服务可以使多A100/A800显卡间通过NVSwitch互联。有关NVSwitch的更多介绍,请参见NVIDIA官网。 说明 搭载A100/A800显卡的实例请参见实例规格介绍,如果未安装与GPU驱动版本对应的NVIDIA... 您可以执行nvidia-smi命令,查看GPU驱动版本。 方式一:通过安装包安装CentOS 8.x wget https://developer.download.nvidia.cn/compute/cuda/repos/rhel8/x86_64/nvidia-fabric-manager-470.57.02-1.x86_64.rpmrpm -...
常见 Xid 事件的处理方法
Xid 消息是 NVIDIA 驱动程序向操作系统的内核日志或事件日志打印的错误报告。Xid 消息表明发生了一般的 GPU 错误,通常是由于驱动程序错误地编程或者发送给 GPU 的命令被损坏所导致的。GPU 硬件、NVIDIA 软件或者用... due to previous errors -- Most likely to see when running multiple cuda applications and hitting a DBE。通常是用户手动退出或者其他故障(硬件、资源限制等)导致 GPU 应用退出,Xid 45 只是一个结果,通常需要...
GPU-部署NGC环境
本文介绍如何在Linux实例上基于NGC部署TensorFlow。 NGC介绍NGC(NVIDIA GPU CLOUD)是NVIDIA开发的一套深度学习容器库,具有强大的性能和良好的灵活性,可以帮助科学家和研究人员快速构建、训练和部署神经网络模型。NGC官网提供了当前主流深度学习框架的镜像,例如Caffe、TensorFlow、Theano、Torch等。 软件版本操作系统:本文以Ubuntu 18.04为例。 NVIDIA驱动:GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以470.57.02为例。 CUDA:使GP...
Docker容器中使用GPU资源
# 问题描述在安装了 Nvidia驱动和docker的主机上直接启动容器报错提示如下信息:```shelldocker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smidocker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].```# 问题分析需要安装nvidia-docker2或nvidia-container-runtime插件驱动,以便docker容器能够使用Nvidia驱动。# 问题解决## 一、安装nvidia-docker21.设置仓库和...
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。  从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
安装GPU驱动
对NVIDIA Tesla系列的GPU而言,有以下两个层次的软件包需要安装: 驱动GPU工作的硬件驱动程序。 上层应用程序所需要的库。 在通用计算场景下,如深度学习、AI等通用计算业务场景或者OpenGL、Direct3D、云游戏等图形加速场景,安装了Tesla驱动的GPU才可以发挥高性能计算能力,或提供更流畅的图形显示效果。 操作场景如果您在创建GPU实例时未同时安装Tesla驱动,则需要在创建GPU实例后,参考本文和安装CUDA工具包手动安装Tesla驱动。 说明...
如何在Docker容器中使用GPU资源
# 问题描述在安装了 Nvidia 驱动和 docker 的主机上直接启动容器报错提示如下信息:```shelldocker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smidocker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].```# 问题分析需要安装 nvidia-docker2 或 nvidia-container-runtime 插件驱动,以便 docker 容器能够使用 Nvidia 驱动。# 问题解决## 一、安装nvidia-docker2...
