缺少的scikit-learn软件包
 社区干货
社区干货
初探金融风控中的信用评分卡搭建全流程 | 社区征文
数据质量与缺失情况、内部数据与外部数据是否可对应。1. 模型的交付时间:确定模型开发的紧迫程度、需要交付使用的最大容忍时间与最小容忍时间,以确保模型的正常交付。1. 模型评估指标:明确模型评估指标,确定指... 但是PMML封装后与直接调用scikit-learn包相比,结果的准确性可能会有一点损失,而复杂的模型,如Xgboost,其模型有几吉字节(GB)的规模,则PMML加载会慢一些。因此,PMML方式适合轻量级模型,即训练好的模型不是吉字节级别...
亚马逊云科技 -- AIGC 时代的数椐基础设施|社区征文
Scikit-learn等,可以选择熟悉的框架和算法来训练模型,并使用强大的分布式训练功能加速训练过程>> **可扩展的模型部署**:Amazon SageMaker 将模型部署到生产环境中,提供高可用性和可扩展性,支持多种部署选项,包括实时推理、批量推理和边缘推理,以满足不同应用场景的需求### Amazon Bedrock> Amazon Bedrock 是完全托管的服务,使用单个 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先人工...
人工智能与教育:机遇与挑战 | 社区征文
Scikit-learn 用于机器学习相关操作。- 加载包含学生数据的 CSV 文件,并进行数据预处理,将特征值和目标值分别存储在 X 和 y 中。- 使用 train_test_split 函数将数据集划分为训练集和测试集。- 创建一个线性回归模型,并使用训练集数据进行模型训练。- 使用模型对测试集数据进行预测,得到预测结果。- 使用 mean_squared_error 函数计算预测结果与真实结果之间的均方误差。- 打印均方误差。# 未来发展趋势 特惠活动
特惠活动
 缺少的scikit-learn软件包-优选内容
缺少的scikit-learn软件包-优选内容
 缺少的scikit-learn软件包-相关内容
缺少的scikit-learn软件包-相关内容
项目经验分享:机器学习在智能风控中的应用|社区征文
处理缺失值等工作,这些工作虽然枯燥乏味,但是也是不能省略的,提供的数据质量较低会直接导致机器学习的失败。下面我展示数据清洗部分代码。```# 数据清洗transaction_data = transaction_data.drop_duplicates(... 我使用了Apache Kafka和scikit-learn库来实现实时监测和预测。首先,要确保已经安装好了Apache Kafka和scikit-learn库,并完成配置,教程也很多,一搜就有。应用比较简单,但是使用中还要注意异常的处理,数据流量的控制...
探索AI的无限可能:从概念到实践 | 社区征文
以下则是我使用Python和机器学习库Scikit-learn实现的一个分类器,代码如下:```python# 导入所需的库 from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # 加载数据集 iris = load_iris() X = iris.data ...
保姆级人工智能学习成长路径|社区征文
scikit-learn(数据划分、常用模型、交叉验证等内容)、imblearn(不均衡数据的处理)、梯度提升树(最常用的如XGBoost、LightGBM、CatBoost)、NLP常用库(jieba:中文分词、nltk:英文文本处理、Gensim:获取词向量、CountVectorizer:获取n-gram表示)。 对于新手来说,学习过程中最重要的是不断重复学习,但需要注意的是单纯的重复是没有任何意义的。最忌讳的是无脑的重复。那什么是有效的学习呢?就是在每次重复翻看时,都有新的思考,并...
字节跳动端智能工程链路 Pitaya 的架构设计
Scikit-Learn)连接起来。同时MLX Notebook还在标准SQL的基础上拓展了MLSQL算子,可以在底层将SQL查询编译成可以分布式执行的工作流,完成从数据抽取,加工处理,模型训练,评估,预测,模型解释的Pipeline构建。P... 实时监控端上特征缺失、特征值异常、特征值偏移等情况,确保端上特征的正常生产。* 端上特征地图:为了实现跨团队的特征共享与协作,特征管理模块提供端上特征地图的能力,让不同业务团队都可以通过特征地图对设备上的...
