多云 GPU 算力调度
最近更新时间:2024.04.26 15:29:02
首次发布时间:2024.04.26 15:29:02
分布式云原生平台提供算力业务统一分发能力,可自动调度多云集群 GPU 资源,主要应用于 AI 浪潮下如何在多云环境及时获取 GPU 资源,以满足算力业务需求。本文为您介绍如何使用分布式云原生平台构建多云 GPU 算力调度场景的详细使用方法。
场景介绍
为应对 GPU 资源短缺,需求端、人工智能公司、游戏公司等 GPU 需求较大的企业往往会综合考虑成本、稳定性等因素选择服务商或购置多路云服务。面对这种局面,如何高效调度多云云上算力,是建设稳定智算底座的重要环节。分布式云原生平台能够实现算力业务的统一分发,根据 GPU 规格、资源用量、云厂商和区域等业务需求,将业务实例自动调度到多云集群的 GPU 服务器或弹性容器中运行。
方案架构
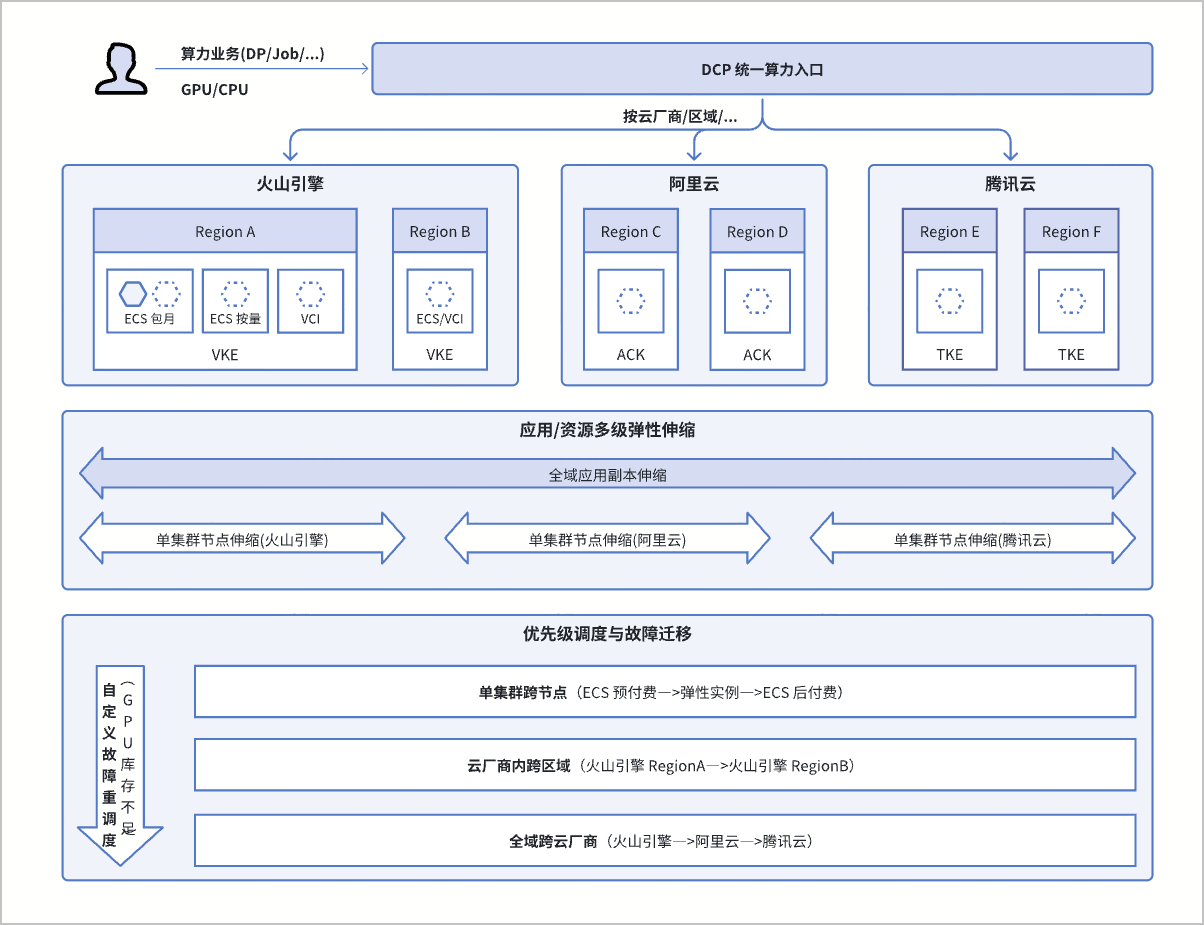
- 全域调度效率高:通过多云集群纳管和统一分发入口,实现多云环境 GPU 资源调度。当云厂商资源库存不足时,系统能够自动重调度,无需人工干预。
- 按需低成本:通过应用的全域弹性伸缩能力,仅在算力业务需要时购买和调度 GPU 资源,以实现成本节约。
- 全场景负载支持:支持无状态、有状态和离线负载类型的多云分发,并具备对 CPU/GPU 多计算资源全局调度感知能力。
- 调度策略灵活:可根据不同维度的优先级顺序调度,同时支持在多云环境中并发调度,确保资源紧缺时提高 GPU 购买成功率。
- 多云环境差异适配:无需在多云环境中重复配置工作负载,可通过关联差异化策略实现调度到不同环境负载的覆写适配,例如:镜像地址、GPU 型号/需求量等。
网络规划
- 集群纳管:分布式云原生平台已经通过注册现有集群方式,将创建的 VKE-POC1、VKE-POC2、ACK-POC 接入北京地域。
- 联邦集群:分布式云原生平台已经创建联邦主控实例 Fed-POC,并将 VKE-POC1、VKE-POC2、ACK-POC 添加到成员集群,构建集群联邦。
| 集群 | 类型 | 地域 | VPC | 网络插件 |
|---|---|---|---|---|
| Fed-POC | 火山引擎集群联邦的主控实例 | 北京 | VPC1 | — |
| VKE-POC1 | 火山引擎 VKE&VCI 集群 | 北京 | VPC-CNI | |
| VKE-POC2 | 火山引擎 VKE&VCI 集群 | 上海 | VPC2 | |
| ACK-POC | 阿里云 ACK 集群 | 上海 | VPC3 | Terway |
资源清单
本场景使用到的资源清单和说明如下:
| 资源类型 | 资源名称 | 说明 |
|---|---|---|
| ResourcePolicy | vke-poc1-rp | 火山引擎 VKE-POC1 单集群内弹性资源优先级调度策略。 |
| vke-poc2-rp | 火山引擎 VKE-POC2 单集群内弹性资源优先级调度策略。 | |
| ack-poc-rp | 阿里云 ACK-POC 单集群内弹性资源优先级调度策略。 | |
| Deployment | fed-dp-gpu | 联邦工作负载资源,配置了 GPU 资源需求。 |
| PropagationPolicy | fed-pp-weight | 跨集群部署策略,配置目标分发集群、集群副本分配比例等,适用于并发抢占场景。 |
| fed-pp-priority | 跨集群部署策略,配置目标分发集群、集群优先级顺序等,适用于顺序抢占场景。 | |
| OverridePolicy | fed-op | 差异化覆写策略,用于工作负载资源在多云集群中差异化配置。 |
| HorizontalPodAutoscaler | fed-hpa | 联邦中心式 HPA,配置了基于 GPU 平均使用率阈值的工作负载弹性扩缩容。 |
背景信息
随着人工智能(AI)技术在各个领域的广泛应用,企业对 GPU 的需求也急剧增长。然而,由于 GPU 硬件和云上算力的供给受限,导致目前市场出现供不应求的情况,并为企业客户带来以下问题:
- 单一云厂商 GPU 资源可能无法满足需求,需要从多家云购买 GPU,对接多云环境,并分发算力任务。
- 云厂商库存不透明,算力任务只能通过试错的方式进行库存验证,需要实现复杂的任务故障重调度机制。
- 考虑 GPU 资源成本较高,期望通过少量常驻资源满足日常算力需求,任务突发时进行弹性扩容。
基于上述背景,分布式云原生平台推出多云 GPU 调度产品解决方案,主要应用于 AI 浪潮下如何在多云环境及时获取 GPU 资源,以满足算力业务需求。
前提条件
- 已经注册火山引擎账号,并开通分布式云原生平台服务。
- 已经在火山引擎创建 2 个 VKE 集群,已经在第三方云平台创建 1 个第三方容器集群(本场景以阿里云 ACK 为例)。初始化配置如下:
| 资源/配置类型 | 初始化配置说明 | 火山引擎 VKE 操作说明 | 阿里云 ACK 操作说明 |
