数据集市与数据仓库相似
 社区干货
社区干货
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
数据仓库中,利用 MPP 等大规模并发技术对企业的数据进行分析,支撑上层的商业分析和决策。## 数据湖阶段数仓的主要特点是只能处理结构化数据。随着数据科学和人工智能的发展,产生了越来越多的非结构化数据,但非结构化数据在数仓中处理中相对麻烦,于是数据湖技术出现了。 数据湖可以被定义为一种存储各类原始数据的存储库,原始数据包含结构化、半结构化以及非结构化数据。一部分原始数据会经过 ETL 同步到数据集市中,支撑商业...
揭秘字节跳动对 Apache Doris 数据湖联邦分析的升级和优化
数据仓库中,利用 MPP 等大规模并发技术对企业的数据进行分析,支撑上层的商业分析和决策。 ### 1.2 数据湖阶段数仓的主要特点是只能处理结构化数据。随着数据科学和人工智能的发展,产生了越来越多的非结构化数据,但非结构化数据在数仓中处理中相对麻烦,于是数据湖技术出现了。 数据湖可以被定义为一种存储各类原始数据的存储库,原始数据包含结构化、半结构化以及非结构化数据。一部分原始数据会经过 ETL 同步到数据集市中...
活动预告|火山引擎 VeDI 数据中台架构剖析与方案分享
本次内容主要探讨新的数据治理解决方案,具体包括:* 字节数据治理的背景与机遇* 分布式的理解与落地* 分布式数据自治的架构体系分享**《解读火山引擎 EMR Stateless 创新理念和业务价值》*** 火山引擎 EMR 资深产品经理 林飞数据湖的出现是为了解决传统数据仓库和数据集市所面临的问题:避免原始数据丢失从而选择了保存原始数据本身,并且对建设的数据集市与数据存储的元数据有一致性。随着云上对象存储的普及,Hudi...
工业大数据分析与应用——知识总结 | 社区征文
大数据开发大大推动了新技术和新应用的不断涌现* 就业市场上,大数据的兴起使得数据科学家成为热门职业* 人才培养上,很大程度上改变中国高校信息技术相关专业的现有教学和科研体制### 1.4 典型大数据的应用略### 1.5 大数据关键技术* 数据采集:将**分布的、异构数据源**中的数据如关系数据、平面数据文件等,抽取到临时中间层后进行**清洗、转换、集成**,最后加载到**数据仓库或数据集市**中,成为联机分析处理、数据挖掘...
 特惠活动
特惠活动
 数据集市与数据仓库相似-优选内容
数据集市与数据仓库相似-优选内容
 数据集市与数据仓库相似-相关内容
数据集市与数据仓库相似-相关内容
DataWind 产品使用问题排查方法
模型的每个节点里所保留的数据源字段,即约等于存储在CK底表的模型字段;数据集字段来自于数据源字段,在第一次生成数据集时,会按照模型自动生成,名字=源字段名,但同时允许用户在【字段配置】里,自定义地新增或修改字段的名字以及字段的表达式(即取xx源字段做YY转换);数据集字段的目的是为了从业务层使用灵活封装及加载必要的字段到图表分析过程,是让用户从下游业务BI的数据仓库/数据集市角度重新定义数据的字段意义或统一整合更...
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
第一个阶段是数据仓库,第二个阶段是数据湖,第三个阶段是湖仓一体。 ### **/****数据仓库阶段****/**数据仓库是在上个世纪80年代兴起的一项技术。随着企业业务发展和大规模计算技术的发展,越来越... 数据湖可以被定义为一种存储各类原始数据的存储库,原始数据包含结构化、半结构化以及非结构化数据。一部分原始数据会经过 ETL 同步到数据集市中,支撑商业分析和决策类应用,另一部分数据将被机器学习和数据科学类应...
