剩余的cuda
 社区干货
社区干货
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 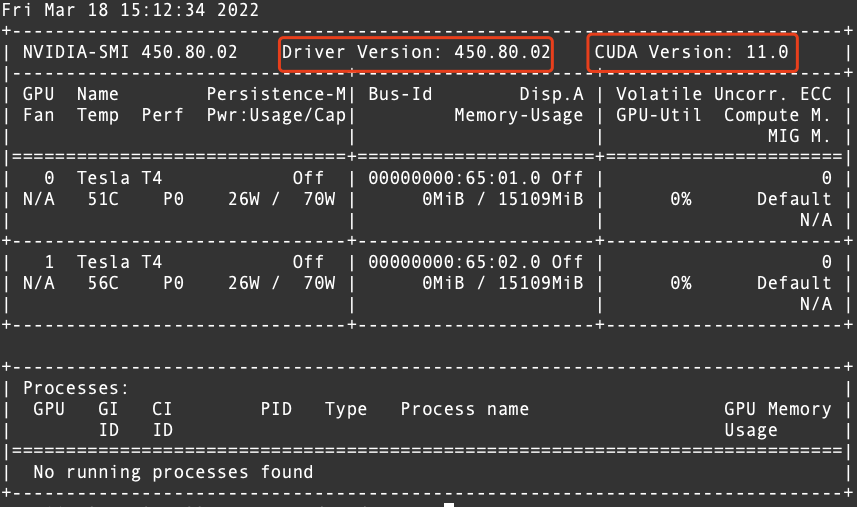 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
nvidia-cuda镜像
## 简介CUDA-X AI 是软件加速库的集合,这些库建立在 CUDA® (NVIDIA 的开创性并行编程模型)之上,提供对于深度学习、机器学习和高性能计算 (HPC) 必不可少的优化功能。下载地址:- 火山引擎访问地址:https://mirrors.ivolces.com/nvidia_all/- 公网访问地址:https://mirrors.volces.com/nvidia_all/## 相关链接官方主页:[https://www.nvidia.cn/technologies/cuda-x/](https://www.nvidia.cn/technologies/cuda-x/?spm=a...
GPU推理服务性能优化之路
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。CUDA的架构中引入了主机端(host, cpu)和设备(device, gpu)的概念。CUDA的Kernel函数既可以运行在主机端,也可以运行在设备端。同时主机端与设备端之间可以进行数据拷贝。CUDA Kernel函数:是数据并行处理函数(核函数),在GPU上执行时,一个Kernel对应一个Grid,基于GPU逻辑架构分发成众多thread去并行执行。CUDA ...
GPU在Kubernetes中的使用与管理 | 社区征文
name: cuda-vector-addspec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile image: "k8s.gcr.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 # requesting 1 GPU```要想使用上面yaml文件声明使用GPU设备,那么需要先在Node节点上安装`设备插...
 特惠活动
特惠活动
 剩余的cuda-优选内容
剩余的cuda-优选内容
 剩余的cuda-相关内容
剩余的cuda-相关内容
nvidia-cuda镜像
## 简介CUDA-X AI 是软件加速库的集合,这些库建立在 CUDA® (NVIDIA 的开创性并行编程模型)之上,提供对于深度学习、机器学习和高性能计算 (HPC) 必不可少的优化功能。下载地址:- 火山引擎访问地址:https://mirrors.ivolces.com/nvidia_all/- 公网访问地址:https://mirrors.volces.com/nvidia_all/## 相关链接官方主页:[https://www.nvidia.cn/technologies/cuda-x/](https://www.nvidia.cn/technologies/cuda-x/?spm=a...
GPU实例部署paddlepaddle-gpu环境
本文介绍 GPU 实例部署深度学习Paddle环境。 前言 在ECS GPU实例上部署深度学习Paddle环境。 关于实验 预计实验时间:20分钟级别:初级相关产品:ECS受众: 通用 环境说明 本文测试规格如下:实例规格:ecs.pni2.3xlargeGPU 类型:Tesla A100 80G显存容量:81920MiB实例镜像:velinux - 1.0 with GPU DriverNVIDIA-SMI:470.57.02NVIDIA Driver version:470.57.02CUDA version:11.4CUDA Toolkit version:11.2Python version:Python 3.7.3pa...
