数据集市与数据仓库异同
 社区干货
社区干货
活动预告|火山引擎 VeDI 数据中台架构剖析与方案分享
本次内容主要探讨新的数据治理解决方案,具体包括:* 字节数据治理的背景与机遇* 分布式的理解与落地* 分布式数据自治的架构体系分享**《解读火山引擎 EMR Stateless 创新理念和业务价值》*** 火山引擎 EMR 资深产品经理 林飞数据湖的出现是为了解决传统数据仓库和数据集市所面临的问题:避免原始数据丢失从而选择了保存原始数据本身,并且对建设的数据集市与数据存储的元数据有一致性。随着云上对象存储的普及,Hudi...
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
数据仓库中,利用 MPP 等大规模并发技术对企业的数据进行分析,支撑上层的商业分析和决策。## 数据湖阶段数仓的主要特点是只能处理结构化数据。随着数据科学和人工智能的发展,产生了越来越多的非结构化数据,但非结构化数据在数仓中处理中相对麻烦,于是数据湖技术出现了。 数据湖可以被定义为一种存储各类原始数据的存储库,原始数据包含结构化、半结构化以及非结构化数据。一部分原始数据会经过 ETL 同步到数据集市中,支撑商业...
揭秘字节跳动对 Apache Doris 数据湖联邦分析的升级和优化
数据仓库中,利用 MPP 等大规模并发技术对企业的数据进行分析,支撑上层的商业分析和决策。 ### 1.2 数据湖阶段数仓的主要特点是只能处理结构化数据。随着数据科学和人工智能的发展,产生了越来越多的非结构化数据,但非结构化数据在数仓中处理中相对麻烦,于是数据湖技术出现了。 数据湖可以被定义为一种存储各类原始数据的存储库,原始数据包含结构化、半结构化以及非结构化数据。一部分原始数据会经过 ETL 同步到数据集市中...
字节跳动基于数据湖技术的近实时场景实践
Hudi不仅仅是数据湖的一种存储格式(Table Format),而是提供了Streaming 流式原语的、具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。 - Hudi 支持各类计算、查询引擎(Fli... 面向运维型的需求,主要用户是数据研发人员和数据运维人员。这类场景需要成本低廉、操作便捷的存储来提高研发和运维的效率。总结以上两类场景的共同点为:均需以“较高人效、较低存储成本“的解决方案进行支持...
 特惠活动
特惠活动
 数据集市与数据仓库异同-优选内容
数据集市与数据仓库异同-优选内容
 数据集市与数据仓库异同-相关内容
数据集市与数据仓库异同-相关内容
浅谈数仓建设及数据治理 | 社区征文
和维度表(Dimension table)。其最简单的描述就是,按照事实表、维度表来构建数据仓库、数据集市。目前在互联网公司最常用的建模方法就是维度建模。**维度建模怎么建:**在实际业务中,给了我们一堆数据,我们怎么拿这些数据进行数仓建设呢,数仓工具箱作者根据自身60多年的实际业务经验,给我们总结了如下四步。数仓工具箱中的维度建模四步走: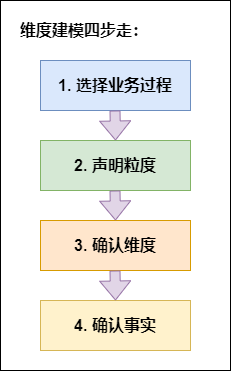这...
DataWind 产品使用问题排查方法
从而摒弃聚合字段或者聚合指标对真实行数据的干扰,从而便于排查主表字段是因为关联了什么字段而被拆分重复; 关于左连接,右连接,内连接,完全(外)连接的用法区别见: 数据模型 2.3 数据集同步失败数据集经常同步失败,... 数据集字段的目的是为了从业务层使用灵活封装及加载必要的字段到图表分析过程,是让用户从下游业务BI的数据仓库/数据集市角度重新定义数据的字段意义或统一整合更符合业务BI意义的字段集合;也正因为上述原理,所以会...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.09
[picture.image](https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/3ccb9e461d1f4ce9acd409b3ea93a60d~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716049240&x-signature=AjR0adWWFdqpPGYn8gNiGHq1LPw%3D)火山引擎数据中台产品双月刊涵盖「**大数据研发治理套件 DataLeap」「云原生数据仓库 ByteHouse」「湖仓一体分析服务 LAS」「云原生开源大数据平台 E-MapReduce」四款数据中台产品** 的功能...
干货 | 这样做,能快速构建企业级数据湖仓
近几年热门的 ClickHouse 和 Doris 也是 Native 化的表现。### **第二,向量化。**Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为 Java 做 Codegen 比做向量化要更容易一些。但现在,向量化是一个更好的选择,因为向量化可以一次处理...
Apache Pulsar 在火山引擎 EMR 的集成与场景
数据中台的大数据生产、服务体系,数据来源于交易系统、日志、IoT、消息、文件等,通过数据集成进入到数据湖中,然后经过数据开发、治理过程,进入到专题集市,最后通过数据分析平台提供给数据的最终用户,包括 BI 报表、... 该消息队列为大数据链路的第一站。从该消息队列开始,数据会继续向下游的离线 Hive 表或者实时数仓的下游消息队列流动。在此场景下,作为整个大数据体系的源头,消息队列连通业务系统和数据仓库,将大数据体系外面的数...
基于火山引擎 EMR 构建企业级数据湖仓
非结构化数据,支持多种场景的能力,同时也引入了 Data Warehouse 支持事务和数据质量的特点。LakeHouse 定义了一种叫我们称之为 Table Format 的存储标准。Table format 有四个典型的特征:- 支持 ACID 和历史... 近几年火起来的 ClickHouse 和 Doris 也是 Native 化的一个表现。另外一个趋势是向量化。说到这里要提一句,Codegen 跟向量化,都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而...
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
第一个阶段是数据仓库,第二个阶段是数据湖,第三个阶段是湖仓一体。 ### **/****数据仓库阶段****/**数据仓库是在上个世纪80年代兴起的一项技术。随着企业业务发展和大规模计算技术的发展,越来越... 数据湖可以被定义为一种存储各类原始数据的存储库,原始数据包含结构化、半结构化以及非结构化数据。一部分原始数据会经过 ETL 同步到数据集市中,支撑商业分析和决策类应用,另一部分数据将被机器学习和数据科学类应...
Apache Pulsar 在火山引擎 EMR 的集成与场景
数据中台的大数据生产、服务体系,数据来源于交易系统、日志、IoT、消息、文件等,通过数据集成进入到数据湖中,然后经过数据开发、治理过程,进入到专题集市,最后通过数据分析平台提供给数据的最终用户,包括 BI 报表、... 该消息队列为大数据链路的第一站。从该消息队列开始,数据会继续向下游的离线 Hive 表或者实时数仓的下游消息队列流动。在此场景下,作为整个大数据体系的源头,消息队列连通业务系统和数据仓库,将大数据体系外面的数...
基于 ByteHouse 构建实时数仓实践
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 **随着数据的应用场景越来越丰富,企业对数据价值反馈到业务中的时效性要求也越来越高,很早就有人提出过一个概念:**... 提高数据稳定性;ByteHouse 作为流式数据持久化存储层,使用 ByteHouse HaKafka 、HaUniqueMergeTree 表引擎可将 Kafka 临时数据高效稳定接入储存到 ByteHouse ,为后端应用提供极速统一的数据集市查询服务。具体的...
