服务器操作标准
 社区干货
社区干货
WebRTC 服务器架构 | 社区征文
肯定少不了服务器的支持。目前,WebRTC 主要有三种网络架构:Mesh、MCU、SFU。今天就来分别介绍一下三者,带大家认识一下它们的优点和缺点。# 正文## 1. Mesh(P2P)### 简介 Mesh 服务器架构其实就是标准 P2P ... 比如使用手机进行多人的视频通话,由服务端来抵消移动端的资源消耗。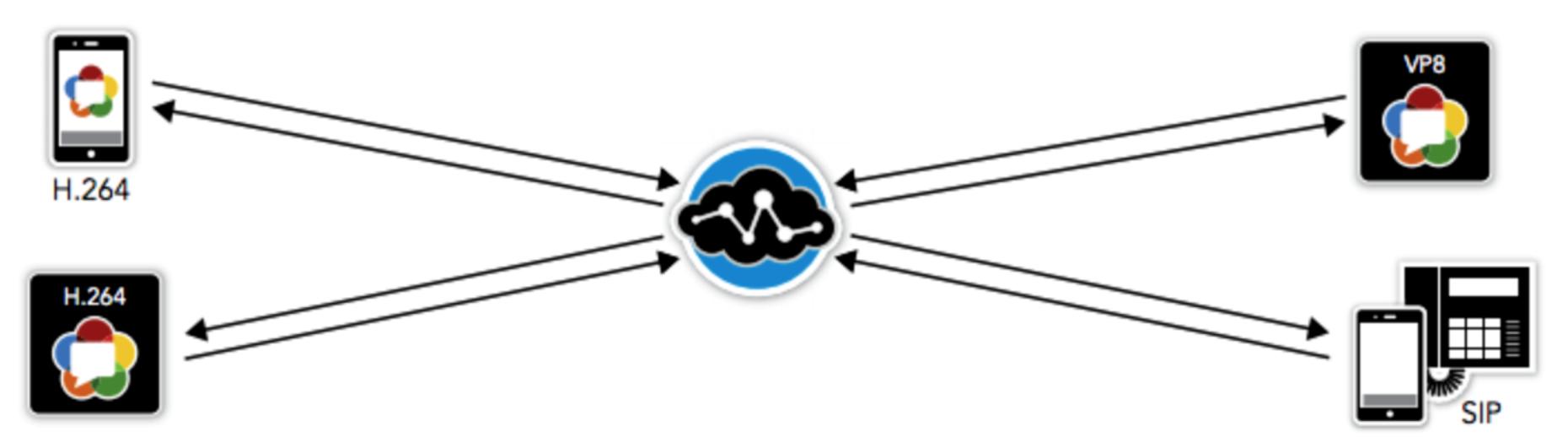### 缺点...
(进阶~)保姆级指南!通过脚本(非Docker版)快速搭建幻兽帕鲁服务器
本文展示如何通过脚本(非Docker版)快速搭建Palworld服务器,仅需在云服务器中执行一条命令,安心等待搭建结束即可。 本方式仅支持在Linux操作系统中使用,建议云服务器操作系统使用Ubuntu 22.04。 攻略持续跟新中~#... 在云服务器中执行如下命令,进行更新操作。 ``` sudo systemctl stop pal-world-server.service sudo -u steam $(which steamcmd) +login anonymous +app_update 2394010 validate +quit ``` ...
(基础)保姆级指南!手动在火山引擎云服务器中搭建幻兽帕鲁服务器
攻略持续跟新中~## 视频指导手动部署操作,可以参考官方发布的视频 [4分钟!搞定幻兽帕鲁服务器](https://developer.volcengine.com/videos/7332108913758142503)。## 前提条件1. 参考[购买云服务器](https:/... 6. 将Palworld服务器进程创建为自定义服务。 1. 执行如下命令,创建并进入palworld服务文件。 ``` vim /etc/systemd/system/pal-world-server.service ``` 2. 按`i`键...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
由于SparkSQL缺乏一个类似Hive Server2的SQL服务器,导致SparkSQL在易用性上比不上Hive。很多时候,SparkSQL只能将自身SQL作业打包成一个Jar,进行spark-submit命令提交,因而大大降低Spark的易用性。除此之外,还可使用周边工具,如Livy,但Livy更像一个Spark 服务器,而不是SparkSQL服务器,因此无法支持类似BI工具或者JDBC这样的标准接口进行访问。虽然Spark 提供Spark Thrift Server,但是Spark Thrift Server的局限非常多,几乎很难...
 特惠活动
特惠活动
 服务器操作标准-优选内容
服务器操作标准-优选内容
 服务器操作标准-相关内容
服务器操作标准-相关内容
管理后端服务器
本文介绍了如何通过控制台管理后端服务器。例如,您可以向一个监听器中添加后端服务器或者从一个监听器中移除后端服务器。 添加后端服务器登录边缘计算节点控制台。 在左侧导航栏中,选择边缘网络 > 负载均衡。 在负载均衡实例列表中,找到目标负载均衡实例,单击操作列的设置监听器。 在监听器列表中,找到目标监听器,单击操作列的设置后端服务器。 在后端服务器页签,按照后端服务器的类型进行操作。后端服务器类型为边缘实例单击添加...
