怎么使用cuda代码
 社区干货
社区干货
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 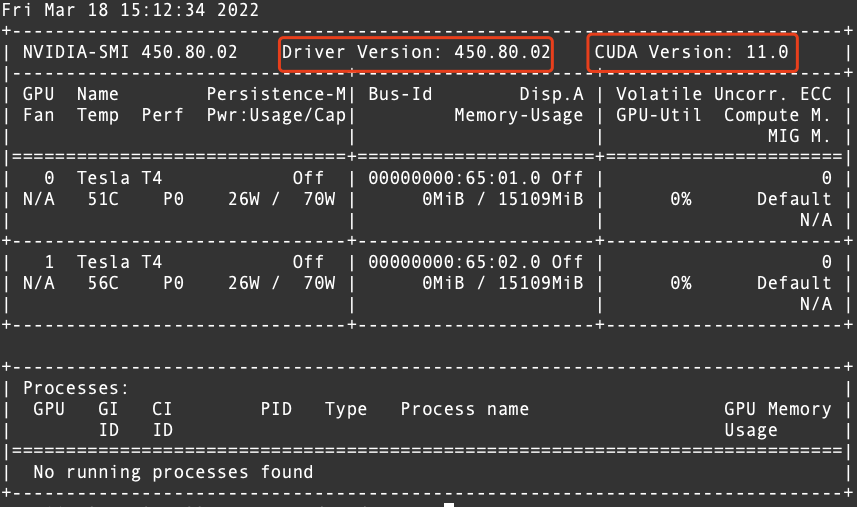 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
GPU推理服务性能优化之路
CUDA的架构中引入了主机端(host, cpu)和设备(device, gpu)的概念。CUDA的Kernel函数既可以运行在主机端,也可以运行在设备端。同时主机端与设备端之间可以进行数据拷贝。CUDA Kernel函数:是数据并行处理函数(核函数),在GPU上执行时,一个Kernel对应一个Grid,基于GPU逻辑架构分发成众多thread去并行执行。CUDA Stream流:Cuda stream是指一堆异步的cuda操作,他们按照host代码调用的顺序执行在device上。典型的CUDA代码执行流程...
如何在Docker容器中使用GPU资源
docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smidocker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].```# 问题分析需要安装 nvidia-docker2 或 nvidia-container-runtime 插件驱动,以便 docker 容器能够使用 Nvidia 驱动。# 问题解决## 一、安装nvidia-docker21. 设置仓库和 GPGkey```shelldistribution=$(. /etc/os-release;echo $ID$VERSION_ID)c...
【高效视频处理】体验火山引擎多媒体处理框架 BMF |社区征文
确保系统环境中已经安装了必要的 GPU 驱动和 CUDA 工具包,这对于 BMF 的 GPU 加速至关重要。- Windows 平台——虽然 Windows 不是 BMF 的主要开发平台,但在某些情况下需要在 Windows 环境中进行部署。我选择了一... 通过在模块中设置 `use_gpu=True` 参数,即可启用 GPU 加速。这里展示的是一个简单的例子,实际项目中,可以根据需求添加更多的处理模块,构建复杂的处理流程。BMF 提供了详细的文档和示例代码,方便开发人员更深入地理...
 特惠活动
特惠活动
 怎么使用cuda代码-优选内容
怎么使用cuda代码-优选内容
 怎么使用cuda代码-相关内容
怎么使用cuda代码-相关内容
GPU-基于Diffusers和Gradio搭建SDXL推理应用
Pytorch使用CUDA进行GPU加速时,在GPU驱动已经安装的情况下,依然不能使用,很可能是版本不匹配的问题,请严格关注虚拟环境中CUDA与Pytorch的版本匹配情况。 Anaconda:获取包且对包能够进行管理的工具,包含了Conda、P... 将使用默认设置,包括安装路径(/root/anaconda3)和环境变量设置。如果您需要自定义这些设置,请使用交互式安装程序。 bash Anaconda3-2022.05-Linux-x86_64.sh -b -p /root/anaconda3 安装完成后执行以下命令,初始化...