|---|---|---|---|
组件 |
|
|
|
节点池 | GPU-Pool-1:预付费节点池,满足正常算力需求。
GPU-Pool-2:后付费节点池,弹性算力应对突发任务。
| VKE-POC1、VKE-POC2 两个集群分别创建两个节点池:GPU-Pool-1、GPU-Pool-2,配置如下:
| ACK-POC 创建两个节点池:GPU-Pool-1、GPU-Pool-2,配置如下:
|
| 弹性资源优先级调度策略 | 每个集群配置弹性资源优先级,确保在单集群中因库存不足等原因实例调度顺序为:预付费节点池 —>弹性容器实例—>后付费节点池。 | 参考 弹性资源优先级调度 进行配置,具体配置内容参见下文资源清单。 | 参考 自定义弹性资源优先级调度 进行配置,具体配置内容参见下文资源清单。 |
操作步骤
本文从 0 到 1 为您详细介绍构建多云 GPU 算力调度,并对 GPU 算力负载跨云并发调度、GPU 算力负载跨云优先级调度、GPU 算力负载跨云弹性伸缩三个场景进行验证,可参考如下步骤依次执行。
步骤一:单集群内创建优先级调度策略
分别前往火山引擎 VKE-POC1、VKE-POC2 集群,阿里云 ACK-POC 集群的对象浏览器内创建弹性资源优先级调度策略,用于模拟库存不足的限制。以火山引擎为例,在对象浏览器中创建自定义资源的步骤参见:创建自定义资源。
- 火山引擎 VKE-POC1 集群中自定义资源的 Yaml 示例如下:
apiVersion: scheduling.vke.volcengine.com/v1beta1 kind: ResourcePolicy metadata: name: vke-poc1-rp namespace: default spec: selector: # 被 ResourcePolicy 管理的 Pod 的 Label 选择器。 app: gpu-demo strategy: prefer # 调度策略,有 require、prefer 两种策略。 subsets: # 资源池配置。 - name: ecs-pool-1 # 预付费节点池 type: ecs #maxReplicas: 100 nodeSelectorTerm: - key: cluster.vke.volcengine.com/machinepool-name operator: In values: - pcltbrovu2ttge1iek560 # 替换为您实际的节点池 ID - name: vci-pool # 弹性容器实例资源池 type: vci maxReplicas: 2 # 注:此处通过设置上限,用来模拟库存不足的限制 nodeSelectorTerm: - key: type operator: In values: - virtual-kubelet - name: ecs-pool-2 # 后付费付费节点池 type: ecs #maxReplicas: 100 nodeSelectorTerm: - key: cluster.vke.volcengine.com/machinepool-name operator: In values: - pcltbptvu2ttge1iek4rg # 替换为您实际的节点池 ID
- 火山引擎 VKE-POC2 集群中自定义资源的 Yaml 示例如下:
apiVersion: scheduling.vke.volcengine.com/v1beta1 kind: ResourcePolicy metadata: name: vke-poc2-rp namespace: default spec: selector: # 被 ResourcePolicy 管理的 Pod 的 Label 选择器。 app: gpu-demo strategy: prefer # 调度策略,有 require、prefer 两种策略。 subsets: # 资源池配置。 - name: ecs-pool-1 # 预付费节点池 type: ecs #maxReplicas: 100 nodeSelectorTerm: - key: cluster.vke.volcengine.com/machinepool-name operator: In values: - pcltbtnanjbeqedvbciag # 替换为您实际的节点池 ID - name: vci-pool # 弹性容器实例资源池 type: vci maxReplicas: 2 # 注:此处通过设置上限,用来模拟库存不足的限制 nodeSelectorTerm: - key: type operator: In values: - virtual-kubelet - name: ecs-pool-2 # 后付费付费节点池 type: ecs #maxReplicas: 100 nodeSelectorTerm: - key: cluster.vke.volcengine.com/machinepool-name operator: In values: - pcltbu7anjbeqedvbcicg # 替换为您实际的节点池 ID