GPU推理服务性能优化之路
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。CUDA的架构中引入了主机端(host, cpu)和设备(device, gpu)的概念。CUDA的Kernel函数既可以运行在主机端,也可以运行在设备端。同时主机端与设备端之间可以进行数据拷贝。CUDA Kernel函数:是数据并行处理函数(核函数),在GPU上执行时,一个Kernel对应一个Grid,基于GPU逻辑架构分发成众多thread去并行执行。CUDA ...
GPU在Kubernetes中的使用与管理 | 社区征文
name: cuda-vector-addspec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile image: "k8s.gcr.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 # requesting 1 GPU```要想使用上面yaml文件声明使用GPU设备,那么需要先在Node节点上安装`设备插...
Spark on GPU 最佳实践
以及 udf 包含 cuda 计算、编码计算等场景,不太适合用于小数据量、重 io(包括 shuffle)、GPU 卡内存比较小,以及 udf 包含大量逻辑计算(与 cpu 频繁交互)的场景。 Spark Rapids 算子与原生算子之间存在一定程度的兼... 后续剩余集群创建步骤,详见创建集群。 4 Yarn 配置使用 Spark Rapids 仅需要对 Yarn 组件服务做出简单的配置即可。针对不同的硬件卡,Yarn 组件需要做出不同的配置: 普通不支持 Multi-Instance(mig) 的卡,使用 ...
GPU-部署Baichuan大语言模型
在权威的中文和英文 Benchmark 评测上均取得很好的效果。模型支持FP16、INT8、INT4三种精度,可以在GPU实例上部署并搭建推理应用。该模型对GPU显存的需求如下: 精度 显存需求 推荐实例规格 GPU显卡类型 FP16 27 GB ecs.g1ve.2xlarge V100 * 1(单卡32 GB显存) INT8 17 GB ecs.gni2.3xlarge A10 * 1(单卡24 GB显存) INT4 10 GB ecs.gni2.3xlarge A10 * 1(单卡24 GB显存) 软件要求注意 部署Baichuan大语言模型时,需保证CUDA版本 ≥ 1...
GPU-部署NGC环境
本文介绍如何在Linux实例上基于NGC部署TensorFlow。 NGC介绍NGC(NVIDIA GPU CLOUD)是NVIDIA开发的一套深度学习容器库,具有强大的性能和良好的灵活性,可以帮助科学家和研究人员快速构建、训练和部署神经网络模型。NGC官网提供了当前主流深度学习框架的镜像,例如Caffe、TensorFlow、Theano、Torch等。 软件版本操作系统:本文以Ubuntu 18.04为例。 NVIDIA驱动:GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以470.57.02为例。 CUDA:使GP...
GPU-部署ChatGLM-6B模型
支持在消费级的显卡上进行本地部署(INT4量化级别下最低只需6GB显存)。ChatGLM-6B使用了和ChatGLM相同的技术,针对中文问答和对话进行了优化。经过约1T标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62亿参数的ChatGLM-6B已经能生成相当符合人类偏好的回答。 软件要求注意 部署ChatGLM-6B语言模型时,需保证CUDA版本 ≥ 11.4。 NVIDIA驱动:GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以535.86.10为例...
卸载NVIDIA Tesla驱动
卸载NVIDIA Tesla驱动(Linux)注意事项卸载GPU驱动需要root账号操作权限,如果您是普通用户,请使用sudo命令获取root权限后再操作,本文以root登录系统操作为例。 卸载不同CUDA版本的命令可能不同,若不存在cuda-uninstaller文件, 请进入“/usr/local/cuda/bin/”目录查看是否存在uninstall_cuda开头的文件。若有,请将命令中的cuda-uninstaller替换为uninstall_cuda开头的文件名。 卸载run包方式安装的NVIDIA驱动登录Linux实例。 执...
