数据仓库是面对业务应用
 社区干货
社区干货
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
运是运营,即数据驱动业务运营策略【不再是盲人摸象式的策略】第二个视角从技术角度出发,我们可以提炼为八个字为**降本增效**,**清晰明了**1、降本是技术的使命,即让数据高效复用,减少重复开发2、增效是技术的价值,即降低数据使用门槛,让数据服务无处不在3、清晰明了是数据GPS,即清晰的管理、追踪、定位数据把为什么想清楚了,接下来就是探讨数据仓库是什么,是否能满足以上的诉求# 二、是什么,数据仓库定义数据仓库...
浅谈大数据建模的主要技术:维度建模 | 社区征文
也为我们后面讲Hadoop 数据仓库实战打下基础。## 维度建模关键概念### 度量和环境维度建模是支持对业务过程的分析,所以它是通过对业务过程度量进行建模来实现的。> **那么,什么是度量呢?**实际上,我们通过... 比如上文顾客购买行为事实表的粒度就应该是小票子项,而非小票。> **事实表中最常用的度量一般是数值型和可加类型的**比如小票子项的销售数量、销售金额等,可加性对于数据分析来说至关重要,因为数据应用一般不仅...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 以下为 ByteHouse 技术白皮书前两个版块摘录。# 1.ByteHouse 简介ByteHouse 是字节跳动自主研发的云原生数据仓库产品,在开源 Cli... 经过内部数百个应用场景和数万用户锤炼,并在多个外部企业客户中得到推广应用。## 产品特性**ByteHouse 以提供高性能、高资源利用率、高稳定性、低运维成本为目标,进行了优化设计和工程实现,产品特性和优势如下...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书整体架构设计版块摘录。** [点此查看ByteHouse技术白皮书(上)](https://developer.volcengine.c... 这些任务可以是数据写入、用户查询,也可以是一些后台任务。用户查询和后台任务,可以共享相同的计算节点以提高利用率,也可以使用独立的计算节点以保证严格的资源隔离。用户可以根据计算任务的特性、优先级和业务类别...
 特惠活动
特惠活动
 数据仓库是面对业务应用-优选内容
数据仓库是面对业务应用-优选内容
 数据仓库是面对业务应用-相关内容
数据仓库是面对业务应用-相关内容
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。2. 通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一...
DataLeap数据仓库流程最佳实践
经典数据仓库按照大类分为基础数据层、应用数据层。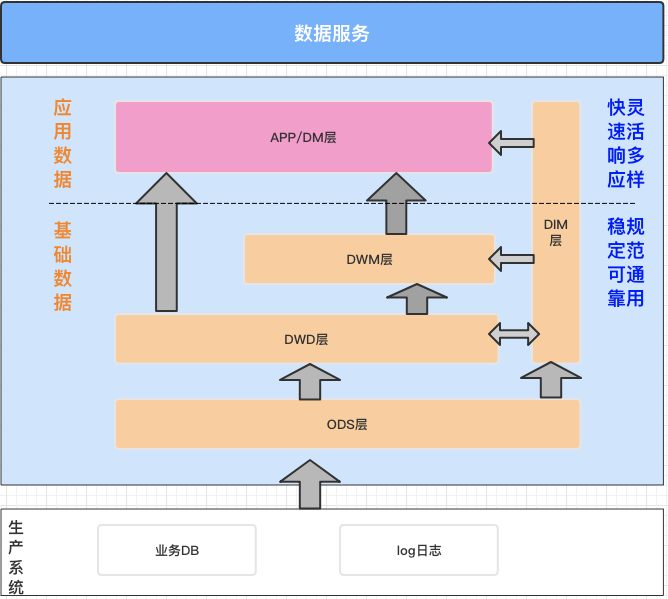本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表)* DWD(对ODS冗余表数据进行轻度过滤处理)* DWM (基于DWD表与业务需求,轻度聚合最近三天的数据)* APP (基于DWD或DWM,输出具体报表信息)在“数据地图”中...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的 OLAP 引擎优化,如列存储、向量化执行、MPP 执行、查询优化等,ByConity 可以提供优异的读写性能。项目背景----ByConity 的背景可以追溯到 2018 年,当时字节跳动开始在内部使用 ClickHouse,因为业务的发展,要...