- 阿里云 ACK-POC 集群中自定义资源的 Yaml 示例如下:
apiVersion: scheduling.alibabacloud.com/v1alpha1 kind: ResourcePolicy metadata: name: ack-poc-rp namespace: default spec: selector: # 被 ResourcePolicy 管理的 Pod 的 Label 选择器。 app: gpu-demo strategy: prefer units: - resource: ecs # 预付费付费节点池 #max: 10 nodeSelector: alibabacloud.com/nodepool-id: np6adca1a73fff4843b19f151d2efe8fcf # 替换为您实际的节点池 ID - resource: eci # 弹性容器实例资源池 max: 2 # 注:此处通过设置上限,用来模拟库存不足的限制 - resource: ecs # 后付费付费节点池 nodeSelector: alibabacloud.com/nodepool-id: npcc24f5db47d642f7a5ca274d0bcb0974 # 替换为您实际的节点池 ID
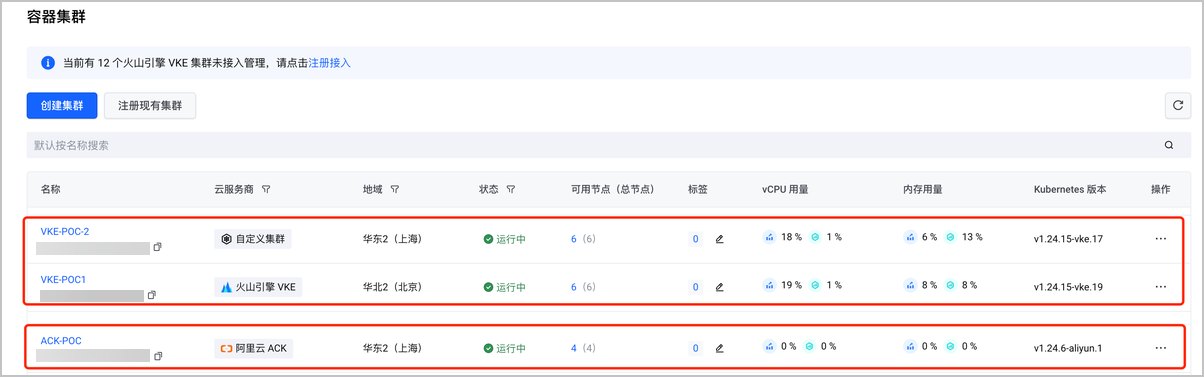
步骤二:将容器集群注册/纳管到 DCP
将容器集群注册/纳管到分布式云原生平台统一管理,后续可直接添加到联邦主控实例作为成员集群,用于联邦制资源分发。本场景使用的参数配置如下:
| 集群名称 | 云服务商 | 注册地域 | 注册方式 |
|---|---|---|---|
| ACK-POC | 阿里云 ACK | 华北 2 (北京) | 代理连接 |
| VKE-POC1 | 火山引擎 VKE | 华北 2 (北京) | 一键注册 |
| VKE-POC2 | 火山引擎 VKE | 华北 2 (北京) | 代理连接 |
一键注册火山引擎集群 VKE-POC1:VKE 和 DCP 同属火山引擎,通过容器集群页面顶部的 注册接入,即可将 VKE 集群一键注册到分布式云原生平台,详细操作步骤和配置项说明参见:注册 VKE 集群。
通过代理模式注册集群 VKE-POC2:通过容器集群页面 创建集群 > 注册现有集群,使用 代理连接 方式的两步操作,将上海地域的 VKE 集群注册到分布式云原生平台的北京地域。
本场景涉及的关键配置说明如下,其他按需配置即可,详细操作步骤和配置项说明参见:注册现有集群(代理连接)。
| 配置项 | 说明 |
|---|---|
| 集群名称 | 可自定义集群名称(本场景命名为:VKE-POC2),命名规范:长度 2-64 个字符;支持英文字母、汉字、数字和中划线(-)。 |
| 云服务商 | 分布式云原生适配的第三方平台集群(本场景选择自定义集群),要求选择与待接入集群匹配的云服务商,否则可能导致部分功能不可用。 |
| 接入地域 | 容器集群接入分布式云原生平台后所属的地域(本场景选择华北 2 (北京))。 |
| 私有网络 | 待接入容器集群使用的私有网络。本场景中的集群使用不同网络,详细配置参见网络规划章节。 |
| API Server 公网访问 | 默认关闭(本场景调整为:开启),若开启此配置,系统将自动创建 EIP 并关联主控实例 API Server 负载均衡,即可通过公网连接管理容器集群。 |
- 通过代理模式注册集群 ACK-POC:同 VKE-POC2,通过容器集群页面 创建集群 > 注册现有集群,使用 代理连接 方式的两步操作,将阿里云 ACK 集群注册到分布式云原生平台。
本场景涉及的关键配置说明如下,其他按需配置即可,详细操作步骤和配置项说明参见:注册现有集群(代理连接)。
| 配置项 | 说明 |
|---|---|
| 集群名称 | 可自定义集群名称(本场景命名为:ACK-POC),命名规范:长度 2-64 个字符;支持英文字母、汉字、数字和中划线(-)。 |
| 云服务商 | 分布式云原生适配的第三方平台集群(本场景选择阿里云 ACK),要求选择与待接入集群匹配的云服务商,否则可能导致部分功能不可用。 |
| 接入地域 | 容器集群接入分布式云原生平台后所属的地域(本场景选择华北 2 (北京))。 |
| 私有网络 | 待接入容器集群使用的私有网络。本场景中的集群使用不同网络,详细配置参见网络规划章节。 |
| API Server 公网访问 | 默认关闭(本场景调整为:开启),若开启此配置,系统将自动创建 EIP 并关联主控实例 API Server 负载均衡,即可通过公网连接管理容器集群。 |
步骤三:搭建联邦集群基础环境
- 创建主控实例:进入联邦主控实例页面,创建主控实例,用于实现联邦集群管理、应用调度分发功能。
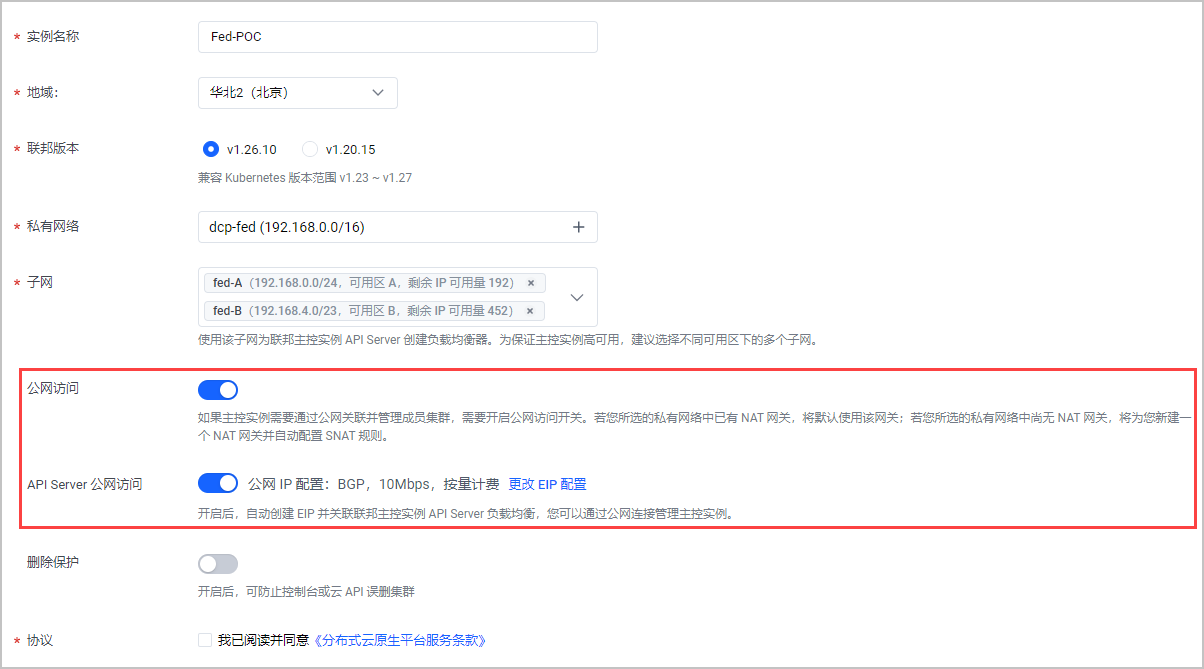
