企业数据仓库建设
 社区干货
社区干货
干货 | 这样做,能快速构建企业级数据湖仓
火山引擎 EMR 是开源大数据平台 E-MapReduce,提供企业级的 Hadoop、Spark、Flink、Hive、Presto、Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100% 开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,能帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。火山引擎 EMR 有以下 4 个特点:* **开源兼容&开放环境** :100% 兼容社区主流版本,满足应用开发需求;同时提供半托管的白盒...
浅谈数仓建设及数据治理 | 社区征文
在数据仓库的模型设计中,一般采用第三范式。一个符合第三范式的关系必须具有以下三个条件 :- 每个属性值唯一,不具有多义性 ;- 每个非主属性必须完全依赖于整个主键,而非主键的一部分 ;- 每个非主属性不能依赖于其他关系中的属性,因为这样的话,这种属性应该归到其他关系中去。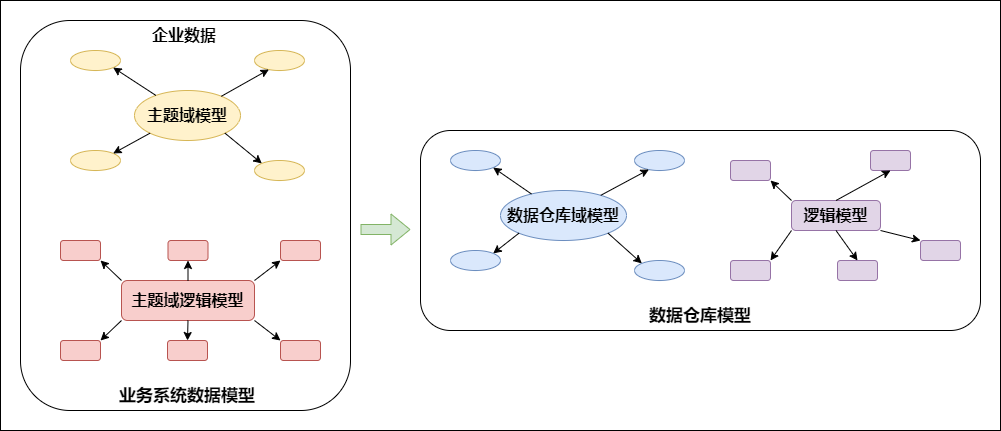根据 Inmon 的观点,数据仓库模型的建设方法和业务系统的企业数据模型类似...
观点|SparkSQL在企业级数仓建设的优势
> > > 企业级数仓架构设计与选型的时候需要从开发的便利性、生态、解耦程度、性能、 安全这几个纬度思考。本系列分两次连载, **第一部分(本文)分享我们在企业级数仓建设上的技术选型观点** ,第二个部分则重点介... 管理元数据服务的Hive Metastore,以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式任务执行,以及元数据中心,这一系列组合让Hive完整的具备了构建一个企业级数据仓库的所有...
SparkSQL 在企业级数仓建设的优势
企业级数仓建设的实践。文 | **惊帆** 来自 字节跳动数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,...
 特惠活动
特惠活动
 企业数据仓库建设-优选内容
企业数据仓库建设-优选内容
 企业数据仓库建设-相关内容
企业数据仓库建设-相关内容
如何快速构建企业级数据湖仓?
火山引擎 EMR 是开源大数据平台 E-MapReduce,提供企业级的 Hadoop、Spark、Flink、Hive、Presto、Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100% 开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,能帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。火山引擎 EMR 有以下 4 个特点:- **开源兼容&开放环境**:100% 兼容社区主流版本,满足应用开发需求;同时提供半托管的白...
基于火山引擎 EMR 构建企业级数据湖仓
基于火山引擎 EMR 构建企业级数据湖仓 **火山引擎 EMR**一句话总结来说,火山引擎 EMR 是开源大数据平台 E-MapReduce,提供企业级的 Hadoop、Spark、Flink、Hive、Presto、Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100% 开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,能帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。火山引擎 EMR 有以下...
从思考到实践,企业级大数据平台的构建之路
点击上方👆蓝字关注我们! 伴随着移动互联网、5G、AI、IoT 的飞速发展,企业数据建设正处于更大规模和更多样的变化趋势中。传统自建数据仓库,在企业数据体量持续增长、业务时效性持续提升的情况下,已经很难应对更复杂、更多样化的场景需求,平台扩展和数据融合面临重重障碍。8 月18 日,火山引擎开发者社区技术大讲堂第四期将为大家从 **开源大数据生态**和 **源于字节跳动内部的智能实时湖仓**...
