kafkacentos7
 社区干货
社区干货
聊聊 Kafka:Topic 创建流程与源码分析 | 社区征文
7Y%3D)为了使数据具有容错性和高可用性,每个主题都可以**复制**,甚至可以跨地理区域或数据中心**复制**,以便始终有多个代理拥有数据副本,以防万一出现问题。常见的生产设置是复制因子为 3,即,你的数据将始终存在三个副本。此复制在主题分区级别执行。在设置副本时,副本数是必须小于集群的 Broker 数的,副本只有设置在不同的机器上才有作用。## 二、Topic 的创建方式### 2.1 zookeeper 方式(不推荐)```./bin/kafka-top...
消息队列选型之 Kafka vs RabbitMQ
在面对众多的消息队列时,我们往往会陷入选择的困境:“消息队列那么多,该怎么选啊?Kafka 和 RabbitMQ 比较好用,用哪个更好呢?”想必大家也曾有过类似的疑问。对此本文将在接下来的内容中以 Kafka 和 RabbitMQ 为例分... (https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/1cc0603e317847c9b8d7f5e92b75924f~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716913234&x-signature=0Of0lMaLchQ47RrWFWeUxuYh...
Kafka数据同步
Kafka MirrorMaker 是 Kafka 官网提供的跨数据中心流数据同步方案,其实现原理是通过从 Source 集群消费消息,然后将消息生产到 Target 集群从而完成数据迁移操作。用户只需要通过简单的consumer配置和producer配置,启动MirrorMaker,即可实现实时数据同步。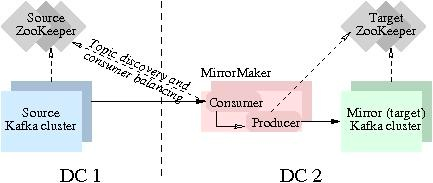本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流...
字节跳动新一代云原生消息队列实践
(https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/a125bf89b1f94fe5a2e492d89de7c6e7~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716913242&x-signature=l%2Faw41HNFzjkf4DIjJqKUQKCbuA%3D)从整体来看,BMQ 与 Kafka 架构最大的不同在于 BMQ 是 **存算分离的架构** ,相较于 Kafka 将数据存储在本地磁盘,BMQ 将数据存储在了分布式的存储系统。在 BMQ 内部,主要有四个模块:Proxy,Broker,Coord...
 特惠活动
特惠活动
 kafkacentos7-优选内容
kafkacentos7-优选内容
 kafkacentos7-相关内容
kafkacentos7-相关内容
通过 Kafka 消费火山引擎 Proto 格式的订阅数据
运行语言 说明 Go 通过代码示例中参数 config.Version 指定服务端 Kafka 版本号。 Python 通过示例代码中参数 api_version 指定服务端 Kafka 版本号。 Java 通过 maven pom.xml 文件中参数 version 指定服务端 Kafka 版本号。 按需安装运行语言环境。 运行语言 说明 Go 安装 Go,需使用 Go 1.13 或以上版本。您可以执行 go version 查看 Go 的版本。 Python 安装 Python,需使用 Python 2.7 或以上版本。您可以执行 python --ve...
通过 Kafka 消费 Canal Proto 格式的订阅数据
运行语言 说明 Go 通过代码示例中参数 config.Version 指定服务端 Kafka 版本号。 Python 通过示例代码中参数 api_version 指定服务端 Kafka 版本号。 Java 通过 maven pom.xml 文件中参数 version 指定服务端 Kafka 版本号。 按需安装运行语言环境。 运行语言 说明 Go 安装 Go,需使用 Go 1.13 或以上版本。您可以执行 go version 查看 Go 的版本。 Python 安装 Python,需使用 Python 2.7 或以上版本。您可以执行 python --ve...
Kafka订阅埋点数据(私有化)
本文档介绍了在增长分析(DataFinder)产品私有化部署场景下,开发同学如何访问Kafka Topic中的流数据,以便进一步进行数据分析和应用,比如实时推荐等。 1. 准备工作 kafka消费只支持内网环境消费,在开始之前,需要提前准备好如下输入: Kafka 0.10.1版本及以上的客户端(脚本或JAR包) zookeeper链接:可联系运维获取 broker链接:可联系运维获取 topic名称:下方给出了两个topic数据格式,确认需要消费哪一个topic; ConsumerGroup:确认好Co...
Kafka订阅埋点数据(私有化)
本文档介绍了在增长分析(DataFinder)产品私有化部署场景下,开发同学如何访问Kafka Topic中的流数据,以便进一步进行数据分析和应用,比如实时推荐等。 1. 准备工作 kafka消费只支持内网环境消费,在开始之前,需要提前准备好如下输入: Kafka 0.10.1版本及以上的客户端(脚本或JAR包) zookeeper链接:可联系运维获取 broker链接:可联系运维获取 topic名称:下方给出了两个topic数据格式,确认需要消费哪一个topic; ConsumerGroup:确认好Co...
Kafka订阅埋点数据(私有化)
本文档介绍了在增长分析(DataFinder)产品私有化部署场景下,开发同学如何访问Kafka Topic中的流数据,以便进一步进行数据分析和应用,比如实时推荐等。 1. 准备工作 kafka消费只支持内网环境消费,在开始之前,需要提前准备好如下输入: Kafka 0.10.1版本及以上的客户端(脚本或JAR包) zookeeper链接:可联系运维获取 broker链接:可联系运维获取 topic名称:下方给出了两个topic数据格式,确认需要消费哪一个topic; ConsumerGroup:确认好C...
消息队列选型之 Kafka vs RabbitMQ
在面对众多的消息队列时,我们往往会陷入选择的困境:“消息队列那么多,该怎么选啊?Kafka 和 RabbitMQ 比较好用,用哪个更好呢?”想必大家也曾有过类似的疑问。对此本文将在接下来的内容中以 Kafka 和 RabbitMQ 为例分... (https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/1cc0603e317847c9b8d7f5e92b75924f~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716913234&x-signature=0Of0lMaLchQ47RrWFWeUxuYh...
使用 Kafka 协议上传日志
日志服务支持通过 Kafka 协议上传日志数据到服务端,即可以使用 Kafka Producer SDK 来采集日志数据,并通过 Kafka 协议上传到日志服务。本文介绍通过 Kafka 协议将日志上传到日志服务的操作步骤。 背景信息Kafka 作... 支持的 Logstash 版本为 7.12~8.8.1。如果您需要使用其他 Logstash 版本,可以通过工单系统联系技术支持沟通业务需求。 建议在测试阶段通过以下配置测试插件连通性,生产环境中需要删除其中 stdout 相关的输出配置。...
Kafka消息订阅及推送
1. 功能概述 VeCDP产品提供强大的开放能力,支持通过内置Kafka对外输出的VeCDP系统内的数据资产。用户可以通过监测Kafka消息,及时了解标签、分群等数据变更,赋能更多企业业务系统。 2. 消息订阅配置说明 topic规范... 7 cdp.label.label.modify 修改标签 _event_name 事件名称 String 是 cdp.label.label.modify _event_timestamp 变更时间 Long 是 project_id 所属项目ID Long 是 subject_id 主体ID Long 是...
Kafka数据同步
Kafka MirrorMaker 是 Kafka 官网提供的跨数据中心流数据同步方案,其实现原理是通过从 Source 集群消费消息,然后将消息生产到 Target 集群从而完成数据迁移操作。用户只需要通过简单的consumer配置和producer配置,启动MirrorMaker,即可实现实时数据同步。本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流...
