sql2014建立数据仓库
 社区干货
社区干货
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 不能将不同粒度的事实建立在同一张事实表中。### 维度表> **维度表是维度建模的灵魂,通常来说,维度表设计得好坏直接决定了维度建模的好坏**维度表包含了 实表所记录的业务过程度量的上下文和环境,它们除了记...
观点|SparkSQL在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台EMR团队EMR 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技术组件,而是一种设计理念。Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
今天给大家一起分享下有着悠久历史的数据仓库的一些思考由三部分组成为什么,搭建数据仓库是什么,数据仓库定义怎么做,如何搭建数仓# 一:为什么,搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效... 可以降低数据计算口径不统一的风险,同时可以方便进行交叉探查。以维度作为建模驱动,基于每个维度的业务含义,通过添加维度属性、关联维度等定义计算逻辑,完成属性定义的过程并建立一致的数据分析维表。- DM/ADS:...
ELT in ByteHouse 实践与展望
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。 将来源不同、格式各异的数... Server 端建立worker 健康度管理类,可以快速获取worker group 的健康度信息。包括cpu、内存、运行query数量等信息。- 自适应调度。每个sql 根据 worker 健康度动态的进行worker 选择以及计算节点并发度控制# ...
 特惠活动
特惠活动
 sql2014建立数据仓库-优选内容
sql2014建立数据仓库-优选内容
 sql2014建立数据仓库-相关内容
sql2014建立数据仓库-相关内容
DataLeap数据仓库流程最佳实践
实际操作火山引擎数据产品,完成数据仓库的构建。 关于实验 预计部署时间:50分钟 级别:初级 相关产品:大数据开发套件、湖仓一体分析服务LAS 受众: 通用 环境说明已购买DataLeap产品 已创建湖仓一体LAS队列 子... 新建“数据开发”任务: ODS层数据任务sql INSERT INTO demo_tpc_ds_2022_11_07_59.ods_demo_customer_store_sales_dfSELECT row_number() OVER( ORDER BY RAND() ) AS id, ...
DataLeap数据仓库流程最佳实践
完成数据仓库的构建。# 关于实验* 预计部署时间:50分钟* 级别:初级* 相关产品:大数据开发套件、湖仓一体分析服务LAS* 受众: 通用## 环境说明1. 已购买DataLeap产品2. 已创建湖仓一体LAS队列3. 子账户... 新建“数据开发”任务: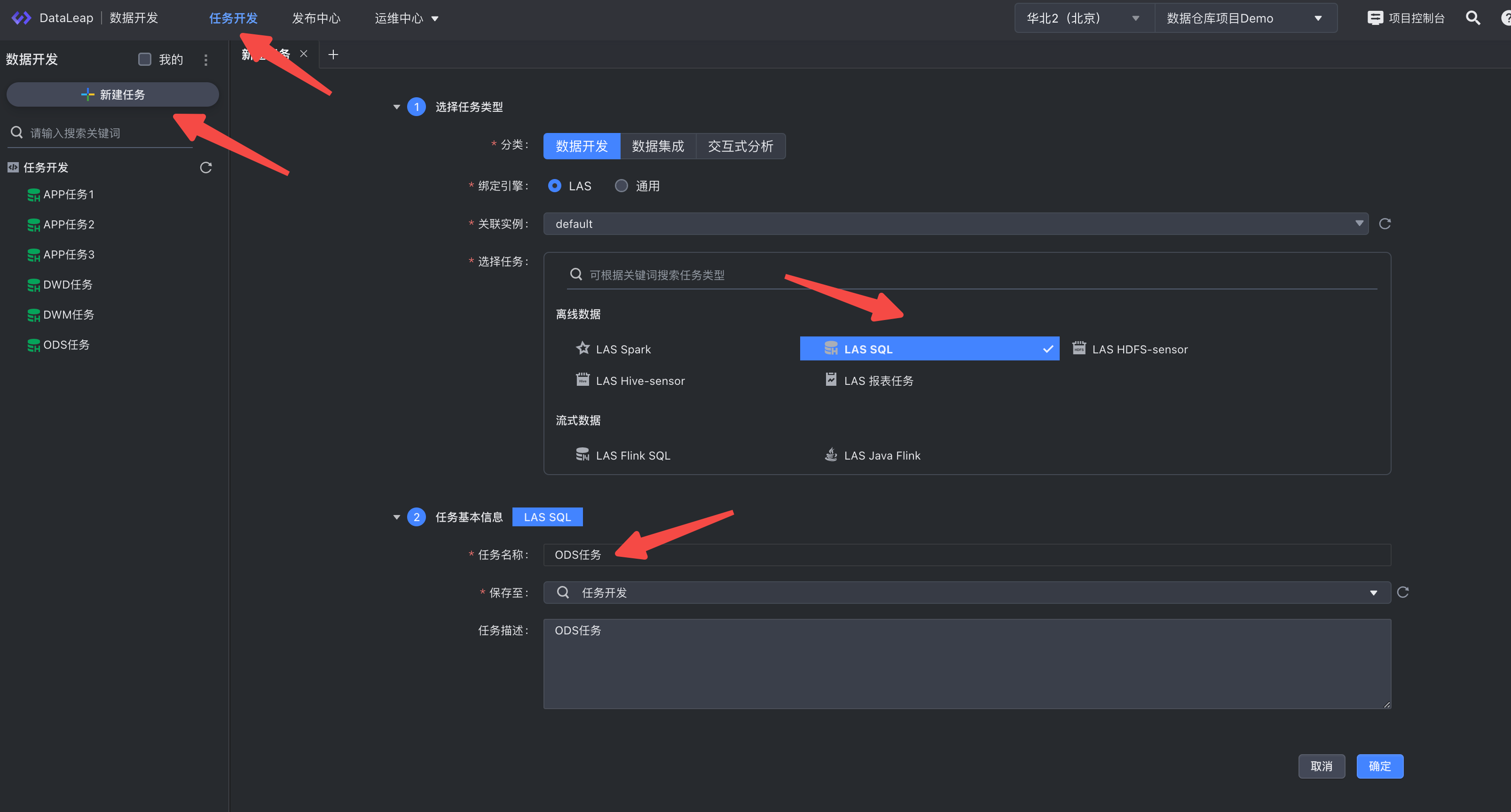或 Extract-Load-Transform (ELT)。 将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用Extract-Transform-Load ... 数据量相关,做不到完全平均;- 各 Plan Segment 所需资源差异大;这就导致worker节点之间的负载严重不均衡。负载较重的worker节点就会影响query整体的进程。因此我们做了以下的优化方案:- 建立 Worker 健康...