浅谈AI机器学习及实践总结 | 社区征文
Q-learning,SARSA,深度强化网络、蒙特卡洛学习...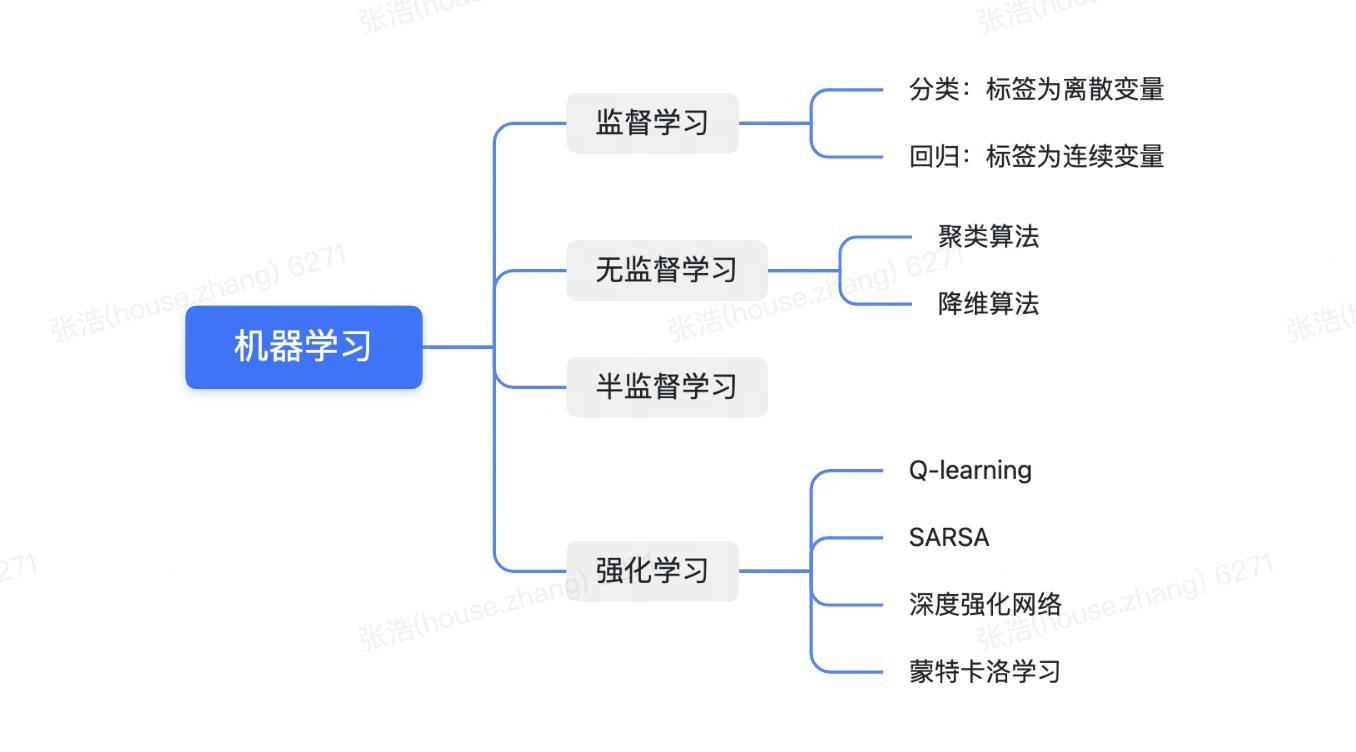## 如何理解深度学习常说的深度学习是一种使用深层神经网络的模型,可以应用于上述四类机器学习中,深度学习擅长处理非结构化输入,在视觉处理和自然语言处理方面都很厉害。深度学习,能对非结构的数据集进行自动的复杂特征提取,完全不需要人工...
技术人的 2023 总结:人工智能-基于机器学习的环境污染影响评估学习|社区征文
使用Python中的Scikit-Learn库中的线性回归模型来展示代码实例。首先,确保已经安装了Scikit-Learn库:```pip install scikit-learn```我们将使用一个简化的环境数据集,其中包含各种环境因素,如温度、湿度、风速等,以及相应的污染级别。```# 导入必要的库import pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom sklearn...
高效 AI 视频处理利器 - BMF 模块开发初体验|社区征文
安装人脸超分代码的依赖:`pip3 install opencv-python scikit-image dlib torch torchvision`1. 按照人脸超分代码仓库的 `README`,下载依赖的模型,并执行`python3 test.py`,确认可执行成功解决了算法依赖问题,就可以开始 BMF Python 模块的改造了。### 改造人脸超分模块我们可以在上面复制流模块的基础上,对算法模块进行改造。具体改造点包括:- `init` 中进行超分模型的初始化,这样在后续的处理中就可以直接使用了-...
模型包规范
scikit-learn{MODEL_PATH}/ └──{NAME}.[pkl/joblib]XGBoost{MODEL_PATH}/ └──{NAME}.[model/json] LightGBM{MODEL_PATH}/ └──{NAME}.txt
AIGC 推理加速:火山引擎镜像加速实践
pip install transformers==4.19.2 diffusers==0.3.0 basicsr==1.4.2 gfpgan==1.3.8 gradio==3.30 numpy==1.23.3 Pillow==9.2.0 realesrgan==0.3.0 torch omegaconf==2.2.3 pytorch_lightning==1.7.6 scikit-image==0.19.2 fonts font-roboto timm==0.6.7 fairscale==0.4.9 piexif==1.1.3 einops==0.4.1 jsonmerge==1.8.0 clean-fid==0.1.29 resize-right==0.0.2 torchdiffeq==0.2.3 kornia==0.6.7 lark==1.1.2 inflection==...