如何在Docker容器中使用GPU资源
docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smidocker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].```# 问题分析需要安装 nvidia-docker2 或 nvidia-container-runtime 插件驱动,以便 docker 容器能够使用 Nvidia 驱动。# 问题解决## 一、安装nvidia-docker21. 设置仓库和 GPGkey```shelldistribution=$(. /etc/os-release;echo $ID$VERSION_ID)c...
【高效视频处理】体验火山引擎多媒体处理框架 BMF |社区征文
确保系统环境中已经安装了必要的 GPU 驱动和 CUDA 工具包,这对于 BMF 的 GPU 加速至关重要。- Windows 平台——虽然 Windows 不是 BMF 的主要开发平台,但在某些情况下需要在 Windows 环境中进行部署。我选择了一... 通过在模块中设置 `use_gpu=True` 参数,即可启用 GPU 加速。这里展示的是一个简单的例子,实际项目中,可以根据需求添加更多的处理模块,构建复杂的处理流程。BMF 提供了详细的文档和示例代码,方便开发人员更深入地理...
HPC裸金属-基于NCCL的单机/多机RDMA网络性能测试
CUDA工具包:使GPU能够解决复杂计算问题的计算平台。 cuDNN库:NVIDIA CUDA(®) 深度神经网络库,用于实现高性能GPU加速。 OpenMPI OpenMPI是一个开源的 Message Passing Interface 实现,是一种高性能消息传递库... 核心内核代码、中间件和支持InfiniBand Fabric的用户级接口程序,用于监视InfiniBand网络的运行情况,包括监视传输带宽和监视Fabric内部的拥塞情况。 前提条件您已购买两台ebmhpcpni2l实例,并勾选“后台自动安装GPU驱...
GPU服务器使用
步骤2:安装CUDA Toolkit具体安装步骤请参英伟达CUDA安装说明 步骤3:安装GPU_BURNGPU_BURN下载以及使用方法参考文档GPU_BURN下载以及使用方法 安装GPU_BURN,使用如下命令。 bash tar zxvf gpu_burn-1.1.tar.gz 编辑Makefile,CUDAPATH=/usr/local/cuda这里需要更改为自己安装cuda的位置即可,删除-arch=compute_30。编辑后的配置文件如图所示。 执行make命令,生成gpu_burn可执行文件,具体如图所示。 步骤4:使用GPU_BURN对GPU卡进行...
Docker容器中使用GPU资源
# 问题描述在安装了 Nvidia驱动和docker的主机上直接启动容器报错提示如下信息:```shelldocker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smidocker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].```# 问题分析需要安装nvidia-docker2或nvidia-container-runtime插件驱动,以便docker容器能够使用Nvidia驱动。# 问题解决## 一、安装nvidia-docker21.设置仓库和...
通过工作流串联训练与评测任务
该工作流使用PytorchDDP框架拉起一个多机GPU训练任务,并在训练结束将模型文件存储到TOS。然后拉起一个单机CPU任务,读取训练好的模型文件,在测试数据集上进行模型效果的评估。 开发训练与评估代码 假设用户已在开发... args = parser.parse_args() device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') print(f"use device={device}, local_rank={args.local_rank}") if args.local_rank >= 0: ...
GPU在Kubernetes中的使用与管理 | 社区征文
对于GPU资源只能设置`limit`,这意味着`requests`不可以单独使用,要么只设置`limit`、要么同时设置二者,但二者值必须相等,不可以只设置`request`而不设置`limit`。- pod及容器之间,不可以共享GPU,且GPU也不可... 它使用我们刚说到的`扩展资源`资源字段来传递GPU信息,下面是官方给出的声明使用nvidia硬件的示例:```apiVersion: v1kind: Podmetadata: name: cuda-vector-addspec: restartPolicy: OnFailure contai...
GPU-部署基于DeepSpeed-Chat的行业大模型
安装git并克隆DeepSpeed官方示例代码。 conda install gitgit clone https://github.com/microsoft/DeepSpeedExamples.git 依次执行以下命令,安装相应的依赖包。 cd DeepSpeedExamples/applications/DeepSpeed-Chat/pip3 install -r requirements.txt 执行以下命令,验证环境是否可用。 python>>>import torch>>>torch.cuda.is_available()回显为True,表示环境正常可用。输入exit()退出当前环境。 步骤二:选择预训练模型并整理数...
