数据库基线检查产品厂家
 社区干货
社区干货
系统集成在一些特定行业的相关概念
数据库技术、网络通讯技术等的集成,以及不同厂家产品选型,搭配的集成,系统集成所要达到的目标整体性能最优,即所有部件和成分合在一起后不但能工作,而且全系统是低成本的、高效率的、性能匀称的、可扩充性和可维护的... 业务数据检查:接口应提供业务数据检查功能,即对接收的数据进行合法性检查,对非法数据和错误数据则拒绝接收,以防止外来数据非法入侵,减轻应用支撑平台系统主机处理负荷。对于接口,其业务数据检查的主要内容有以下...
抖音大规模实践,火山引擎向量数据库是这样炼成的
向量数据库作为大模型“记忆体”,不仅能够为其提供数据存储,而且能通过数据检索、分析让大模型进行知识增强,成为生成式 AI 应用开发新范式的重要组成部分。用图片搜索图片或者文本搜索文本时,在数据库中存储和对... 相同检索精度下的吞吐和时延相比开源基线有了 3 倍以上的改善,且满足大规模线上业务的稳定性要求,因此被抖音集团大量业务采用。但因为每个索引搭建一套集群的成本较高,且存在配置复杂等问题,研发团队又对框架进...
抖音大规模实践,火山引擎向量数据库是这样炼成的
AI时代,如何用好大模型是当前各行各业瞩目的焦点。向量数据库作为大模型“记忆体”,不仅能够为其提供数据存储,而且能通过数据检索、分析让大模型进行知识增强,成为生成式AI应用开发新范式的重要组成部分。用图片... 相同检索精度下的吞吐和时延相比开源基线有了3倍以上的改善,且满足大规模线上业务的稳定性要求,因此被抖音集团大量业务采用。但因为每个索引搭建一套集群的成本较高,且存在配置复杂等问题,研发团队又对框架进一步...
数据一致性离不开的checkpoint机制 |社区征文
可以数据库故障恢复与检查点来学习checkpoint机制, 以下内容copy from 《数据库系统基础讲义》 事务对数据可进行操作时:先写运行日志;写成功后,在与数据库缓冲区进行信息交换。 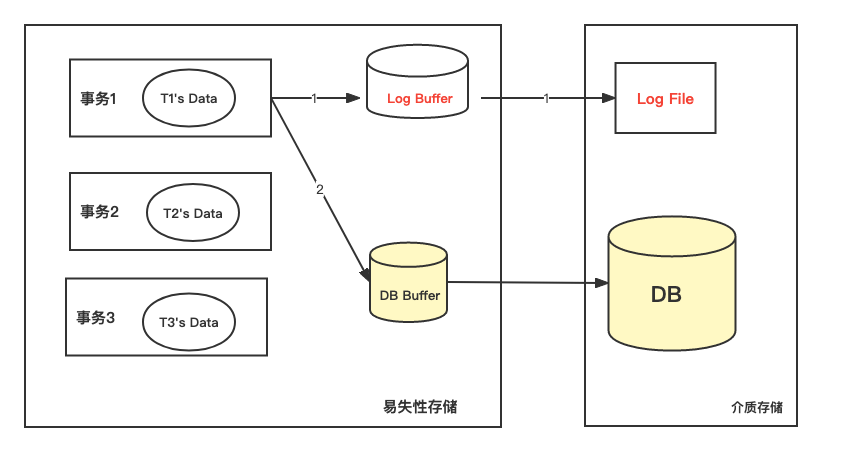 如果发生**数据库系统故障**可通过运行日志来恢复。根据运行日志记录的事物操作顺序重做事务(当事务发生故...
 特惠活动
特惠活动
 数据库基线检查产品厂家-优选内容
数据库基线检查产品厂家-优选内容
 数据库基线检查产品厂家-相关内容
数据库基线检查产品厂家-相关内容
抖音大规模实践,火山引擎向量数据库是这样炼成的
AI时代,如何用好大模型是当前各行各业瞩目的焦点。向量数据库作为大模型“记忆体”,不仅能够为其提供数据存储,而且能通过数据检索、分析让大模型进行知识增强,成为生成式AI应用开发新范式的重要组成部分。用图片... 相同检索精度下的吞吐和时延相比开源基线有了3倍以上的改善,且满足大规模线上业务的稳定性要求,因此被抖音集团大量业务采用。但因为每个索引搭建一套集群的成本较高,且存在配置复杂等问题,研发团队又对框架进一步...
