超市数据仓库需求分析
 社区干货
社区干货
浅谈大数据建模的主要技术:维度建模 | 社区征文
也为我们后面讲Hadoop 数据仓库实战打下基础。## 维度建模关键概念### 度量和环境维度建模是支持对业务过程的分析,所以它是通过对业务过程度量进行建模来实现的。> **那么,什么是度量呢?**实际上,我们通过和业务方、需求方交谈,或者阅读报表、图表等,可以很容易地识别度量。考虑如下业务需求:- 店铺上个月的销售额如何?- 店铺库存趋势如何?- 店铺的访问情况如何( pv,uv) ? - 店铺访问的熟客占比多少?**这里的销...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
今天给大家一起分享下有着悠久历史的数据仓库的一些思考由三部分组成为什么,搭建数据仓库是什么,数据仓库定义怎么做,如何搭建数仓# 一:为什么,搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效... 相对稳定的【核心业务数据】 数据仓库的数据主要供[企业决策](https://wiki.mbalib.com/wiki/%E4%BC%81%E4%B8%9A%E5%86%B3%E7%AD%96 "企业决策")分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据...
观点 | 数仓领域的未来趋势解读
云原生等成为数据仓库发展关键词,也因此演变出不同的数仓发展路径。> > > > > **在字节跳动十年发展历程中,各类业务数据量膨胀,不断挑战数据能力边界,也让字节跳动在数据链路优化处理、提升分析效率、数据仓库... 我国大数据产业规模预计将突破3万亿元。 越来越多企业正在探索自身数字化转型,政务、金融等各行业也在不断进行数字化产业升级,对数据仓库的易用性、性能等提出了更高的要求。**本篇从业务需求和技术趋势...
浅谈数仓建设及数据治理 | 社区征文
而数据仓库只是中间集成化数据管理的一个平台。**源数据**:此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。**数据仓库**:也称为细节层,DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。**数据应用**:前端应用直接读取的数据源;根据报表、专题分析需求而计算生成的数据。数据仓库从各数据源...
 特惠活动
特惠活动
 超市数据仓库需求分析-优选内容
超市数据仓库需求分析-优选内容
 超市数据仓库需求分析-相关内容
超市数据仓库需求分析-相关内容
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。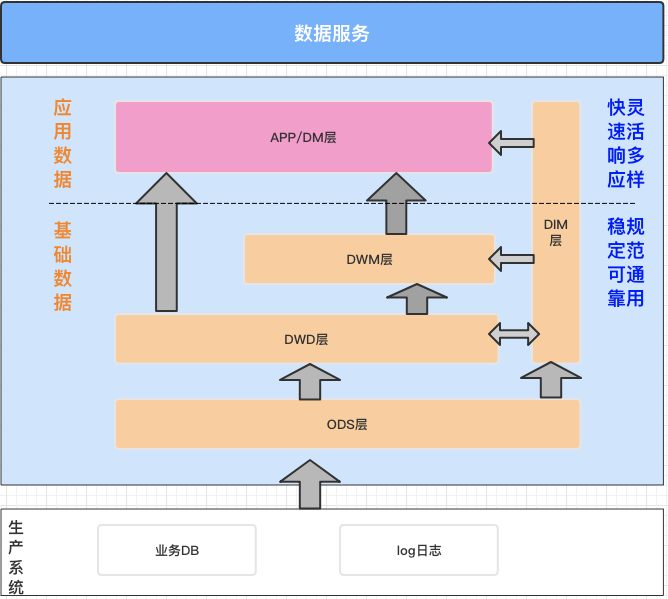本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成...
应用场景
数据组件,100%开源兼容,支持平滑迁移和长期演进。提供企业级组件优化和管控能力,帮助企业开发运维降本增效。一个架构支撑完整能力的数据湖仓方案,支持EB级别的数据仓库、湖内建仓、湖仓一体等。配合火山引擎大数据研发治理套件DataLeap和全域数据集成DataSail等产品,可实现一站式数据集成研发治理方案。 2 实时数仓实时数仓对数据实时性,data serving,并发等都有较高的要求,离线分析系统无法满足该类需求。实时数仓场景具备如下...
