空气流动清除了回填任务,调度程序不会选择它们。
 社区干货
社区干货
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删和回填特征。本文将介绍字节跳动如何通过 Iceberg 数据湖支持... 并且使得 GPT-3 在自然语言处理任务中取得了令人瞩目的成就。 然而随着模型参数的增长,模型的大小也成为一个问题。为了解决这个问题,人们开始尝试模型小型化的方法。Chinchilla 就是一种模型小型化的尝试,相...
敏捷研发、分布自治:火山引擎业务为先的数据中台新模式
改善组织中数据管理者与数据使用者之间的数据流动,这其中的核心是与数据消费者(业务方)构建更好的合作关系,帮助业务增长;- **加速数据价值交付**我们不但要解决交付问题,而且要确保最终交付的数据是有价值的... 比如增加了调度系统、数据同步系统等。- **第二阶段:工具整合,提供统一的数据开发平台**数据开发平台是研发导向的,目标是提高数据研发效率,从而帮助开发者提效。- **第三阶段:全链路数据中台**这里要解...
Apache Pulsar 在火山引擎 EMR 的集成与场景
就不会有“集群状态数据受影响”相关的顾虑了,减少了运维的风险与成本。 在 Stateless 集群的场景下,用户甚至可以选择按需去持有集群,即:需要使用计算资源的时候,创建一个集群;不需要使用计算资源的时候,将集群释放。例如如果用户的数据生产 ETL 作业集中在凌晨执行,那么可以在当日的数据生产任务执行前将集群创建出来,然后用这个集群执行一系列的 ETL 作业,而在所有作业都成功执行完成后,再把这个集群释放掉。而到第二天凌...
字节跳动湖平台在批计算和特征场景的实践
> 本文整理自火山引擎云原生计算研发工程师刘纬在 DataFunCon 2022 上的演讲。随着业务的发展,字节跳动特征存储已到达 EB 级别,日均增量 PB 级别,每天训练资源量级为百万 Core。随之而来的是内部业务方对原始数据存储、特征回填需求、降低成本、提升速度等需求的期待。本次分享将围绕问题背景、选型& Iceberg 简介、基于 Iceberg 的实践及未来规划展开。>> >作者:刘纬整理:王吉东,于惠# 问题背景### **用户使用流程...
 特惠活动
特惠活动
 空气流动清除了回填任务,调度程序不会选择它们。-优选内容
空气流动清除了回填任务,调度程序不会选择它们。-优选内容
 空气流动清除了回填任务,调度程序不会选择它们。-相关内容
空气流动清除了回填任务,调度程序不会选择它们。-相关内容
我的AI学习之路----拥抱Tensorflow 拥抱未来|社区征文
用户可以清晰地看到张量流动的每一个环节。可以轻松地在CPU/GPU上部署,进行分布式计算,为大数据分出现提供计算能力的支撑。跨平台性好,灵活性强。TensorFlow不仅在Linux、Mac、和Windows系统中运行,甚至可以再终... 在程序运行时就会直接执行相关运算得到结果。在Tensorflow中需要预先定义各种变量,建立相关数据流图,在数据流图中定义各种变量之间的关系,以此完成图的定义。此时,图只是运算规则,没有任何实际数据,需要把运算的输...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删和回填特征。本文将介绍字节跳动如何通过 Iceberg 数据湖支持... 并且使得 GPT-3 在自然语言处理任务中取得了令人瞩目的成就。然而随着模型参数的增长,模型的大小也成为一个问题。为了解决这个问题,人们开始尝试模型小型化的方法。Chinchilla 就是一种模型小型化的尝试,相较...
火山引擎发布数智平台VeDI,帮助企业释放数字化增长潜能
选择对应的行业分析场景模板,就可以一键生成数据看板;智能数据洞察平台DataWind,升级为一站式数据分析与协作平台,在数据触达、数据分析、数据协作和数据沉淀等方面,与飞书高度协同。一个完备的数据智能平台,包括... 分布式海量秒级调度和数据全链路智慧运维;在数据治理方面,可实现分布式自治、多维度健康评估、全链路治理、批流一体质量监控等;数据资产方面,可实现全链路数据资产快速接入、端到端高精准率血缘等;安全合规方面,可...
字节跳动云原生大数据平台运维管理实践
比如分布式大数据存储及各种任务执行引擎:Flink、Spark 及各种 ETL 的 OLAP 工具和调度 ETL 的任务调度工具,还有支撑工具引擎的运行日志监控系统和项目用户权限的辅助系统等;* **部署复杂** :这些系统的组件繁多,... 变更或删除,再通过 Filebeat 热加载的机制生成、加载成自己的日志采集规则。在 Filebeat 的部署形态中如果能够感知到集群的节点信息并拥有对应的权限,那么就可以部署成 DeamonSet 的方式,使整体资源占比更低,...
火山引擎云原生存储加速实践
在计算底座基础上会进行一些大数据任务以及 AI 训练任务,再往上就是各种各样的计算框架。- 底层是存储服务,目前来看存算分离是业界未来的趋势,对于云上一些标准的存储服务,可以分成以下三大类: - 第一类... 很多时候无法配合计算业务做大规模并发或者弹性调度。所以业界在整个计算业务和存储服务之间,又推出了一些存储和加速的中间件。比如 ALLUXIO 就是一个典型的存储加速的代表,另外 JuiceFS 本身也有很多缓存和加速的...
