数据库更新后,实体和/或字段定义不匹配。
 社区干货
社区干货
只需五步,ByteHouse实现MaterializedMySQL能力增强
MaterializedMySQL数据库引擎,用于将MySQL中的表映射到ClickHouse中。ClickHouse服务作为MySQL副本,读取Binlog并执行DDL和DML请求,实现了基于MySQL Binlog机制的业务数据库实时同步功能。**这样不依赖其他数据同... ClickHouse社区版通过DDL语句在ClickHouse上创建一个database,并将MySQL中的指定的一个database的全量数据迁移至ClickHouse,并实时读取MySQL的binlog日志,将MySQL中的增量数据实时同步至ClickHouse中。 ...
VikingDB:大规模云原生向量数据库的前沿实践与应用
而向量数据库又是以 embedding 作为核心概念,并围绕其提供存储检索能力的基础软件,因此可以说 **向量数据库是 AI 原生应用程序的基础设施** 。为了更好地胜任 AI 基础设施的角色和贴合大模型的生态,VikingDB ... 以应对不同的需求场景:* **静态库**:数据集固定,后续不再写入或更新。* **批式库**:周期性的全量更新,比如模型版本迭代后,需要更新所有向量;也有些场景中,不需要更新所有向量,仅不断地追加。批式库通过 hdfs ...
分布式数据库TiDB的设计和架构
但此类数据库的局限在于无法处理交易类数据及复杂业务逻辑的特性,限制其在非互联网领域的发展。**2013年以后**2013年以来,有个新的概念为分布式关系型数据库(NewSQL),它是兼具NoSQL扩展性又不丧失传统关系型数... 特别是连续写入的数据中某些索引值也是连续的(比如 update time 这种按时间递增的字段),会在很少的几个 Region 上形成写入热点,成为整个系统的瓶颈。同样,如果所有的数据读取操作也都集中在很小的一个范围内 (比如...
阿里巴巴的 Java 开发手册(黄山版)来了
居然已经更新到了黄山版。上次看这本小册子的时候还是上次——19年的时候我看的华山版的。再往前那就是17年的第一版了,当时是在阿里的公众号下载的,后来还买了实体的《Java开发手册》和《码出高效》两本书。其... (即未经预先定义的常量)直接出现在代码中。```// 反例: 开发者 A 定义了缓存的 key。 String key = "Id#taobao_" + tradeId; cache.put(key, value); // 开发者 B 使用缓存时直接复制少了下划线,// 即 key 是...
 特惠活动
特惠活动
 数据库更新后,实体和/或字段定义不匹配。-优选内容
数据库更新后,实体和/或字段定义不匹配。-优选内容
 数据库更新后,实体和/或字段定义不匹配。-相关内容
数据库更新后,实体和/或字段定义不匹配。-相关内容
Elasticsearch进阶篇@记kibana执行dsl脚本实战过程 | 社区征文
需要像传统DBMS关系型数据库一样,实现在海量数据中作模糊搜索,全文搜索,又需要有一定程度的检索效率,突破传统DBMS性能瓶颈,那么ES很适合与关系型数据库形成互补,ES在搜索领域拥有强悍的性能,而传统DBMS关系型数据库... 多字段自定义更新、自定义reindex、自定义数组字段动态添加...```https://www.elastic.co/guide/en/elasticsearch/painless/6.8/painless-regexes.html```当然基于脚本引擎手动开发插件也是可以实现的。```h...
search_by_id
更新时间最长滞后 20s,不能立即在 Index 检索到。 当请求参数 filter 配置时,表示混合检索;当请求参数 filter 没有配置时,表示纯向量检索。 前提条件 通过 create_collection 接口创建数据集时,定义字段 fields ... Data 实例包含的属性如下表所示。 属性 说明 id 主键 id。 fields 请求返回中的 fields 字段,是具体的数据,字典类型。 score 表示找到的向量和输入的向量的匹配程度。
一文读懂火山引擎云数据库产品及选型
业界将关系型数据库与 NoSQL 数据库的优势进行了融合,出现了 NewSQL 数据库,随着云原生技术的入场与爆发,又有了云原生数据库。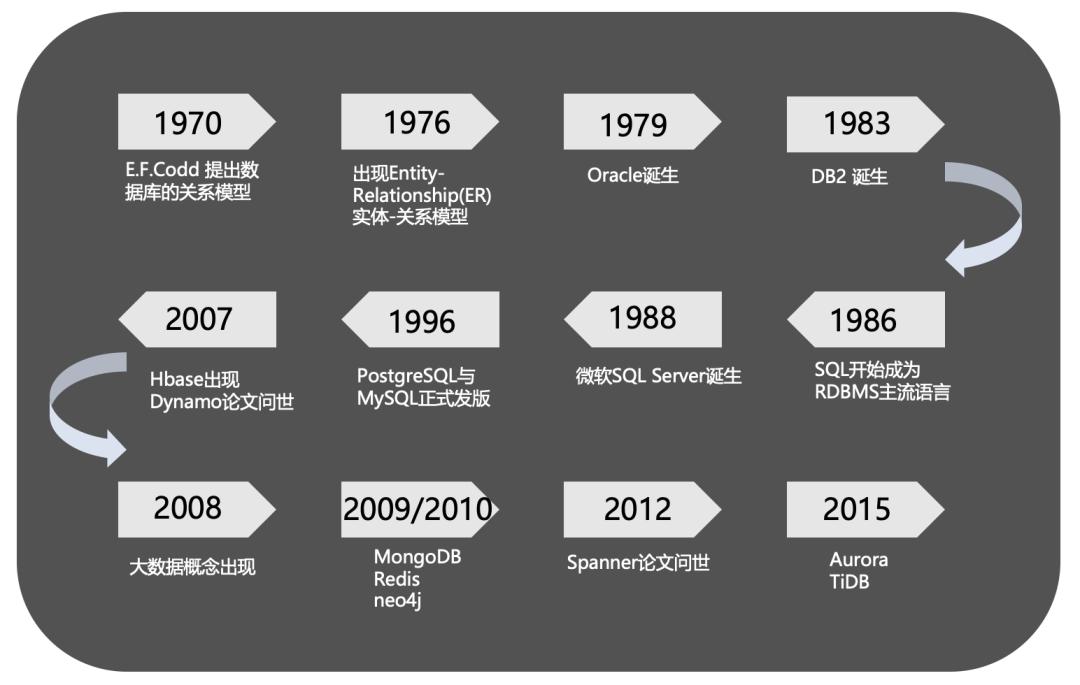**关系型数据库**将数据存储于二维表格之中,数据以行为单位,一行数据表示一个实体信息,每一行数据的属性都是相同的,通过 SQL 语言进行操作,容易理解,广泛应用于企业的...