本场景涉及的关键配置说明如下,其他按需配置即可,详细操作步骤和配置项说明参见:创建主控实例。
| 配置项 | 说明 |
|---|---|
| 实例名称 | 自定义主控实例名称(本场景命名为:Fed-POC),同一地域内不可重名。命名规则:长度 2~64 个字符,支持英文字母、汉字、数字和中划线(-)。 |
| 地域 | 物理数据中心所在的地理区域(本场景选择华北 2 (北京)),资源创建后不支持更换地域。不同地域之间内网完全隔离,保证不同地域间最大程度的稳定性和容错性。 |
| 私有网络 | 私有网络为云上资源构建隔离的、自主配置的虚拟网络环境,默认情况下,同一地域内同一私有网络下所有资源网络互通。本场景中的集群使用不同网络,详细配置参见网络规划章节。 |
公网访问 | 默认关闭(本场景调整为:开启),若开启此配置,主控实例将支持通过公网访问并管理成员集群。 说明 开启后,若所选私有网络中已经创建 NAT 网关,将默认使用该网关;若所选私有网络中尚无 NAT 网关,将新建一个 NAT 网关并自动配置 SNAT 规则。 |
| API Server 公网访问 | 默认关闭(本场景调整为:开启),若开启此配置,系统将自动创建 EIP并关联主控实例 API Server 负载均衡,即可通过公网连接管理主控实例。 |
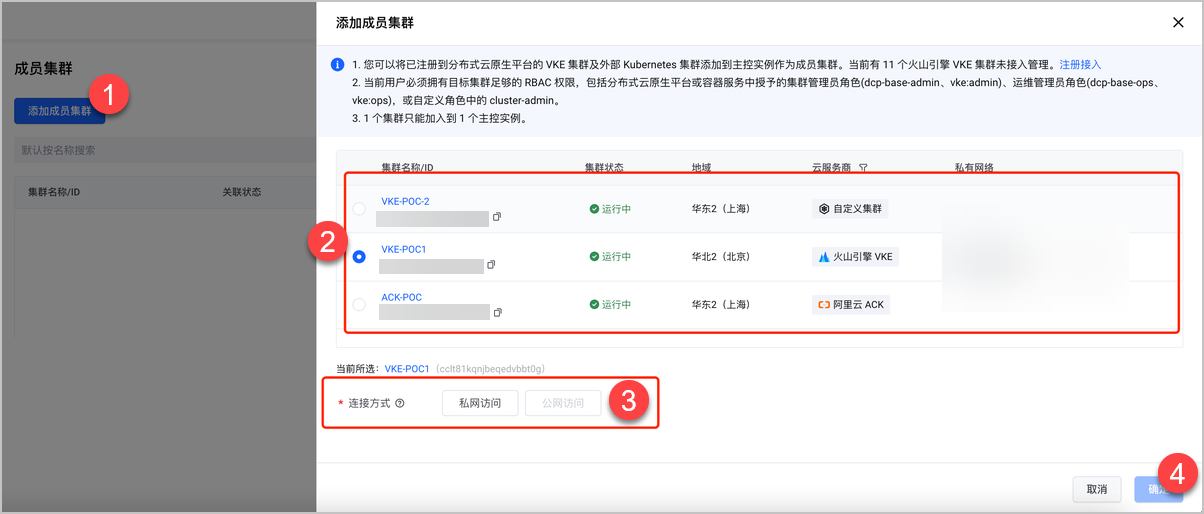
- 添加成员集群:进入联邦主控实例的成员集群页面,将火山引擎 VKE 集群和纳管的外部 ACK 集群添加到联邦集群。
主控实例与目标集群在统一 VPC,可以使用私网接入(例如:VKE-POC1),否则选择公网方式(例如:VKE-POC2、ACK-POC)。当关联状态切换为已关联时,表示集群添加成功,详细操作步骤和配置项说明参见:添加成员集群。
- 创建部署策略:进入联邦主控实例的部署策略页面,通过 Yaml 创建创建两个部署策略,用于多集群资源的跨集群分发策略配置。详细操作步骤和配置项说明参见:创建部署策略(Yaml)。
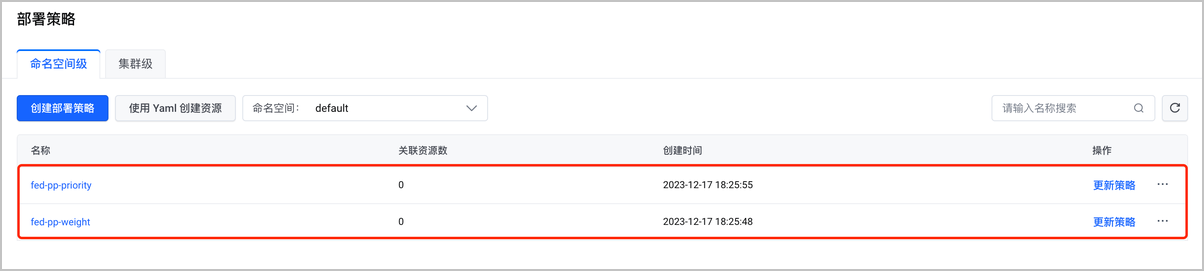
- 并发抢占式部署策略的 Yaml 示例如下:
apiVersion: core.kubeadmiral.io/v1alpha1 kind: PropagationPolicy metadata: name: fed-pp-weight namespace: default spec: schedulingMode: Divide # 开启副本模式调度 placement: - cluster: cclt81kqnjbeqedvbbt0g # VKE-POC1 成员集群ID preferences: weight: 40 # 副本分配权重 minReplicas: 2 # 分配最小副本数 #maxReplicas: 10 # 分配最大副本数 - cluster: ccltbv1p1h4ho7pq6sugg # VKE-POC2 成员集群ID preferences: weight: 40 # 副本分配权重 minReplicas: 2 # 分配最小副本数 #maxReplicas: 10 # 分配最大副本数 - cluster: cclt75bp1h4ho7pq6su9g # ACK-POC 成员集群ID preferences: weight: 20 # 副本分配权重 minReplicas: 2 # 分配最小副本数 #maxReplicas: 10 # 分配最大副本数 reschedulePolicy: disableRescheduling: false replicaRescheduling: avoidDisruption: false rescheduleWhen: clusterAPIResourcesChanged: false clusterJoined: false clusterLabelsChanged: false policyContentChanged: true autoMigration: # Pod 不可调度自动迁移 keepUnschedulableReplicas: true # 是否保留不可调度副本,保留的话当恢复时可自动迁回 when: podUnschedulableFor: 2m #
- 按集群优先级的顺序抢占式部署策略 Yaml 示例如下:
apiVersion: core.kubeadmiral.io/v1alpha1 kind: PropagationPolicy metadata: name: fed-pp-priority namespace: default spec: schedulingMode: Divide # 开启副本模式调度 replicasStrategy: Binpack # 开启集群优先级调度 placement: - cluster: cclt81kqnjbeqedvbbt0g # VKE-POC1 成员集群ID preferences: priority: 3 # 集群优先级 minReplicas: 2 # 分配最小副本数 #maxReplicas: 10 # 分配最大副本数 - cluster: ccltbv1p1h4ho7pq6sugg # VKE-POC2 成员集群ID preferences: priority: 2 # 集群优先级 minReplicas: 2 # 分配最小副本数 #maxReplicas: 10 # 分配最大副本数 - cluster: cclt75bp1h4ho7pq6su9g # ACK-POC 成员集群ID preferences: priority: 1 # 集群优先级 minReplicas: 2 # 分配最小副本数 #maxReplicas: 10 # 分配最大副本数 reschedulePolicy: disableRescheduling: false replicaRescheduling: avoidDisruption: false rescheduleWhen: clusterAPIResourcesChanged: false clusterJoined: false clusterLabelsChanged: false policyContentChanged: true autoMigration: # Pod 不可调度自动迁移 keepUnschedulableReplicas: true # 是否保留不可调度副本,保留的话当恢复时可自动迁回 when: podUnschedulableFor: 2m #
- 创建差异化策略:进入联邦主控实例的差异化策略页面,通过 Yaml 创建一个差异化策略。详细操作步骤和配置项说明参见:创建差异化策略(Yaml)。

差异化策略的 Yaml 示例如下:
apiVersion: core.kubeadmiral.io/v1alpha1 kind: OverridePolicy metadata: name: fed-op namespace: default spec: overrideRules: - overriders: jsonpatch: - operator: add # 注:当 annotation 的 key 中有'/',需要使用'~1'转义 path: /spec/template/metadata/annotations/vci.vke.volcengine.com~1preferred-instance-types value: vci.g1v.2xlarge # 指定实例 GPU 规格 v100*1 targetClusters: clusters: - cclt81kqnjbeqedvbbt0g # VKE-POC1 成员集群ID,替换为您的成员集群ID - ccltbv1p1h4ho7pq6sugg # VKE-POC2 成员集群ID,替换为您的成员集群ID - overriders: jsonpatch: - operator: add # 注:当 annotation 的 key 中有'/',需要使用'~1'转义 path: /spec/template/metadata/annotations/k8s.aliyun.com~1eci-use-specs value: ecs.gn5i-c2g1.large # 指定实例 GPU 规格 P4*1 targetClusters: clusters: - cclt75bp1h4ho7pq6su9g # ACK-POC 成员集群ID,替换为您的成员集群ID
步骤四:GPU 算力负载跨云并发调度
- 创建联邦 GPU 工作负载:前往联邦主控实例页面,使用 Yaml 创建资源,并配置部署策略(fed-pp-weight)和差异化策略(fed-op)。
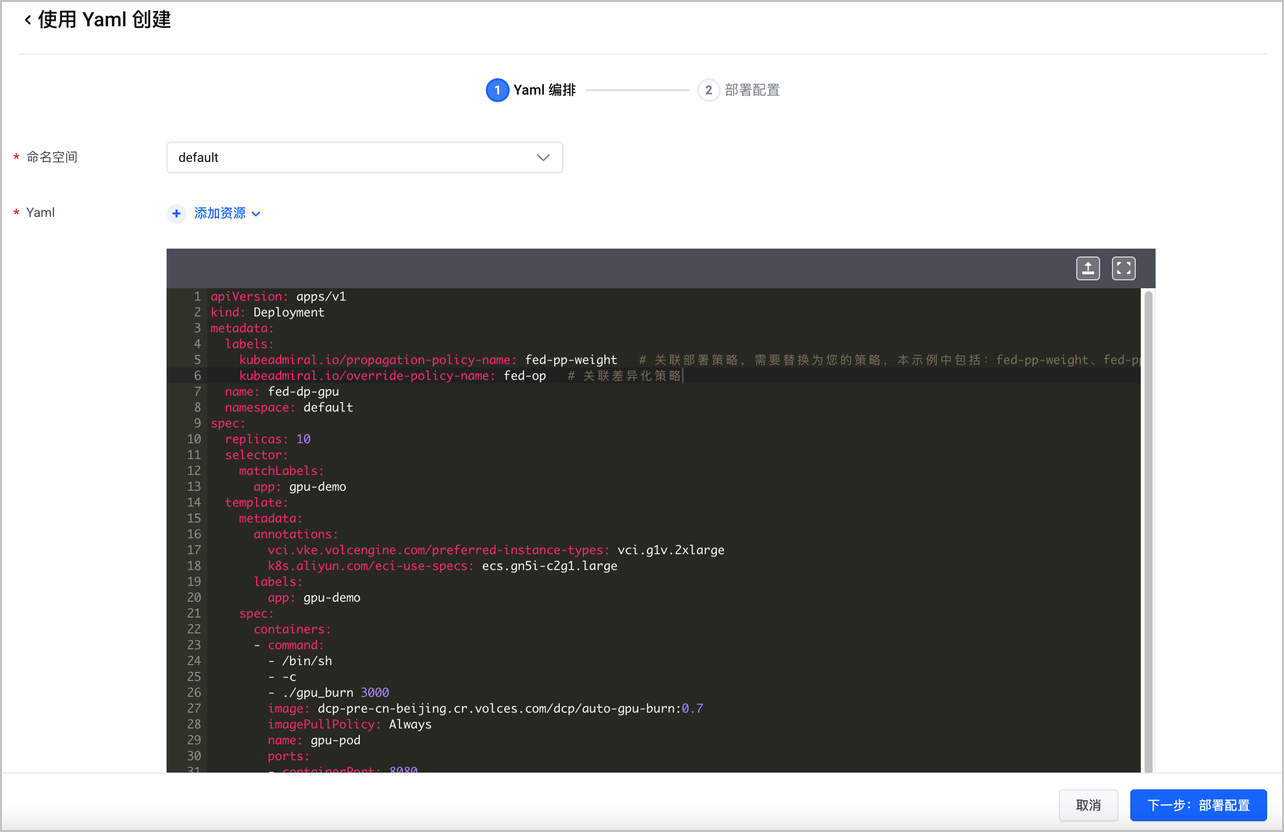
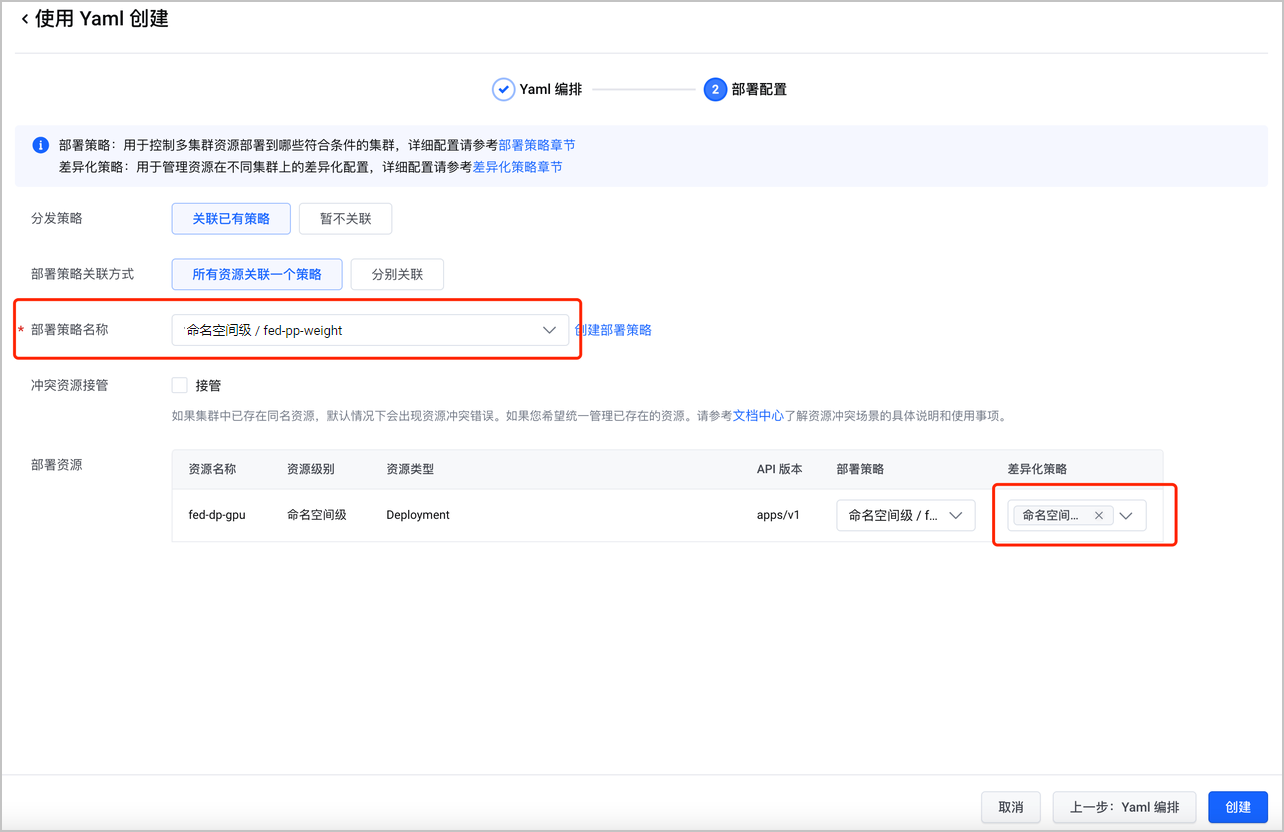
联邦 GPU 工作负载的 Yaml 示例如下:
apiVersion: apps/v1 kind: Deployment metadata: labels: kubeadmiral.io/propagation-policy-name: fed-pp-weight # 关联部署策略,需要替换为您的策略,本示例中包括:fed-pp-weight、fed-pp-priority kubeadmiral.io/override-policy-name: fed-op # 关联差异化策略 name: fed-dp-gpu namespace: default spec: replicas: 10 selector: matchLabels: app: gpu-demo template: metadata: annotations: {} labels: app: gpu-demo spec: containers: - command: - /bin/sh - -c - ./gpu_burn 3000 image: dcp-pre-cn-beijing.cr.volces.com/dcp/auto-gpu-burn:0.7 imagePullPolicy: Always name: gpu-pod ports: - containerPort: 8080 protocol: TCP resources: limits: nvidia.com/gpu: "1" requests: nvidia.com/gpu: "1"
