数据仓库增量导入
 社区干货
社区干货
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎... 务节点的部分功能例如聚合最终结果需要下放到计算组中的计算节点中去。 来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的ETL系统,因而维护成本较高。现在,以火山引擎ByteHouse为例的云原生数据仓库,凭借其强大的计算能力、可扩展性,开始全面支持Extract-Load-Transform (ELT)的能力,从而使用户免于维护多套异构系统。具体而言,用户可以将数据导入后,通过自定义的SQL...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
 特惠活动
特惠活动
 数据仓库增量导入-优选内容
数据仓库增量导入-优选内容
 数据仓库增量导入-相关内容
数据仓库增量导入-相关内容
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
DataLeap数据仓库流程最佳实践
# 前言本实验以DataLeap on LAS为例,实际操作火山引擎数据产品,完成数据仓库的构建。# 关于实验* 预计部署时间:50分钟* 级别:初级* 相关产品:大数据开发套件、湖仓一体分析服务LAS* 受众: 通用## 环境说... 本Demo中以湖仓一体LAS的样例数据为实验数据(TPC-DS中的样例表:https://www.volcengine.com/docs/6492/81953)## 步骤3:导入样例数据,因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业... 数据层具体实现>使用四张图说明每层的具体实现- **数据源层ODS** 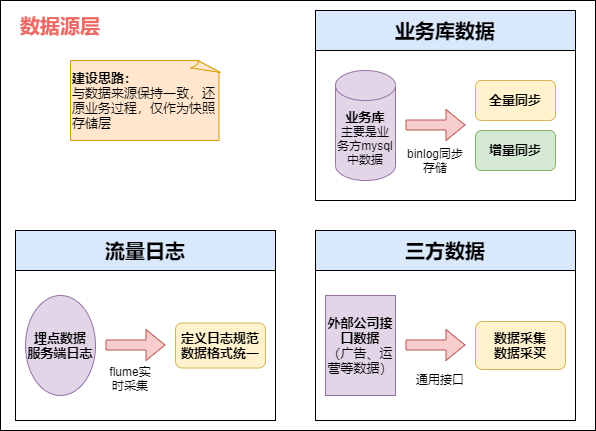数据源层主要将各个业务数据导入到大数据平台,作为业务数据的快...
干货 | 这样做,能快速构建企业级数据湖仓
Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走... 数据通过 Kafka 流入 Flink 进行在线特征抽取,然后把在线特征放在 Redis。同时在线部分的增量数据可用 TensorFlow 进行增量训练,把增量模型也导入模型服务里。模型服务根据原来批式训练出来的模型和增量模型做成实...
应用场景
应用场景1 云原生数据湖仓数据湖仓是一种结合了数据湖和数据仓库的新型数据架构,实现了更加灵活、高效和可扩展的数据管理,能够协助企业更好的理解和使用数据资产,提升业务价值。以互联网行业为例,企业需要搭建数据... 由Doris/StarRocks对数据应用层提供服务,支持在线、离线查询分析,支持几十万级QPS。 3 离线/批量数据分析海量数据离线处理分析是大数据分析系统中的通用场景,企业将多种类型业务系统数据源的数据进行采集、导入、...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.06
火山引擎数据中台产品双月刊涵盖「大数据研发治理套件 DataLeap」「云原生数据仓库 ByteHouse」「湖仓一体分析服务 LAS」「云原生开源大数据平台 E-MapReduce」四款数据中台产品的功能迭代、重点功能介绍、平台最新... **【** **实时导入——HaKafka** **】**- **原架构痛点** - 节点故障:当集群机器数量到达一定规模以后,基本每周都需要人工处理节点故障。对于单副本集群在某些极端 case 下,节点故障甚至会导致数据丢失...
字节跳动基于数据湖技术的近实时场景实践
Hudi不仅仅是数据湖的一种存储格式(Table Format),而是提供了Streaming 流式原语的、具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。 - Hudi 支持各类计算、查询引擎(Fli... Hudi 使用 Timeline Service机制对数据版本进行管理,实现了数据近实时增量读、写。 - Hudi 支持 Merge on Read / Copy on Write 两种表类型,以及Read Optimized / Real Time 两种Query模式,用户可以在海量的...