配置后端服务器组
操作场景创建一个后端服务器组,添加已创建的后端服务器,使后端服务器组通过80端口提供服务。 操作步骤步骤一:创建后端服务器组登录负载均衡控制台。 在顶部导航栏,选择目标资源所属的项目和地域。 单击目标实例名称进入实例详情页,选择“后端服务器组”页签。 单击“创建后端服务器组”按钮。 配置后端服务器组的名称,本例配置为“group01”。 单击“确定”按钮,完成操作。 步骤二:添加后端服务器单击已创建的后端服务器组的名称...
服务器迁移任务
导入迁移源信息后,SMC控制台会自动生成迁移源记录,您可以在控制台为迁移源创建并启动迁移服务器迁移任务,将源服务器数据迁移至火山引擎新实例或保存为整机自定义镜像(即包含系统盘和数据盘数据的自定义镜像)。本文介绍创建迁移任务、查看迁移任务详情等操作步骤。 前提条件您需要完成迁移源导入操作,详情可查看导入迁移源。 请确认待迁移数据的源服务器,符合服务器迁移规范。 注意事项迁移成功后,火山引擎将自动为迁移目标创建自...
(进阶~)保姆级指南!通过脚本(非Docker版)快速搭建幻兽帕鲁服务器
本文展示如何通过脚本(非Docker版)快速搭建Palworld服务器,仅需在云服务器中执行一条命令,安心等待搭建结束即可。 本方式仅支持在Linux操作系统中使用,建议云服务器操作系统使用Ubuntu 22.04。 攻略持续跟新中~#... 在云服务器中执行如下命令,进行更新操作。 ``` sudo systemctl stop pal-world-server.service sudo -u steam $(which steamcmd) +login anonymous +app_update 2394010 validate +quit ``` ...
(基础)保姆级指南!手动在火山引擎云服务器中搭建幻兽帕鲁服务器
攻略持续跟新中~## 视频指导手动部署操作,可以参考官方发布的视频 [4分钟!搞定幻兽帕鲁服务器](https://developer.volcengine.com/videos/7332108913758142503)。## 前提条件1. 参考[购买云服务器](https:/... 6. 将Palworld服务器进程创建为自定义服务。 1. 执行如下命令,创建并进入palworld服务文件。 ``` vim /etc/systemd/system/pal-world-server.service ``` 2. 按`i`键...
后端服务器获取客户端源IP
本文为您介绍后端服务器如何获取访问 ALB 的客户端源 IP 地址。 基本原理ALB 的监听器(HTTP监听器、HTTPS监听器)通过配置后端服务器,可以使用 X-Forwarded-For 的方式获取客户端的真实 IP 地址。 真实的客户端 IP 会被 ALB 放在 HTTP 头部的 X-Forwarded-For 字段,字段中的第一个地址就是客户端真实 IP 。具体格式如下:X-Forwarded-For: 来访者真实IP, 代理服务器1-IP, 代理服务器2-IP, ... 配置步骤操作系统本文以 CentOS 7.6...
配置云平台服务器
本文介绍迁移源为其他云平台的云服务器时,迁移前需完成的额外配置。 操作场景由于各个云平台提供的云服务器镜像存在差异,当您的迁移源为其他云平台的云服务器时,部分镜像类型的云服务器需完成额外配置才能正常完成迁移操作。 操作步骤阿里云CentOS/AnolisOS 使用root权限登录您的阿里云服务器实例。 执行如下命令,修改cloud.cfg文件。 编辑cloud.cfg文件。vim /etc/cloud/cloud.cfg 按i键进入编辑模式,将文件内容替换为如下内容...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
由于SparkSQL缺乏一个类似Hive Server2的SQL服务器,导致SparkSQL在易用性上比不上Hive。很多时候,SparkSQL只能将自身SQL作业打包成一个Jar,进行spark-submit命令提交,因而大大降低Spark的易用性。除此之外,还可使用周边工具,如Livy,但Livy更像一个Spark 服务器,而不是SparkSQL服务器,因此无法支持类似BI工具或者JDBC这样的标准接口进行访问。虽然Spark 提供Spark Thrift Server,但是Spark Thrift Server的局限非常多,几乎很难...
添加后端服务器
本章节为您介绍如何为后端服务器组添加同VPC内的后端服务器。 说明 如需添加跨VPC的后端服务器,请参见添加跨VPC后端服务器。 操作说明如果待添加的后端服务器所在子网关联了网络ACL规则,为保证负载均衡正常工作,您需要对后端服务器所在子网的网络ACL进行配置,详细规则可参见负载均衡使用的网络ACL。 负载均衡支持添加IPv4或IPv6类型的后端服务器,您可以按需选择。 操作步骤根据后端服务器组的类型不同,添加后端服务器的步骤有所...