预期结果
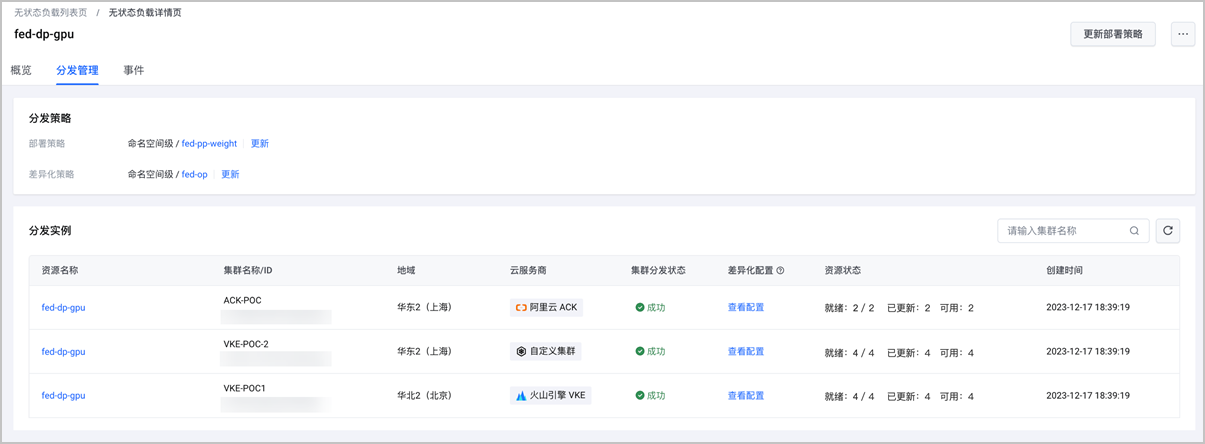
- 差异化策略已经生效 VKE、ACK 集群中已分别增加以下弹性容器实例相关的注解:
vci.vke.volcengine.com/preferred-instance-types: vci.g1v.2xlarge和k8s.aliyun.com/eci-use-specs: ecs.gn5i-c2g1.large。 - 工作负载已根据部署策略权重定义将 10 副本分发到三个集群,具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 40%,4 Pod |
|
VKE-POC2 | 40%,4 Pod |
|
ACK-POC | 20%,2 Pod |
|
- 手动扩容负载副本 10 -> 15:前往无状态负载管理页面,单击目标负载右侧操作列中
...中的 更新 操作,修改期望副本数为 15。
预期结果
工作负载已根据部署策略权重定义将扩容 5 副本分发到三个集群,具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 40%,新增 2 Pod,共 6 Pod |
|
VKE-POC2 | 40%,新增 2 Pod,共 6 Pod |
|
ACK-POC | 20%,新增 1 Pod,共 3 Pod |
|
- 手动扩容负载副本 15 -> 20:前往无状态负载管理页面,单击目标负载右侧操作列中
...中的 更新 操作,修改期望副本数为 20。
预期结果
- 工作负载已根据部署策略权重定义将扩容 5 副本分发到三个集群,具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 40%,新增 2 Pod,共 8 Pod |
|
VKE-POC2 | 40%,新增 2 Pod,共 8 Pod |
|
ACK-POC | 20%,新增 1 Pod,共 4 Pod |
|
- VKE 集群中的不可调度持续超过 2 分钟(可在部署策略中配置)后,会将副本迁移到其他可调度集群中(ACK 集群),具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 40%,共 8 Pod |
|
VKE-POC2 | 40%,共 8 Pod |
|
ACK-POC | 20%,新增 4 Pod,共 8 Pod |
|
说明
如果不期望在集群中保留不可调度副本及后续的副本恢复迁回,可以在部署策略中进行以下配置:
reschedulePolicy: replicaRescheduling: avoidDisruption: true autoMigration: keepUnschedulableReplicas: false
- VKE 集群增加可调度资源:进入容器服务集群详情的对象浏览器模块,将 VKE-POC1、VKE-POC2 集群中的 ResourcePolicy 资源中 VCI 资源池的 maxReplicas 从 2 调整为 4。
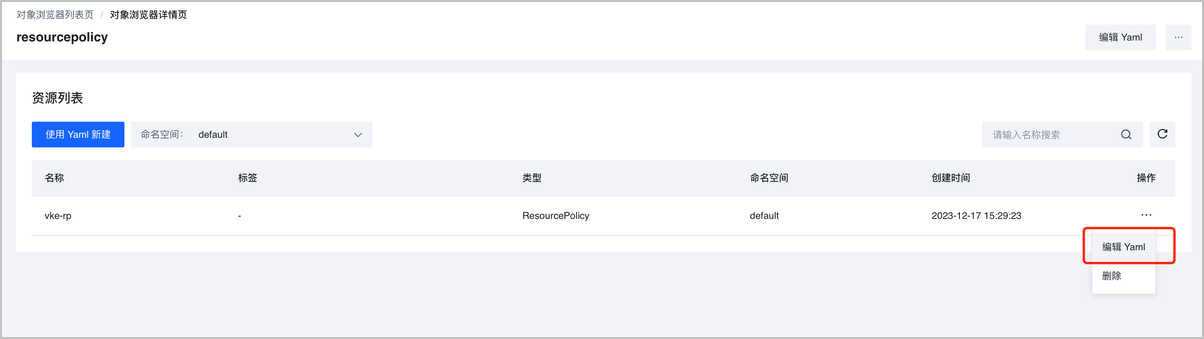
预期结果
VKE-POC1、VKE-POC2 集群中不可调度副本可进行正常调度,ACK-POC 集群中副本缩减 4 个,并触发节点缩容,具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 40%,共 8 Pod |
|
VKE-POC2 | 40%,共 8 Pod |
|
ACK-POC | 20%,减少 4 Pod,共 4 Pod |
|
- 缩容 GPU 负载副本 20 -> 10:前往无状态负载管理页面,单击目标负载右侧操作列中
...中的 更新 操作,修改期望副本数为 10。
预期结果
缩减的 10 个副本按照多集群权重比例分配,单集群中缩减的副本按照原调度的反向路径缩减,具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 40%,缩减 4 Pod,共 4 Pod |
|
VKE-POC2 | VKE-POC2(40%,缩减 4 Pod,共 4 Pod) |
|
ACK-POC | ACK-POC(20%,减少 2 Pod,共 2 Pod) |
|
步骤五:GPU 算力负载跨云优先级调度
- 创建联邦 GPU 工作负载:前往联邦主控实例页面,使用 Yaml 创建资源,并配置部署策略(fed-pp-priority)和差异化策略(fed-op)。
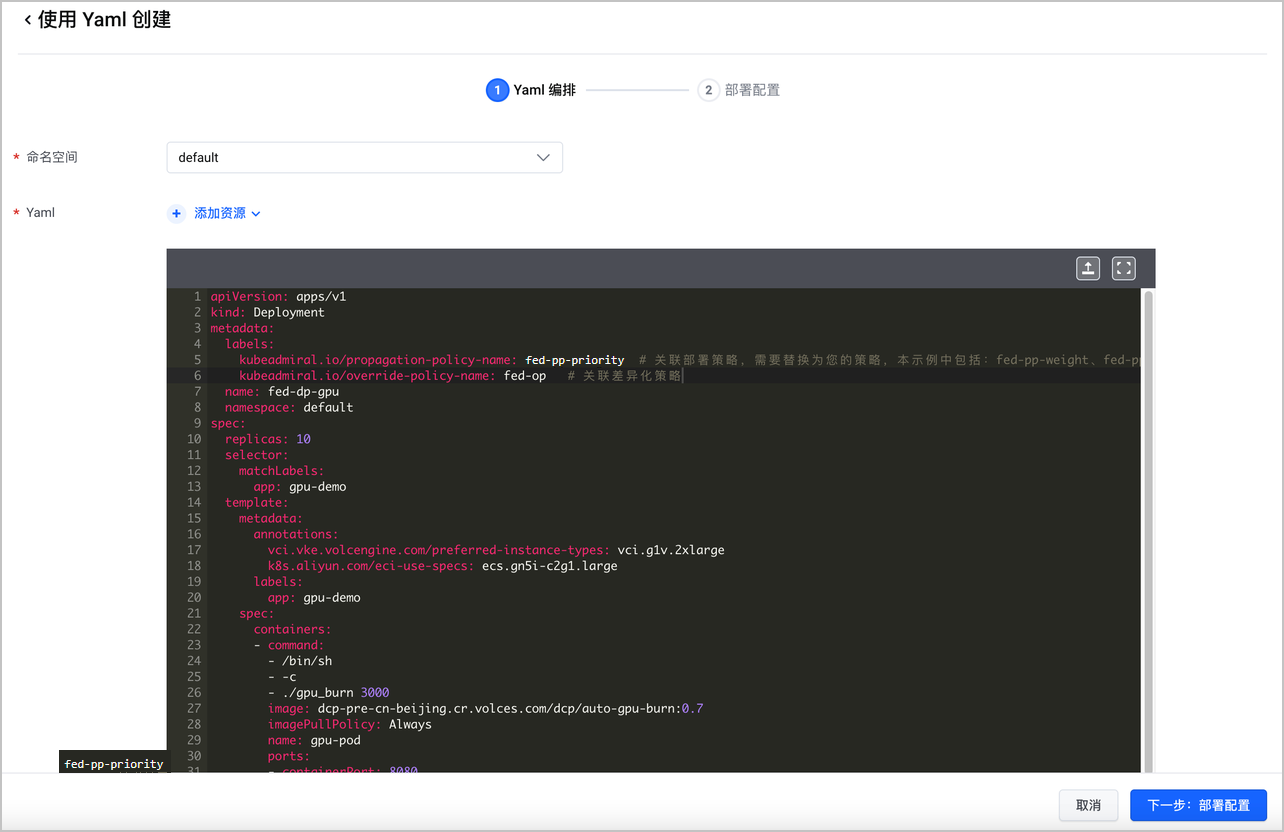
