数据仓库搭建案例
 社区干货
社区干货
DataLeap数据仓库流程最佳实践
我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表)* DWD(对ODS冗余表数据进行轻度过滤处理)* DWM (基于DWD表与业务需求,轻度聚合最近三天的数据)* APP (基于DWD或DWM,输出具体报表信息)在“数据地图”中创建数据仓库中要使用到的表: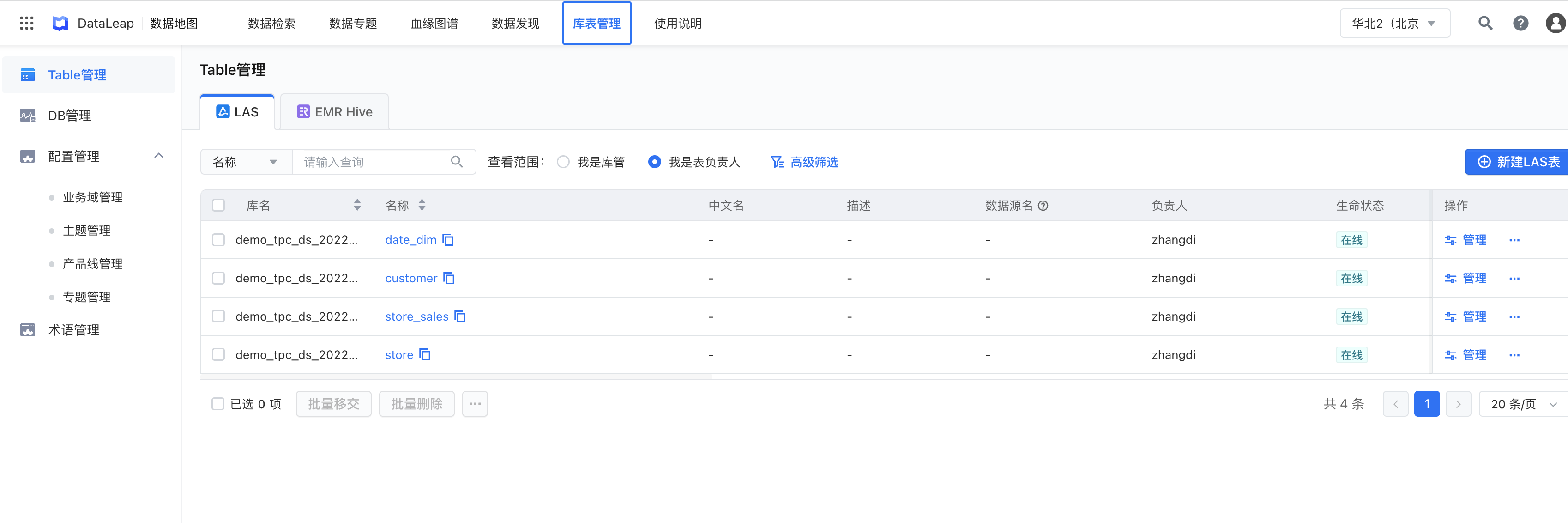本案例中库信息为:demo_tpc_ds_20...
干货 | 这样做,能快速构建企业级数据湖仓
案例或者商业公司,比如 Data Bricks、基于 Iceberg 的 Tabluar以及基于 Hudi 的 OneHouse 公司。通过这些公司的商业产品,底层组件、运维和优化都交由商业产品解决,有效减轻负担。而且商业公司还有能力提供上层的... Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走...
基于火山引擎 EMR 构建企业级数据湖仓
案例或者商业公司,比如 Data Bricks,基于 Iceberg 的 Tabluar,以及基于 Hudi 的 OneHouse 公司。通过这些公司的商业产品,用户无需直接接触底层组件,运维和底层优化都交由商业产品解决,负担就会减轻。而且商业公司还... 都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为...
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业... 准确的数据支撑,并能够按照已有的模型为新业务发展提供方向,也就是数据驱动和赋能。### 3. 如何搭建一个好的数仓?1. **稳定**:数据产出稳定且有保障。2. **可信**:数据干净、数据质量高。3. **丰富**:数据...