云原生数据仓库ByteHouse性能白皮书(企业版)|火山引擎
白皮书下载 下载《云原生数据仓库ByteHouse性能白皮书(企业版)》 白皮书简介 在选择OLAP引擎时,性能是一个重要的因素。高性能,意味着:更短响应时间、更快处理能力、更好用户体验...... ByteHouse 是火山引擎自主研发的云原生数据仓库产品,它全面继承了开源 ClickHouse 的高性能和强大的分析能力,并在架构上遵循新一代云原生理念进行全面重构,实现了容器化、存储计算分离、多租户管理和读写分离等功能。在可扩展性、稳定性、可运维...
应用场景
应用场景1 云原生数据湖仓数据湖仓是一种结合了数据湖和数据仓库的新型数据架构,实现了更加灵活、高效和可扩展的数据管理,能够协助企业更好的理解和使用数据资产,提升业务价值。以互联网行业为例,企业需要搭建数据分析平台,聚合APP和日志数据分析客户行为支持精准营销,辅助分析决策。但自建开源大数据平台时,往往面临管理维护人力投入大,资源成本高且不灵活等问题。 火山引擎EMR提供丰富的主流开源大数据组件,100%开源兼容,支持平...
从思考到实践,企业级大数据平台的构建之路
点击上方👆蓝字关注我们! 伴随着移动互联网、5G、AI、IoT 的飞速发展,企业数据建设正处于更大规模和更多样的变化趋势中。传统自建数据仓库,在企业数据体量持续增长、业务时效性持续提升的... 火山引擎湖仓一体分析服务 LAS 是面向湖仓一体架构的 Serverless 数据处理分析服务,提供一站式的海量数据存储计算和交互分析能力,完全兼容 Spark、Presto、Flink 生态,在字节跳动内部有着广泛的应用。本次演讲将介...
ByConity 替换 ClickHouse 构建 OLAP 数据平台,资源成本大幅降低
ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致性等多种需求的同时,提供优异的查询,写入性能。文章来源|ByConity 开源社区GitHub |h... 对于大规模数据复杂查询的支持,吸引 MetaApp 对 ByConity 进行了深入测试,最终在生产环境全量替换 ClickHouse, **使资源成本降低超 50%。** 本文将主要介绍 MetaApp 数据分析平台的功能,业务场景中遇到的问题...
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
第一个阶段是数据仓库,第二个阶段是数据湖,第三个阶段是湖仓一体。## 数据仓库阶段数据仓库是在上个世纪80年代兴起的一项技术。随着企业业务发展和大规模计算技术的发展,越来越多的企业使用数据仓库来处理企业... 原始数据包含结构化、半结构化以及非结构化数据。一部分原始数据会经过 ETL 同步到数据集市中,支撑商业分析和决策类应用,另一部分数据将被机器学习和数据科学类应用直接访问。## 湖仓一体阶段数据湖模式缺乏一...
揭秘字节跳动对 Apache Doris 数据湖联邦分析的升级和优化
第一个阶段是数据仓库,第二个阶段是数据湖,第三个阶段是湖仓一体。 ### 1.1 数据仓库阶段数据仓库是在上个世纪80年代兴起的一项技术。随着企业业务发展和大规模计算技术的发展,越来越多的企业使用数据仓库来处... 原始数据包含结构化、半结构化以及非结构化数据。一部分原始数据会经过 ETL 同步到数据集市中,支撑商业分析和决策类应用,另一部分数据将被机器学习和数据科学类应用直接访问。 ### 1.3 湖仓一体阶段数据湖模...