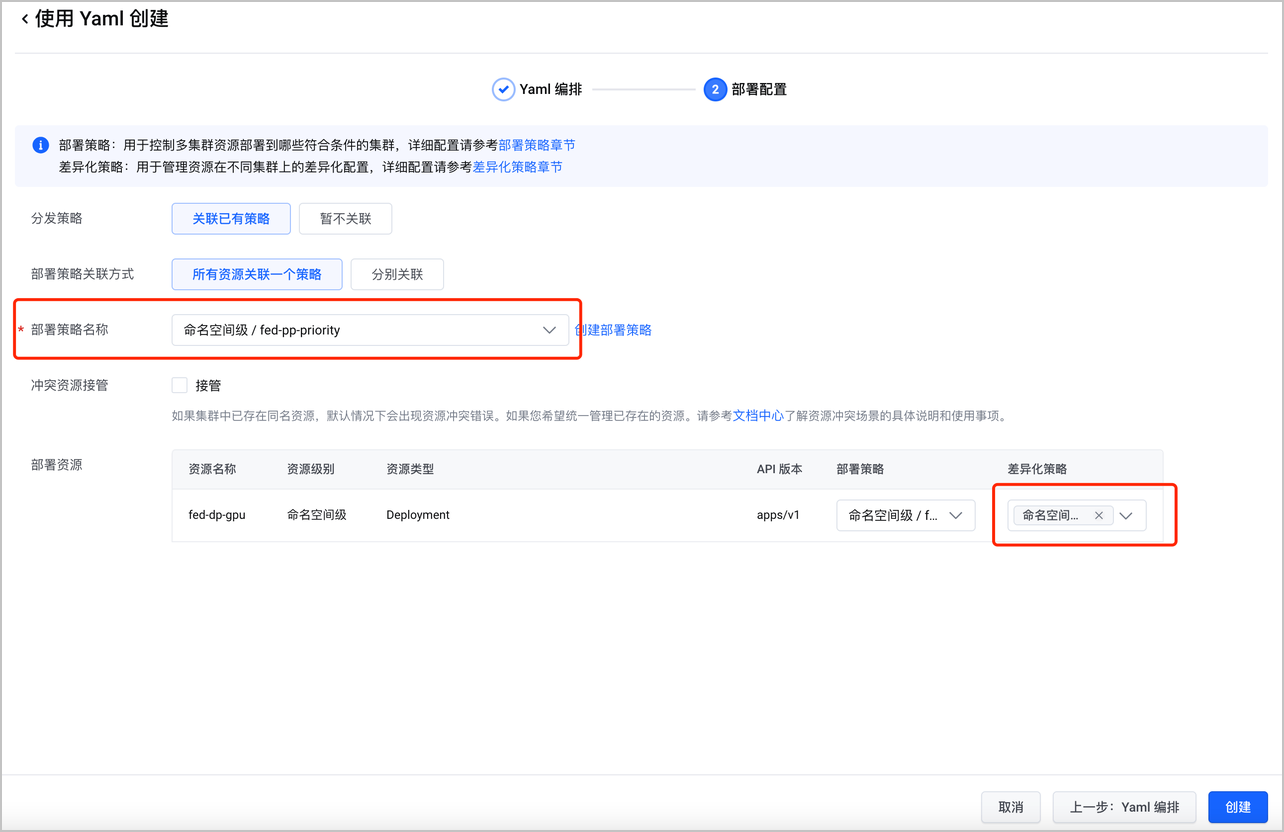
联邦 GPU 工作负载的 Yaml 示例如下:
apiVersion: apps/v1 kind: Deployment metadata: labels: kubeadmiral.io/propagation-policy-name: fed-pp-priority # 关联部署策略,需要替换为您的策略,本示例中包括:fed-pp-weight、fed-pp-priority kubeadmiral.io/override-policy-name: fed-op # 关联差异化策略 name: fed-dp-gpu namespace: default spec: replicas: 10 selector: matchLabels: app: gpu-demo template: metadata: annotations: {} labels: app: gpu-demo spec: containers: - command: - /bin/sh - -c - ./gpu_burn 3000 image: dcp-pre-cn-beijing.cr.volces.com/dcp/auto-gpu-burn:0.7 imagePullPolicy: Always name: gpu-pod ports: - containerPort: 8080 protocol: TCP resources: limits: nvidia.com/gpu: "1" requests: nvidia.com/gpu: "1"
预期结果
差异化策略已经生效 VKE、ACK 集群中已分别增加以下弹性容器实例相关的注解:
vci.vke.volcengine.com/preferred-instance-types: vci.g1v.2xlarge和k8s.aliyun.com/eci-use-specs: ecs.gn5i-c2g1.large。工作负载已根据部署策略权重定义将 10 副本分发到三个集群(策略中要求每个集群最小分配 2 副本),具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 优先级:3,共 6 Pod | 满足每个集群最小分配副本后,其他副本都调度到优先级高的集群。
|
VKE-POC2 | 优先级:2,共 2 Pod |
|
ACK-POC | 优先级:1,共 2 Pod |
|
- 手动扩容负载副本 10 -> 14:前往无状态负载管理页面,单击目标负载右侧操作列中
...中的 更新 操作,修改期望副本数为 15。
预期结果
- 工作负载已根据部署策略定义将扩容 4 副本调度到优先级高的集群中,具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 优先级:3,新增 4 Pod,共 10 Pod |
|
VKE-POC2 | 优先级:2,共 2 Pod |
|
ACK-POC | 优先级:1,共 2 Pod |
|
- VKE-POC1 集群中不可调度副本持续 2 分钟(可在部署策略配置)后,会尝试次优先级集群 VKE-POC2 调度。
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 优先级:3,共 11 Pod |
|
VKE-POC2 | 优先级:2,新增 4 Pod,共 6 Pod |
|
ACK-POC | 优先级:1,共 2 Pod |
|
说明
如果不期望在集群中保留不可调度副本及后续的副本恢复迁回,可以在部署策略中进行以下配置:
reschedulePolicy: replicaRescheduling: avoidDisruption: true autoMigration: keepUnschedulableReplicas: false
- 手动扩容负载副本 14 -> 20:前往无状态负载管理页面,单击目标负载右侧操作列中
...中的 更新 操作,修改期望副本数为 20。
预期结果
- 工作负载已根据部署策略定义将扩容 6 副本调度到优先级高的集群中,具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 优先级:3,新增 6 Pod,共 16 Pod |
|
VKE-POC2 | 优先级:2,共 6 Pod |
|
ACK-POC | 优先级:1,共 2 Pod |
|
- VKE-POC1 集群中新的不可调度的 6 副本持续 2 分钟(可在部署策略配置)后,会尝试次优先级集群 VKE-POC2 调度,具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 优先级:3,共 16 Pod |
|
VKE-POC2 | 优先级:2,新增 6 Pod,共 12 Pod |
|
ACK-POC | 优先级:1,共 2 Pod |
|