MySQL_to_Doris 整库实时
一键实时整库同步方案支持全增量一体化同步,本实践中,先将 MySQL 源端全量数据通过离线任务同步方式迁移,然后再通过实时同步增量任务,将增量数据采集至目标端 Doris 数据库表中。您也可以选择单独进行实时增量数据... 将全量和增量数据同步至 Doris 任务。 1 前置操作已开通并创建 DataLeap 项目,创建的全量增量任务均会同步到该项目下。详见新建项目。 已创建合适资源规格的独享数据集成资源组,并将其绑定至创建成功的 DataLeap ...
达梦@记一次国产数据库适配思考过程|社区征文
字段列名不存在的异常。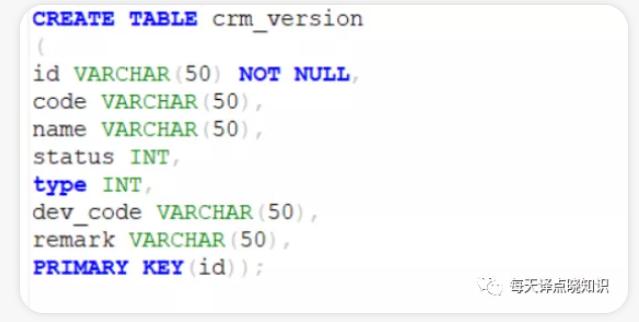若是通过**Mysql或Oracle或其他数据库,文件等方式迁移导入... 这样我们就能极其简易的指定 databaseId,很多小伙伴肯定会说为什么需要这样去指定?其背后的原理又是怎样的,我们是否能够扩展并自定义 databaseId?框架这层的应用真能够提供的这么 perfect 吗?在上一个Q-A中,我们...
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
可以看到在Java定义的标准接口访问中,先创建一个connection完成存储介质,然后完成connection后续操作。性能问题导致单次请求实时创建connection的性能较差。因此我们往往通过维护一个存有多个connection的连接池,将connection的创建与使用分开以提升性能,因而也衍生出很多数据库连接池,例如C3P0,DBCP等。# **3. Hive 的 JDBC 实现**构建SparkSQL服务器最好的方式是用如上Java接口,且大数据生态下行业已有标杆例子,即Hive S...
[数据库论文研读] HTAP行列混存 & 智能转换
且一个事务中多为混合操作(read/write/update/delete),而OLAP中根本没有“事务”的概念,基本上可以认为只有read/scan操作。- OLTP应用在存储侧的layout一般为行存,OLAP应用则一般为列存因为OLTP和OLAP的差异,... 然后再实现一个coordinator(sync method)来协调两侧。**笔者认为,这么做无非是把外边的多套子系统称为子模块,取消了原本的后台数据同步机制,整合到一个黑盒里,称为HTAP数据库罢了。这么做的话数据仍然要存两份(row...
数据集常见 FAQ
1. 数据集 1.1 常见报错信息修改了 hive 表字段类型修改,同步不成功是什么问题?现象举例1:hive 数据在原数据库中不为空,而同步到DataWind这边,不管是数据集预览,还是可视化查询,结果都是空值。数据库有值:数据集同... 类型转换不正常。 解决办法: 修改hive表的字段类型之后,需要重新灌入数据到hive表; 然后到DataWind这边编辑、保存对应的数据集,再重新同步数据。 说明 编辑、保存数据集是用来更新数据集模型中的字段类型,这一步操...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
Rowset 有版本号的概念,同一个 Primary Key 对应的行可能在不同的 Rowset 中存在多份,读的时候多个版本的数据会按照不同的 Merge 算法合并为一份。Tablet 的 Commit Version 为该 Tablet 下 Rowset 的最大版本号,比... 根据不同的合并算法,Krypton 支持了三种表模型:1. Duplicate Table:相同的行存在多份。2. Unique Table:系统需要定义 Primary Key(PK),相同的 PK 只会存在一份,高版本覆盖低版本。3. Aggregate Table:和 Uni...
