数据仓库中数据分割的目的
 社区干货
社区干货
ELT in ByteHouse 实践与展望
谈到数据仓库, 一定离不开使用 Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用 Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的 ETL 系统,因而维护成本较高。现在,以火山引擎 ByteHouse 为例的云原生数据仓库,凭借其强大的计算能力、可扩展性,开始全面支持Extrac...
ByConity 技术详解之 ELT
ByConity 作为云原生数据仓库,从0.2.0版本开始逐步支持 Extract-Load-Transform (ELT),使用户免于维护多套异构数据系统。本文将介绍 ByConity 在ELT方面的能力规划,实现原理和使用方式等。## ETL场景和方案### ELT与ETL的区别- ETL:是用来描述将数据从来源端经过抽取、转置、加载至目的端(数据仓库)的过程。Transform通常描述在数据仓库中的前置数据加工过程。 实体建模法实体建模法并不是数据仓库建模中常见的一个方法,它来源于哲学的一个流派。从哲学的意义上说,客观世界应该是可以细分的,客观世界应该可以分成由一个个实...
ELT in ByteHouse 实践与展望
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。 将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。 传统的数据转换过程一般采用Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的ETL系统,因而维护成本较高。现在,以火山引...
 特惠活动
特惠活动
 数据仓库中数据分割的目的-优选内容
数据仓库中数据分割的目的-优选内容
 数据仓库中数据分割的目的-相关内容
数据仓库中数据分割的目的-相关内容
浅谈大数据建模的主要技术:维度建模 | 社区征文
还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数据仓库中的数据?- 怎么组织才能使得数据的使用最为方便... **这里的销售额、库存、访问量、熟客量就是度量。**但是,单单谈论度量,是没有意义的。度量和环境这两个概念构成了维度建模的基础。而所有维度建模也正是通过对度量和及其上下文和环境的详细设计来实现的。#...
观点|SparkSQL在企业级数仓建设的优势
数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技术组件,而是一种设计理念。Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式任务执行,以及元数据中心,这一系列组合让Hive完整的具备了构建一个企业级数据仓库的所有特性,并且Hive的SQL服务器是目前使用最广泛的标准服务器。...
SparkSQL 在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以及元数据中心...
干货 | 看 SparkSQL 如何支撑企业级数仓
目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN 上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以及元数据中心,这一系列组合让 Hive 完整的具备了构建一个企业级数据仓库的所有特性,并且 Hive...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... 分布式运算符拆分等常见的启发式优化能力。* CBO:基于成本的优化能力。支持:Join Reorder、Outer-Join Reorder、Join/Agg Reorder、CTE、Materialized View、Dynamic Filter Push-Down、Magic Set 等基于成本的优...
一文读懂火山引擎云数据库产品及选型
是数据仓库系统的主要应用,支持复杂的分析操作,侧重分析决策支持,并且提供直观易懂的查询结果,主要跟大数据系统关系紧密。OLTP 与 OLAP 系统之间通常会使用 ETL 进行连接。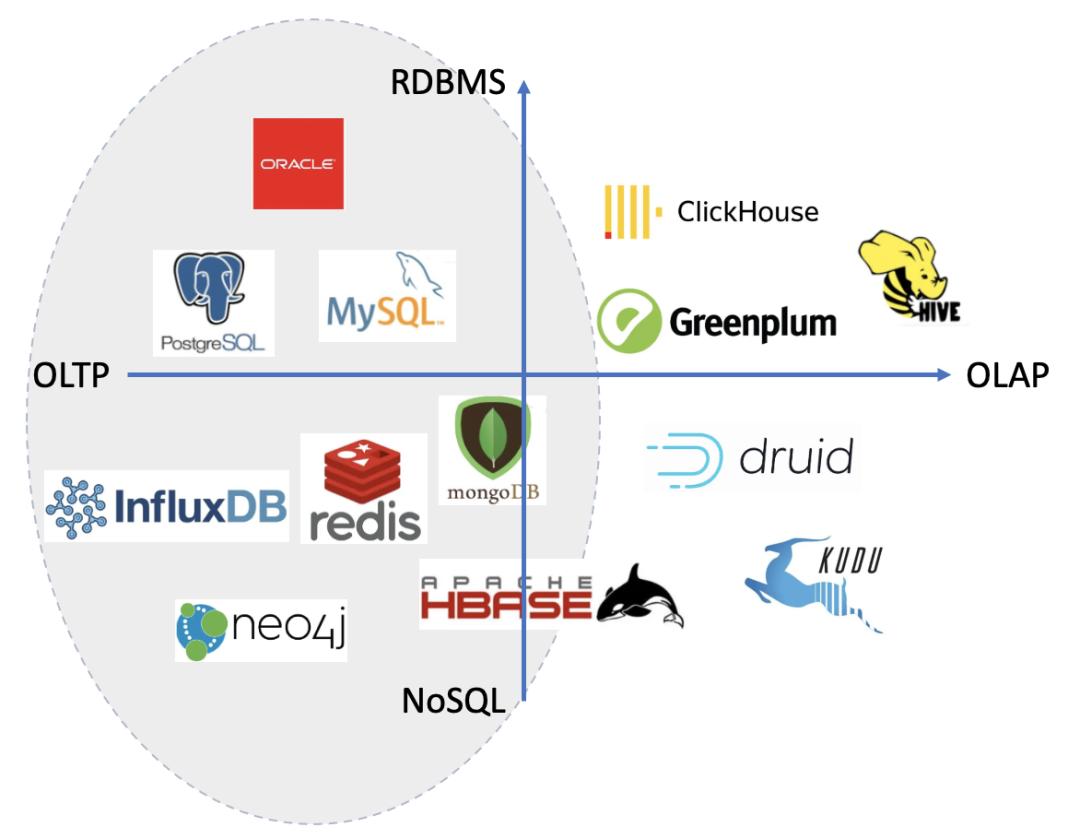**本文主要侧重于 OLTP 系统的选型指南,也就是上图中圆圈中的范围,包含关系型数据库与 NoSQL 数据库。**OLAP 与大数据相...
ByConity 替换 ClickHouse 构建 OLAP 数据平台,资源成本大幅降低
ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致性等多种需求的同时,提供优异的查询,写入性能。文章来源|ByConity 开源社区GitHub |h... 分成两部分,一部分是离线,一部分是实时。在**离线场景**中,我们使用 DataX 把 Kafka 的数据集成到 Hive 数仓,再生成 BI 报表。BI 报表使用了 Superset 组件来进行结果展示;在 **实时场景** 中,一条线使用...
ByConity 替换 ClickHouse 构建 OLAP 数据平台,资源成本大幅降低
作者|程伟,MetaAPP 大数据研发工程师【项目地址】GitHub |https://github.com/ByConity/ByConity> ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致... 分成两部分,一部分是离线,一部分是实时。在**离线场景**中,我们使用 DataX 把 Kafka 的数据集成到 Hive 数仓,再生成 BI 报表。BI 报表使用了 Superset 组件来进行结果展示;在**实时场景**中,一条线使用 GoSink...
火山引擎ByteHouse:4000字总结,Serverless在OLAP领域应用的五点思考
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群作为云计算的下一个迭代,Serverless可以使开发者更专注于构建产品中的应用,而无需考虑底层堆栈问题。伴随着近年来相关技术成熟度的增加,市场对Serverless的接受程度也变得越来越高。可以说时至今日,Serverless已迈入了向成熟稳定方向发展的高速轨道。作为一款火山引擎推出的云原生数据仓库,ByteHouse基于开源ClickHouse构建,并在字节跳...