数据一致性离不开的checkpoint机制 |社区征文
可以数据库故障恢复与检查点来学习checkpoint机制, 以下内容copy from 《数据库系统基础讲义》 事务对数据可进行操作时:先写运行日志;写成功后,在与数据库缓冲区进行信息交换。  如果发生**数据库系统故障**可通过运行日志来恢复。根据运行日志记录的事物操作顺序重做事务(当事务发生故...
安全说明
⼯作内容包括产品设计安全评估、代码安全审阅、漏洞扫描、渗透测试、威胁情报、⼊侵检测、应急响应、数据安全、安全合规等。 2.合规与隐私性火山引擎内容管理平台⾼度重视产品的合规性,由安全与合规部专职负责,积极... 并在国家法律法规允许的情况下对员工进行背景调查,确保该员工的录用符合公司的各项规章制度; 新员工须签订劳动合同和保密协议,其中对员工在信息安全方面所应承担的责任和义务进行了规范; 法务部每年对员工保密协议...
全链路敏捷研发
提供智能联想与动态语法检查,支持代码版本管理,带来流畅的开发体验,显著提升开发效率。 基于 EMR、Serverless Flink、ByteHouse、LAS 等多种存储计算引擎,提供丰富的数据开发任务类型,如离线任务,流式任务,通用任务、交互式分析查询等任务类型。 支持临时查询、数据库、资源库、函数库、任务模版、回收站、插件市场等产品能力。 详见数据开发。 3 调度系统自定义复杂调度设置 每日百万级实例调度支撑,保障生产稳定、高效运行 调度...
干货|数据湖技术在抖音近实时场景的实践
具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。* Hudi 支持各类计算、查询引擎(Flink、Spark、Presto、Hive),底层存储兼容各类文件系统 (HDFS、Amazon S3、GCS、OSS)* H... 不嵌入到具体的产品功能或者业务流程中,所以对延迟和质量 SLA 的容忍度较高。* 面向运维型的需求,主要用户是数据研发人员和数据运维人员。这类场景需要成本低廉、操作便捷的存储来提高研发和运维的效率。总...
字节跳动基于数据湖技术的近实时场景实践
具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。 - Hudi 支持各类计算、查询引擎(Flink、Spark、Presto、Hive),底层存储兼容各类文件系统 (HDFS、Amazon S3、GCS、OSS) - H... 降低数据基线破线的风险。通过复用批流计算的结果,也可以提高开发的人效。- 统一存储:字节数据湖采用HDFS作为底层存储层,通过将ods、dwd这类偏上游的数仓层次的数据入湖,并将加工dws、app层的计算放在湖内, ...
字节跳动基于数据湖技术的近实时场景实践
具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。 - Hudi 支持各类计算、查询引擎(Flink、Spark、Presto、Hive),底层存储兼容各类文件系统 (HDFS、Amazon S3、GCS、OSS)- ... 不嵌入到具体的产品功能或者业务流程中,所以对延迟和质量 SLA 的容忍度较高。- **面向运维型的需求**,主要用户是数据研发人员和数据运维人员。这类场景需要成本低廉、操作便捷的存储来提高研发和运维的效率。...
基于火山引擎微服务引擎 MSE 的全链路灰度落地实践
产品提供开源增强的 Nacos 注册发现、配置管理,兼容原生 Spring Cloud 、gRPC 及 Service Mesh 架构丰富微服务治理能力。来源 | 火山引擎云原生团队在业务发布变更过程中,为最大限度降低对在线用户影响,保障版本发布质量,通常采用 **灰度发布**的方式将少量的实际生产流量导入至更新版本,达到预期结果及充分测试验证后,将流量渐进式切流至更新版本随即完成基线版本服务下线。然而在微服务架构体系中,由于...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
**相关产品**:https://www.volcengine.com/product/flink # 机器学习样本存储:背景与趋势在字节跳动,机器学习模型的应用范围非常广泛。为了支持模型的训练,我们建立了两大训练平台:推荐广告训练平台和通用的... 其次是通过**传统数据库方案**存放样本,这种方案更多适用于处理少量样本的场景,当海量数据达到 PB、EB 级时会遇到困难。此外由于训练代码无法直接读取数据库底层文件,读取吞吐量可能受限制,即使在实时拼接特征、标...
