数据仓库中数据的存储期限
 社区干货
社区干货
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
ByteHouse 是字节跳动自主研发的云原生数据仓库产品,在开源 ClickHouse 引擎之上做了技术架构重构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等功能。在可扩展性、稳定性、可运维性、性能以及资源利用率方面都有巨大的提升。 截至 2022 年 2 月,ByteHouse 在字节跳动内部部署规模超过 1 万 8000 台,单集群超过 2400 台。经过内部数百个应用场景和数万用户锤炼,并在多个外部企业客户中得到推广应用。##...
浅谈大数据建模的主要技术:维度建模 | 社区征文
这里的一级类目即为一个维度 。类似的是,“上月”为另一个维度,而销售额明显是事实。### 事实表> **事实表是维度模型中的基本表,或者说核心表**事实上,业务过程的所有度量在维度建模中都是存储在事实表中的,除此之外,事实表还存储了引用的维度。事实表通常和一个 **企业的业务过程** 紧密相关,由于一个企业的业务过程数据构成了其所有数据的绝大部分,因此事实表也通常占用了数据仓库存储的绝大部分。比如对于某个超市来...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。## 服务层服务层包括了所有与用户交互的内容,包括用户管理、... Part 的元数据信息记录表所对应的所有 data file 的元数据,主要包括文件名,文件路径,partition, schema,statistics,数据的索引等信息。元数据信息会持久化保存在状态存储池里面,为了降低对元数据库的访问压力,对...
 特惠活动
特惠活动
 数据仓库中数据的存储期限-优选内容
数据仓库中数据的存储期限-优选内容
 数据仓库中数据的存储期限-相关内容
数据仓库中数据的存储期限-相关内容
浅谈数仓建设及数据治理 | 社区征文
按照数据流入流出的过程,数据仓库架构可分为:**源数据**、**数据仓库**、**数据应用**。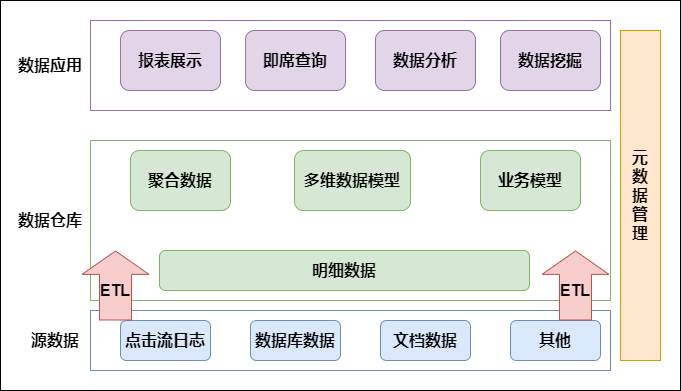数据仓库的数据来源于不同的源数据,并提供多样的数据应用,数据自下而上流入数据仓库后向上层开放应用,而数据仓库只是中间集成化数据管理的一个平台。**源数据**:此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储...
观点 | 数仓领域的未来趋势解读
字节跳动数据平台> > > 数据仓库发展历程很久,随着云计算等技术发展以及海量数据应用场景等出现,对数据仓库提出全新要求,高性能、实时性、云原生等成为数据仓库发展关键词,也因此演变出不同的数仓发展路径。> > > > > **在字节跳动十年发展历程中,各类业务数据量膨胀,不断挑战数据能力边界,也让字节跳动在数据链路优化处理、提升分析效率、数据仓库选型、数据引擎架构搭建等层面积累丰富经验。**> > > > ...
ELT in ByteHouse 实践与展望
谈到数据仓库, 一定离不开使用 Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用 Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的 ETL 系统,因而维护成本较高。现在,以火山引擎 ByteHouse 为例的云原生数据仓库,凭借其强大的计算能力、可扩展性,开始全面支持Extrac...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
火山引擎ByteHouse:分析型数据库如何设计列式存储
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 列式存储通过支持按列存储数据,提供高性能的数据分析和查询。作为云原生数据仓库的 ByteHouse,也采用列式存储设计,保证读写性能、支持事务一致性,又适用大规模的数据计算,为用户提供极速分析体验和海量数据处理能力,提升企业数字化转型能力。# 列式存储介绍分析型数据库中的列式存储,是一种数据库的物理存储结构,它是根据数据的列...
观点|SparkSQL在企业级数仓建设的优势
管理元数据服务的Hive Metastore,以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式任务执行,以及元数据中心,这一系列组合让Hive完整的具备了构建一个企业级数据仓库的所有... 数仓架构通常是一个企业数据分析的起点,在数仓之下会再有一层数据湖,用来做异构数据的存储以及数据的冷备份。但是也有很多企业,特别是几乎完全以结构化数据为主的企业在实施上会把数据湖和企业数仓库合并,基于某个...
从思考到实践,企业级大数据平台的构建之路
点击上方👆蓝字关注我们! 伴随着移动互联网、5G、AI、IoT 的飞速发展,企业数据建设正处于更大规模和更多样的变化趋势中。传统自建数据仓库,在企业数据体量持续增长、业务时效性持续提升的... **开源大数据生态**和 **源于字节跳动内部的智能实时湖仓**两个方面详细介绍 **如何构建企业级数据湖仓**,剖析火山引擎大数据平台的架构与实践。**活动时间**:2022/08/18(周四)19:30-21:00 *...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上)(中)精彩回顾: ## ByteHou...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