字节跳动湖平台在批计算和特征场景的实践
本文整理自火山引擎云原生计算研发工程师刘纬在 DataFunCon 2022 上的演讲。随着业务发展,字节跳动特征存储已到达 EB 级别,日均增量 PB 级别,每天训练资源量级为百万 Core。随之而来的是内部业务方对原始数据存储、特征回填需求、降低成本、提升速度等需求的期待。本次分享将围绕问题背景、选型& Iceberg 简介、基于 Iceberg 的实践及未来规划展开。作者|火山引擎云原生计算研发工程师-刘纬整理|王吉东、于惠...
基于火山引擎微服务引擎 MSE 的全链路灰度落地实践
需要将灰度流量精准调度在多个上下游依赖灰度服务实例,同时为保障整体业务闭环,允许灰度流量路由至服务的基线版本。要完成以上灰度流量的业务闭环,需在全链路服务调用过程中对灰度流量进行精准识别和路由控制。... 与泳道关联的路由策略需伴随版本发布的切流动作动态下发至泳道内的所有服务实例并及时生效,通过泳道染色规则生效策略控制版本发布节奏。**提供基准泳道概念并生成默认的泳道规则**:未匹配染色标记的流量将统...
云原生环境下的日志采集、存储、分析实践
提升可用性:索引可以异步创建,流量突发时创建索引慢不会影响存储写入速率。**索引管理和调度**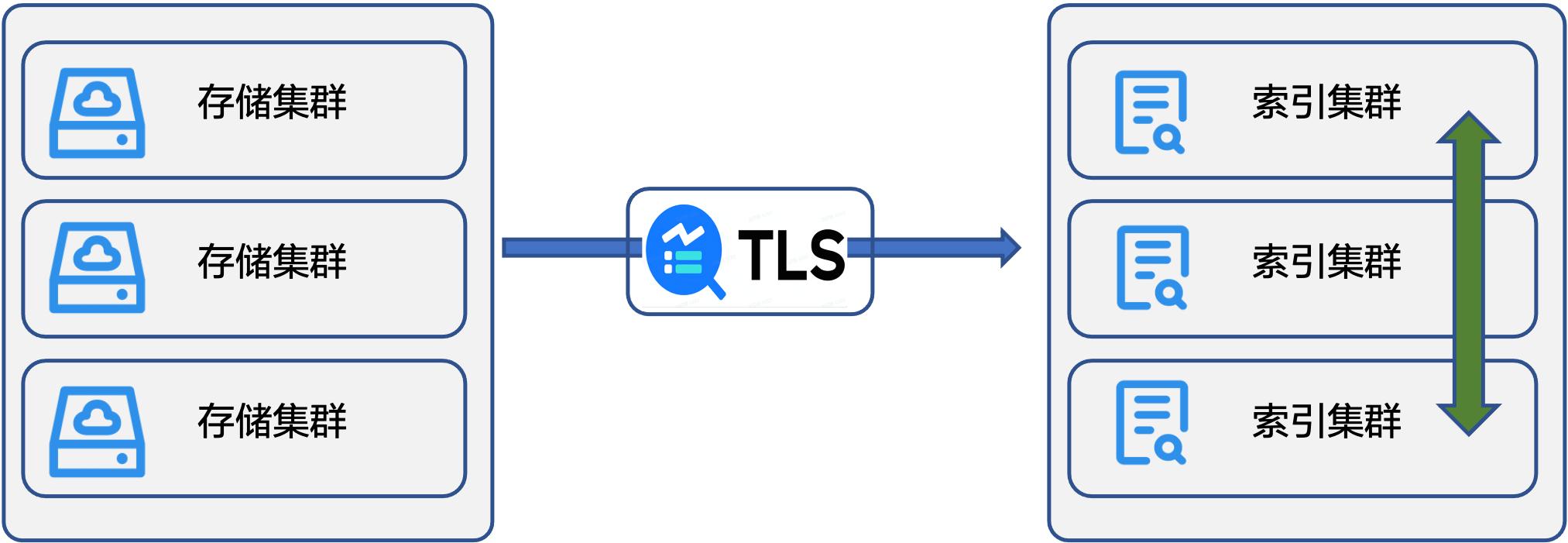索引的流量是不可预测的,因此我们在效率方面的另一个优化是支持索引的管理和调度,实现弹性伸缩,从而提升可用性,解决规模问题。我们的解决方案是在多个索引集群之间做数据流动,基于负载、...
字节跳动数据库的过去、现状与未来
其中计算层又被拆分出负责数据库流量调度、接入、鉴权的代理层以及数据库计算层。计算层中是数据库的一些运行实例,它兼容 MySQL、PG 和 MongoDB 等数据库引擎,是无状态的,可以动态地在数据中心里做分布和调度。最下方是存储层,我们把数据库日志、数据库 Page 和对应的处理逻辑都卸载到里面,它支持 HDD、SSD、PM。其次是日志和数据的分离。我们把数据库的 Wal 和 Page 放到不同介质里,来实现成本和性能之间的平衡。第三是读写...
