大数据数据仓库实例
 社区干货
社区干货
DataLeap数据仓库流程最佳实践
我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表)* DWD(对ODS冗余表数据进行轻度过滤处理)* DWM (基于DWD表与业务需求,轻度聚合最近三天的数据)* APP (基于DWD或DWM,输出具体报表信息)在“数据地图”中创建数据仓库中要使用到的表: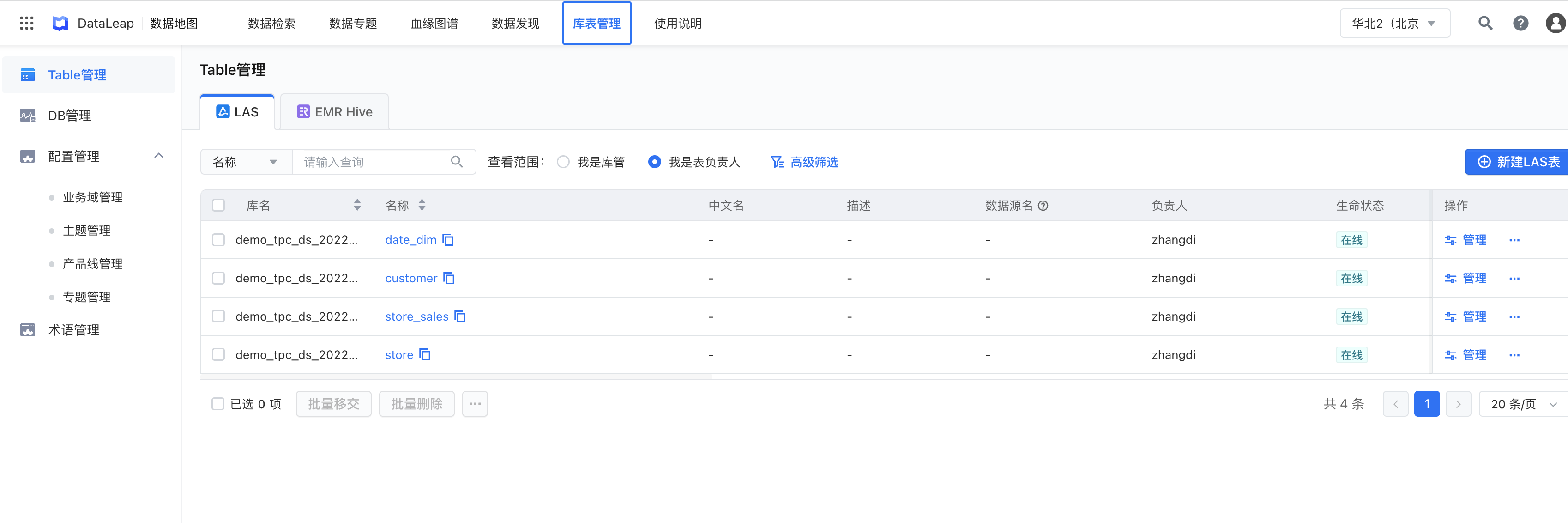本案例中库信息为:demo_tpc_ds_20...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... [维度建模事实表示例](https://img-blog.csdnimg.cn/20201103111923706.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JlaWlzQmVp,size_1,color_FFF...
ByConity 技术详解之 ELT
而把大部分的转换操作留给分析阶段。相比起前者(ETL),它不需要过多的数据建模,而给分析者提供更灵活的选项。ELT已经成为当今大数据的处理常态,它对数据仓库也提出了很多新的要求。 ### 资源重复的挑战 特惠活动
特惠活动
 大数据数据仓库实例-优选内容
大数据数据仓库实例-优选内容
 大数据数据仓库实例-相关内容
大数据数据仓库实例-相关内容
邀测上线 | 大数据HDD型d2实例规格
ECS正式发布新一代大数据HDD型d2实例,单核配比高达1.7T HDD本地盘,整机配比24块8THDD本地盘,轻松应对海量数据分析存储场景。同时,搭载主频2.8GHz的第三代英特尔® 至强® 可扩展处理器(Ice Lake),全核睿频3.5GHz,较... 大数据分析工作负载(如 Elastic MapReduce、Spark、Flink、Hadoop)、搜索和日志数据处理场景(如 ElasticSearch、Kafka)、大规模并行处理及数据仓库(如 Redshift)。 该实例将进行全地域发布,各地域资源正在陆续推进...