- VKE-POC2 集群中新的不可调度的 6 副本持续 2 分钟(可在部署策略配置)后,会尝试次优先级集群 ACK-POC 调度,具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 优先级:3,共 16 Pod |
|
VKE-POC2 | 优先级:2,共 12 Pod |
|
ACK-POC | 优先级:1,新增 6 Pod,共 8 Pod |
|
- VKE 集群增加可调度资源:进入容器服务集群详情的对象浏览器模块,将 VKE-POC1、VKE-POC2 集群中的 ResourcePolicy 资源中 VCI 资源池的 maxReplicas 从 2 调整为 4。
预期结果
- VKE-POC1、VKE-POC2 集群中2个不可调度副本可进行正常调度,ACK-POC 集群中副本缩减4个,并触发节点缩容,具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 优先级:3,共 16 Pod |
|
VKE-POC2 | 优先级:2,共 12 Pod |
|
ACK-POC | 优先级:1,减少 4 Pod,共 4 Pod |
|
- 缩容 GPU 负载副本 20 -> 10:前往无状态负载管理页面,单击目标负载右侧操作列中
...中的 更新 操作,修改期望副本数为 10。
预期结果
- 缩减的 10 个副本按照优先级低的集群先缩减原则,单集群中缩减的副本按照原调度的反向路径缩减,具体分布如下:
| 成员集群 | Pod 分布总览 | Pod 分布详情 |
|---|---|---|
VKE-POC1 | 优先级:3,共 6 Pod |
|
VKE-POC2 | 优先级:2,减少 6 Pod,共 2 Pod |
|
ACK-POC | 优先级:1,减少 2 Pod,共 2 Pod |
|
步骤六:GPU 算力负载跨云弹性伸缩
- VKE 集群安装监控组件:确保 VKE 已经安装监控组件,并开启指标监控规则。
- 前往容器服务控制台,在 VKE-POC1、VKE-POC2 的集群详情的组件管理模块,确保已经安装基础指标组件(metrics-server)、custom metrics 指标组件(prometheus-adapter),以及 VMP 监控组件(prometheus-agent)。详细介绍参见:安装组件。
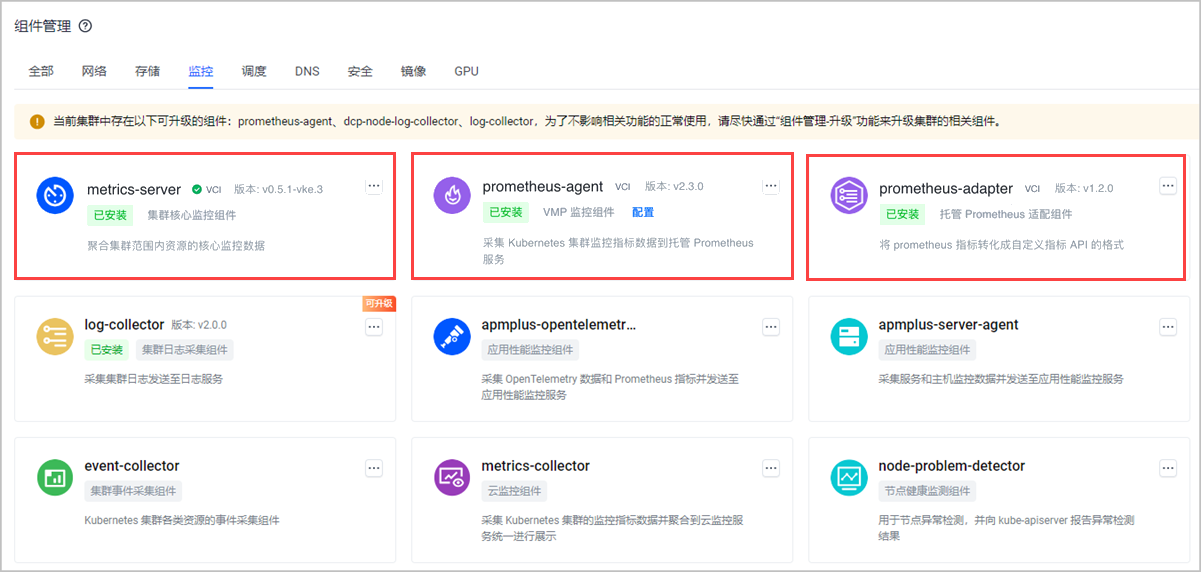
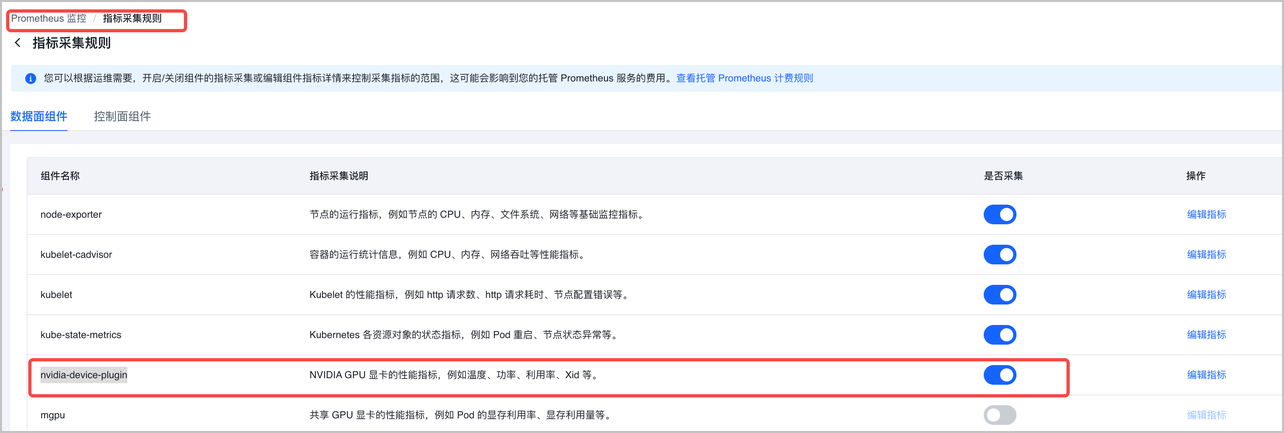
- 开启 nvidia-device-plugin 指标采集。若初次使用托管 Prometheus 服务,需要创建并绑定一个工作区后才能开启 nvidia-device-plugin 指标采集配置。详细介绍参见:配置采集指标。
- ACK 集群安装监控组件:确保 ACK 集群已经安装监控相关组件。
- 确保阿里云侧的 ACK 集群已经安装基础指标组件(metrics-server)、custom metrics 指标组件(prometheus-adapter)、gpu exporter 组件。
- 通过分布式云原生平台,为 ACK 集群安装 VMP 监控组件(prometheus-agent),详细介绍参见:安装组件。
- 创建联邦中心式 HPA:在联邦主控实例中创建 HPA 资源,HPA 初始弹性范围 6~15 副本,除非阈值为 GPU 使用率超过 50%。
HAP 资源的 Yaml 示例如下,创建详细步骤参见:添加 CRD 资源。
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: labels: kubeadmiral.io/hpa-mode: centralized # HPA资源必须添加这个标签来开启中心式HPA模式 name: fed-hpa namespace: default spec: maxReplicas: 15 metrics: - pods: metric: name: k8s_pod_rate_gpu_used # GPU 使用率指标 target: averageValue: "50" type: AverageValue type: Pods minReplicas: 6 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: fed-dp-gpu # 生效的目标工作负载名称
预期结果
- 工作负载副本从 10 扩容到 15。
- 副本在多集群和单集群中的资源池分布与 步骤三:GPU 算力负载跨云并发调度、步骤四:GPU 算力负载跨云优先级调度 中的行为一致。
- 调整联邦 HPA 弹性范围:
在联邦主控实例中修改 HPA 资源的最大副本数为 20。编辑 HAP 的详细步骤参见:编辑 CRD 资源。
预期结果
- 工作负载副本从 15 扩容到 20。
- 副本在多集群和单集群中的资源池分布与 步骤三:GPU 算力负载跨云并发调度、步骤四:GPU 算力负载跨云优先级调度 中的行为一致。