 特惠活动
特惠活动
 数据仓库搭建案例-优选内容
数据仓库搭建案例-优选内容
 数据仓库搭建案例-相关内容
数据仓库搭建案例-相关内容
基于火山引擎 EMR 构建企业级数据湖仓
对业务吸引不够:由于以上三点原因,Table Format 对业务的吸引力就大打折扣了。要怎么去解这些问题呢?现在业界已经有基于这些 Table Format 应用的经验、案例或者商业公司,比如 Data Bricks,基于 Iceberg 的 ... 都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** **近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHous... **随着大数据应用的深入发展,最核心的业务需求如下:****1)提高分析的实时性**最近 10 年,以 hadoop 技术体系为代表的大数据平台大规模部署,大大小小的企业和政府部门都搭建了大数据平台和分析应用,以隔天和小时...
ByConity 替换 ClickHouse 构建 OLAP 数据平台,资源成本大幅降低
ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致性等多种需求的同时,提供优异的查询,写入性能。文章来源|ByConity 开源社区GitHub |h... ByConity 已经完全接管了 ClickHouse 集群的数据,并已经开始稳定提供服务。我们使用云上 S3 加 K8s 的模式搭建了 ByConity 集群;同时使用了定时扩缩容方案,可以在工作日早上 10 点进行扩容,晚上 8 点进行缩容,一天...
元数据迁移
1 迁移和部署 Apache Hive 到火山引擎 EMRApache Hive 是一个开源的数据仓库和分析包,它运行在 Apache Hadoop 集群之上。Hive 元存储库包含对表的描述和构成其基础的基础数据,包括分区名称和数据类型。Hive 是可以... 外置数据库和 Metastore 服务三种: 内置数据库作为 Hive 元数据建议只应用于开发和测试环境。 使用火山引擎 RDS 作为 Hive 元数据 外置数据库可以是火山引擎的 RDS 数据库或者客户在 ECS 上部署的数据库实例。 创...
如何快速构建企业级数据湖仓?
案例或者商业公司,比如 Data Bricks、基于 Iceberg 的 Tabluar以及基于 Hudi 的 OneHouse 公司。通过这些公司的商业产品,底层组件、运维和优化都交由商业产品解决,有效减轻负担。而且商业公司还有能力提供上层的... Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了...
ByConity 替换 ClickHouse 构建 OLAP 数据平台,资源成本大幅降低
作者|程伟,MetaAPP 大数据研发工程师【项目地址】GitHub |https://github.com/ByConity/ByConity> ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致... ByConity 已经完全接管了 ClickHouse 集群的数据,并已经开始稳定提供服务。我们使用云上 S3 加 K8s 的模式搭建了 ByConity 集群;同时使用了定时扩缩容方案,可以在工作日早上 10 点进行扩容,晚上 8 点进行缩容,一天...
搭建Oracle
Oracle数据库(通常称为Oracle DBMS或简称为Oracle)是由Oracle公司生产和销售的多模型数据库管理系统。本文为您介绍如何搭建Oracle。 Oracle是一种常用于运行在线事务处理 (OLTP)、数据仓库 (DW) 和混合 (OLTP & DW... 与实例ID不同。 执行以下命令,打开/etc/hosts文件。vim /etc/hosts 按i进入编辑模式,在末尾添加私网IP和主机名。192.xx.xx.xx hostname 私网IP可在实例列表中查询获取。 按下 Esc 键,输入:wq并按下 enter 键,保...
使用 Hive 访问 CloudFS 中的数据
Hive 是基于 Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载。本文介绍如何配置 Hive 服务来访问 CloudFS 中的数据。 前提条件在使用 Hive 服务访问大数据文件存储服务 CloudFS 前,确保您已经完成以下准备工作: 开通大数据文件存储服务 CloudFS 并创建文件存储,获取挂载信息。详细操作请参考创建文件存储系统。 开通 E-MapReduce 服务并创建集群。详细操作请参考E-MapReduce 集群创建。 在配置 Hive 服务之前,请确认/u...
以 100GB SSB 性能测试为例,通过 ByteHouse 云数仓开启你的数据分析之路
能够在短短数分钟内体验到数据分析的魅力。 Talk is cheap, 接下来就让我们通过一个实战案例来体验下 ByteHouse 云数仓的强大功能。 ## II. 快速上手 ByteHouse——轻量级云数仓本章节通过使用 Byte... 目前 ByteHouse 支持包年包月和按量付费两种模式的实例,便于您根据业务需求进行选择。