DataLeap数据仓库流程最佳实践
经典数据仓库按照大类分为基础数据层、应用数据层。 本样例中,我们的数据仓库建设思路是: ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表) DWD(对ODS冗余表数据进行轻度过滤处理) DWM (基于DWD表与业务... s_company_id int comment '公司id', s_company_name string comment '公司名称', s_street_number string comment '街道编号', s_street_name string comment '街道名称', s_street_type string ...
基于火山引擎 EMR 构建企业级数据湖仓
帮助用户解决这些挑战的开源大数据平台。## 基于火山引擎 EMR 构建企业级数据湖仓### 火山引擎 EMR一句话总结来说,火山引擎 EMR 是开源大数据平台 E-MapReduce,提供企业级的 Hadoop、Spark、Flink、Hive、Presto、Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100% 开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,能帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。...
DataLeap数据仓库流程最佳实践
经典数据仓库按照大类分为基础数据层、应用数据层。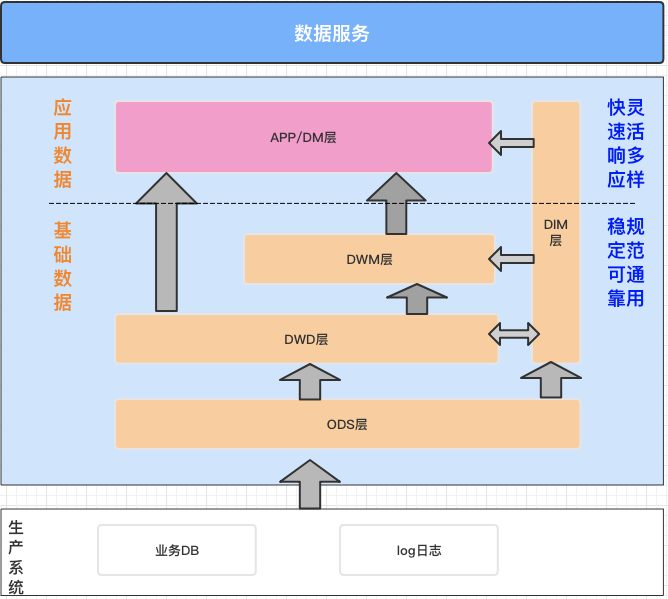本样例中,我们的数据仓库建设思路是:... s_company_id int comment '公司id', s_company_name string comment '公司名称', s_street_number string comment '街道编号', s_street_name string comment '街道名称', s_street_type str...
干货 | 看 SparkSQL 如何支撑企业级数仓
企业级数据仓库的所有特性,并且 Hive 的 SQL 服务器是目前使用最广泛的标准服务器。虽然 Hive 有非常明显的优点,可以找出完全替代 Hive 的组件寥寥无几,但是并不等于 Hive 在目前阶段是一个完全满足企业业务要求的组件,很多时候选择 Hive 出发点并不是因为 Hive 很好的支持了企业需求,单单是因为暂时找不到一个能支撑企业诉求的替代服务。# 企业级数仓构建需求数仓架构通常是一个企业数据分析的起点,在数仓之下会再有一层...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化... 用户行为数据和 IOT 数据的广泛采集存储,企业和政府单位的数据量每年呈现 30%以上的增长速度。 在过去集中式架构的数据仓库方案中,建设成本与数据总量正相关,成本居高不下;采用基于分布式架构的大数据方案中...
莉莉丝游戏与火山引擎ByteHouse达成合作,为实时数仓建设提速
建设的发展,为广告运营分析等业务领域带来更高效和创新的解决方案。**/ 关于莉莉丝游戏(Lilith **Games** )/**莉莉丝游戏成立于2013年,总部位于中国上海,是一家集游戏研发和全球发行于一体的知名游戏公司。莉莉丝游戏致力于打造优质游戏内容,不断推动游戏行业的创新与发展。目前,莉莉丝游戏在全球范围内拥有众多畅销游戏产品,并积极拓展海外市场。**/ 关于ByteHouse /**ByteHouse是火山引擎旗下的云原生数据仓库,专注...