ByConity 技术详解之 ELT
而把大部分的转换操作留给分析阶段。相比起前者(ETL),它不需要过多的数据建模,而给分析者提供更灵活的选项。ELT已经成为当今大数据的处理常态,它对数据仓库也提出了很多新的要求。 ### 资源重复的挑战![p... .into outfile的组合来满足需求。## 未来规划针对ELT混合负载,ByConity 0.2.0版本目前只是牛刀小试。后续的版本中我们会持续优化查询相关的能力,ELT为核心的规划如下:### 故障恢复能力- 算子Spill ...
20000字详解大厂实时数仓建设 | 社区征文
接下来我们分析下目前实时数仓建设比较好的几个案例,希望这些案例能够给大家带来一些启发。### 1. 滴滴顺风车实时数仓案例滴滴数据团队建设的实时数仓,基本满足了顺风车业务方在实时侧的各类业务需求,初步建立... {数据域缩写}_[{业务过程缩写}]_[{自定义表命名标签缩写}]`- {业务/pub}:参考业务命名- {数据域缩写}:参考数据域划分部分- {自定义表命名标签缩写}:实体名称可以根据数据仓库转换整合后做一定的业务抽象的名称...
干货 | 看 SparkSQL 如何支撑企业级数仓
数据仓库的所有特性,并且 Hive 的 SQL 服务器是目前使用最广泛的标准服务器。虽然 Hive 有非常明显的优点,可以找出完全替代 Hive 的组件寥寥无几,但是并不等于 Hive 在目前阶段是一个完全满足企业业务要求的组件,很多时候选择 Hive 出发点并不是因为 Hive 很好的支持了企业需求,单单是因为暂时找不到一个能支撑企业诉求的替代服务。# 企业级数仓构建需求数仓架构通常是一个企业数据分析的起点,在数仓之下会再有一层数据湖...
ELT in ByteHouse 实践与展望
同时基于营销需求,他们会根据用户增长的模型以及销售方法论,收集用户在端内的操作行为,进行后台的查询分析。而这种查询分析底层对接了ByteHouse的大数据引擎,最后实现秒级甚至是亚秒级分析的决策。整个过程包括智能诊断、智能规划以及策略到投放效果评估闭环,最终实现智能营销和精细化运营。### ETL场景#### ELT与ETL的区别- ETL是用来描述将资料从来源端经过抽取、转置、加载至目的端(数据仓库)的过程。Transform通常...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
在实时数据接入、大宽表聚合查询、海量数据下复杂分析计算、多表关联查询场景下有非常好的性能。主要的的应用场景如下:# 2.技术趋势和挑战## 业务需求企业级数据仓库场景中,需要融...
干货 | 这样做,能快速构建企业级数据湖仓
火山引擎 EMR 是开源大数据平台 E-MapReduce,提供企业级的 Hadoop、Spark、Flink、Hive、Presto、Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100% 开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,能帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。火山引擎 EMR 有以下 4 个特点:* **开源兼容&开放环境** :100% 兼容社区主流版本,满足应用开发需求;同时提供半托管的白盒...
ELT 支持
ByteHouse 作为云原生数据仓库,逐渐引入了对 ELT(Extract-Load-Transform,提取-加载-转换)的支持。 这使得用户可以避免维护多个异构数据系统。 概述ELT 专注于将经过最少处理的数据加载到数据仓库中,并将大部分转换操作留在分析阶段。 它不需要大量的数据建模,并为分析师提供了更灵活的选择。 ELT 已成为当今处理大数据的规范,它对数据仓库提出了许多新的要求。 查询队列在集群中,我们可能会遇到节点出现不健康状态,或者超载的情...