观点|SparkSQL在企业级数仓建设的优势
企业数据仓库架构必然不等于一个组件,大部分企业在数仓架构实施的都是都是基于现有的部分方案,进行基于自己业务合适的方向进行部分开发与定制,从而达到一个半自研的稳态,既能跟上业务变化的速度,又不过于依赖和受限于组件自身的发展。企业级数仓架构设计与选型维度一般来说企业级数仓架构设计与选型的时候需要从以下几个纬度思考: * 开发的便利性:所选择的数仓架构是否具有很好的开发生态,可以提供不同类型的开...
「火山引擎」数智平台 VeDI 数据中台产品季刊 VOL.10
[picture.image](https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/0b384afa9eee44d18dcf654dbfe404a3~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716049231&x-signature=tDOSz9VINByX8oMZT5Bip9qWtpM%3D)火山引擎数据中台产品双月刊涵盖「大数据研发治理套件 DataLeap」「云原生数据仓库 ByteHouse」「湖仓一体分析服务 LAS」「云原生开源大数据平台 E-MapReduce」四款数据中台产品的功能迭代、...
OLAP引擎也能实现高性能向量检索,据说QPS高于milvus!
通过提供与问题及历史答案相关联的内容,协助 LLM 返回更准确的答案。不仅仅是LLM,向量检索也早已在OLAP引擎中应用,用来提升非结构化数据的分析和检索能力。ByteHouse是火山引擎推出的云原生数据仓库,近期推出高性... 并进行一个近似度的匹配就可以实现对非结构化数据的查询。在技术原理层面,向量检索主要是做一个 K Nearest Neighbors (K最近邻,简称 KNN) 计算,目标是在N个D维的向量的库中找最相似的k个结果。在数据量较大场景...
记一次 ClickHouse 性能测试
开源的一个用于实时数据分析的基于列存储的数据库,其处理数据的速度比传统方法快 100-1000 倍。ClickHouse 的性能超过了目前市场上可比的面向列的 DBMS,每秒钟每台服务器每秒处理数亿至十亿多行和数十千兆字节的数据。它是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS),简单介绍一下 OLTP 和 OLAP。- OLTP:是传统的关系型数据库,主要操作增删改查,强调事务一致性,比如银行系统、电商系统。- OLAP:是仓库型数据库,主要是读...
SparkSQL 在企业级数仓建设的优势
企业数据仓库架构必然不等于一个组件,大部分企业在数仓架构实施的都是都是基于现有的部分方案,进行基于自己业务合适的方向进行部分开发与定制,从而达到一个半自研的稳态,既能跟上业务变化的速度,又不过于依赖和受限于组件自身的发展。## 企业级数仓架构设计与选型维度一般来说企业级数仓架构设计与选型的时候需要从以下几个纬度思考: - 开发的便利性:所选择的数仓架构是否具有很好的开发生态,可以提供不同类型的开发态...
浅谈数仓建设及数据治理 | 社区征文
和维度表(Dimension table)。其最简单的描述就是,按照事实表、维度表来构建数据仓库、数据集市。目前在互联网公司最常用的建模方法就是维度建模。**维度建模怎么建:**在实际业务中,给了我们一堆数据,我们怎么拿这些数据进行数仓建设呢,数仓工具箱作者根据自身60多年的实际业务经验,给我们总结了如下四步。数仓工具箱中的维度建模四步走: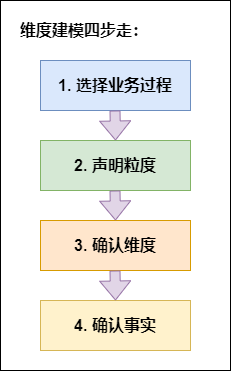这...
Apache Pulsar 在火山引擎 EMR 的集成与场景
数据中台的大数据生产、服务体系,数据来源于交易系统、日志、IoT、消息、文件等,通过数据集成进入到数据湖中,然后经过数据开发、治理过程,进入到专题集市,最后通过数据分析平台提供给数据的最终用户,包括 BI 报表、... 该消息队列为大数据链路的第一站。从该消息队列开始,数据会继续向下游的离线 Hive 表或者实时数仓的下游消息队列流动。在此场景下,作为整个大数据体系的源头,消息队列连通业务系统和数据仓库,将大数据体系外面的数...