ByConity 技术详解之 Hive 外表和数据湖
随着大数据处理需求的不断增加,更低成本的存储和更统一的分析视角变得愈发重要。数据仓库作为企业核心决策支持系统,如何接入外部数据存储已经是一个技术选型必须考虑的问题。也出于同样的考虑,ByConity 0.2.0 中发... 而不必为每个存储创建单独的 Hive 实例。这简化了数据管理和查询的复杂性,使组织能够更好地管理和利用其多样化的数据资源。目前已经支持的外部 Catalog 有:Hive,Apache Hudi,AWS Glue。 用户可以使用创建一个...
基于火山引擎 EMR 构建企业级数据湖仓
作者:辛现银,火山引擎开源大数据平台 E-MapReduce 技术架构师> 本文整理自火山引擎开发者社区[技术大讲堂第四期](https://developer.volcengine.com/activity/7127929233808031774)演讲,主要为大家介绍了数据湖仓... 都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为...
我的大数据学习总结 |社区征文
接触数据库Hive后,学习数据流技术Kafka和分布式协调服务Zookeeper。深入研究Yarn和求执行引擎Spark。此外还了解其他技术如HBase、Sqoop等。同时学习计算机网络知识和操作系统原理。后面再系统学习关系数据库MySQL和数据仓库理论。学习分布式原理和架构也很重要。这个学习顺序参考了我之前的工作和学习经历情况后订定。需要注意,大数据领域的技术很多很广,如Flink也值得研究。本人给出的仅作为一个参考案例,学习者还需结合实际情...
干货 | 这样做,能快速构建企业级数据湖仓
Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为 Java 做 Codegen 比做向量化要更容易一些。但现在,向量化是一个更好的选择,因为向量化可以一次处理一批数据,而不只是一条数据。其好处是可以充分利用 CPU 的特性,如 SIMD,Pipeline 执行等...
ByConity 替换 ClickHouse 构建 OLAP 数据平台,资源成本大幅降低
作者|程伟,MetaAPP 大数据研发工程师【项目地址】GitHub |https://github.com/ByConity/ByConity> ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致性等多种需求的同时,并提供优异的查询,写入性能。MetaApp 是国内领先的游戏开发与运营商,专注移动端信息高效分发,致力于构建面向全年龄段的虚拟世界。截至 2023 年,MetaApp 注册用户已超 2 亿,联运合作 20 万款游...
浅谈数仓建设及数据治理 | 社区征文
数据仓库模型的建设方法和业务系统的企业数据模型类似。在业务系统中,企业数据模型决定了数据的来源,而企业数据模型也分为两个层次,即主题域模型和逻辑模型。同样,主题域模型可以看成是业务模型的概念模型,而逻辑模型则是域模型在关系型数据库上的实例化。#### 2) 实体建模法实体建模法并不是数据仓库建模中常见的一个方法,它来源于哲学的一个流派。从哲学的意义上说,客观世界应该是可以细分的,客观世界应该可以分成由一个个实...
基于火山引擎 EMR 构建企业级数据湖仓
本文整理自火山引擎开发者社区技术大讲堂第四期演讲,主要介绍了数据湖仓开源趋势、火山引擎 EMR 的架构及特点,以及如何基于火山引擎 EMR 构建企业级数据湖仓。作者:辛现银,火山引擎开源大数据平台 E-Map... 都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.03
> 火山引擎数据中台产品双月刊涵盖「大数据研发治理套件 DataLeap」「云原生数据仓库 ByteHouse」「湖仓一体分析服务 LAS」「云原生开源大数据平台 E-MapReduce」四款数据中台产品的功能迭代、重点功能介绍、平台最... ### **云原生开源大数据平台E-MapReduce****【** **EMR** **Stateless】** 无状态的 EMR 实例,交付轻量级的瞬态集群。在存算分离的基础上进一步服务化 EMR 集群的状态元素,含状态 Server(如 HMS、History Server...