「火山引擎」数据中台产品双月刊 VOL.05
火山引擎数据中台产品双月刊涵盖「大数据研发治理套件 DataLeap」「云原生数据仓库 ByteHouse」「湖仓一体分析服务 LAS」「云原生开源大数据平台 E-MapReduce」四款数据中台产品的功能迭代、重点功能介绍、平台最新... 支持创建治理方案及治理规则管理- **复盘管理:** 业务根据自身需要去识别任务是否需要复盘,或者仅仅做问题登记。除此之外,业务还可以用复盘管理能力做内部管理- **报警归因:** 提供所有报警明细,方便查看是...
ELT in ByteHouse 实践与展望
谈到数据仓库, 一定离不开使用 Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用 Extract-Transform-L... Server 端建立 worker 健康度管理类,可以快速获取 worker group 的健康度信息。包括 cpu、内存、运行 query 数量等信息。* 自适应调度。每个sql 根据 worker 健康度动态的进行worker选择以及计算节点并发度控制。...
「火山引擎」数据中台产品双月刊 VOL.04
**火山引擎数据中台产品双月刊**涵盖「大数据研发治理套件 DataLeap」「云原生数据仓库 ByteHouse」「湖仓一体分析服务 LAS」「云原生开源大数据平台 E-MapReduce」四款数据中台产品的功能迭代、重点功能介绍、平台... 便于用户更加灵活的创建、退订集群。- **【更新** **EMR** **软件** **栈** **】** - **新增** **EMR** **软件** **栈** **3.1.1:** StarRocks 集群全量公开发布;新增 Phoenix 组件,版本为 5.1.3,作...
元数据迁移
1 迁移和部署 Apache Hive 到火山引擎 EMRApache Hive 是一个开源的数据仓库和分析包,它运行在 Apache Hadoop 集群之上。Hive 元存储库包含对表的描述和构成其基础的基础数据,包括分区名称和数据类型。Hive 是可以... 数据库和 Metastore 服务三种: 内置数据库作为 Hive 元数据建议只应用于开发和测试环境。 使用火山引擎 RDS 作为 Hive 元数据 外置数据库可以是火山引擎的 RDS 数据库或者客户在 ECS 上部署的数据库实例。 创建集...
返回数据结构
本文主要描述镜像仓库 OpenAPI 的通用返回数据结构。 Registry参数名 类型 示例值 描述 Name String test-registry 镜像仓库实例名称。 Type String Basic 镜像仓库实例类型,参数值说明如下:Basic:基础版实例。仅部... {"Phase": "Running","Conditions": ["Ok"]} 镜像仓库实例状态,由 Phase 和 Conditions 组成。合法的 Phase 和 Conditions 组合如下所示: {Creating, [Progressing]}:创建中 {Running, [Ok]}:运行中 {Running, [D...
