使用官方模型
最近更新时间:2024.01.30 15:29:35
首次发布时间:2023.09.11 10:02:29
本文介绍了如何使用边缘智能的官方推理模型。您可以选择合适的官方推理模型,将其部署到您的一体机进行使用。
前提条件
操作步骤
登录边缘智能控制台。
在左侧导航栏顶部的 我的项目 区域,选择您的项目。
- 在左侧导航栏,选择 边缘推理 > 模型管理。
- 单击 官方模型 页签。
官方模型 页签展示了所有官方推理模型的基础信息。 - 找到您需要使用的模型,单击模型名称。
您将会进入模型详情页面。在模型详情页面,您可以了解模型的 基本信息、Tensor配置、版本管理(包括已发布的 模型版本、已有的 前后处理版本) 信息。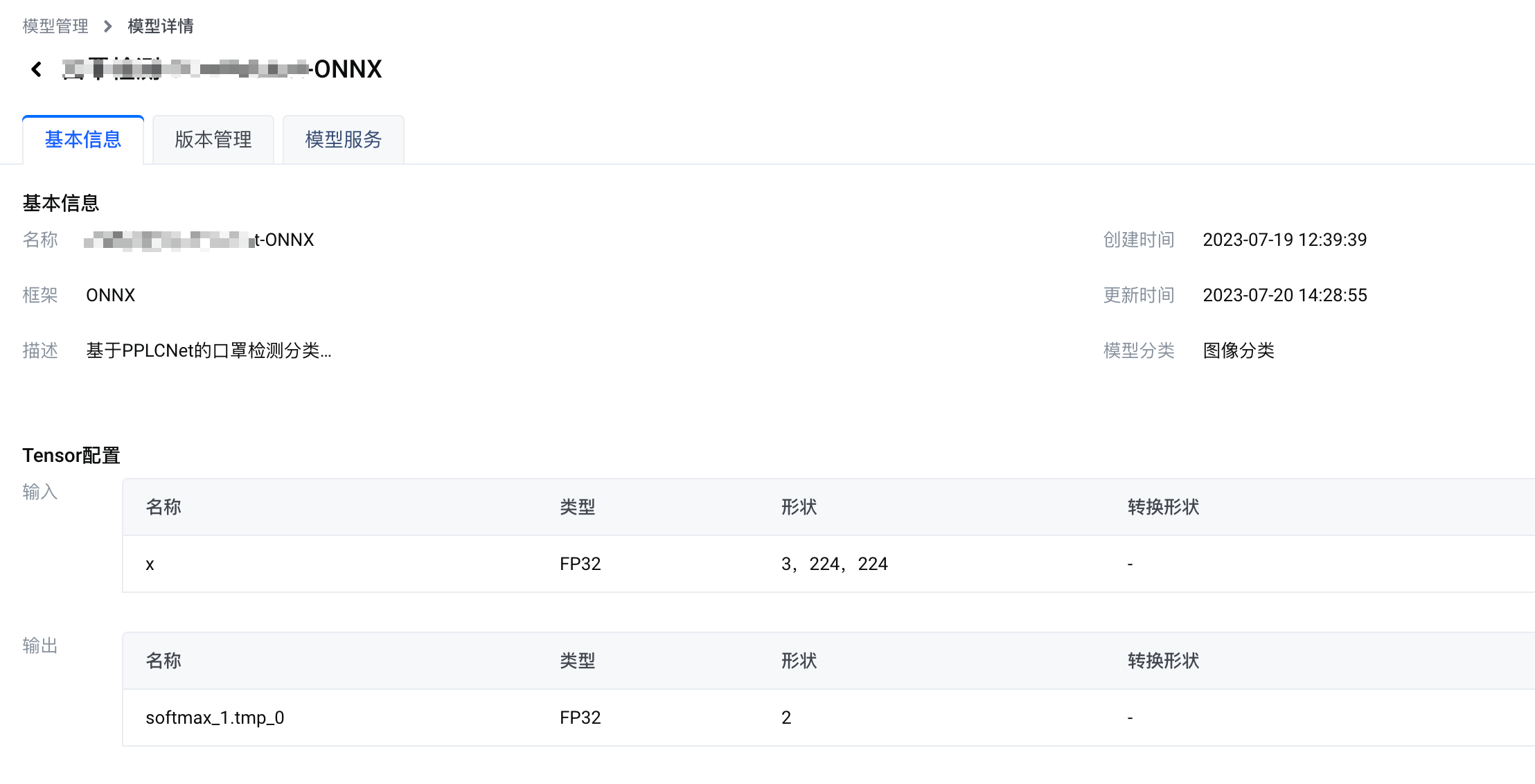
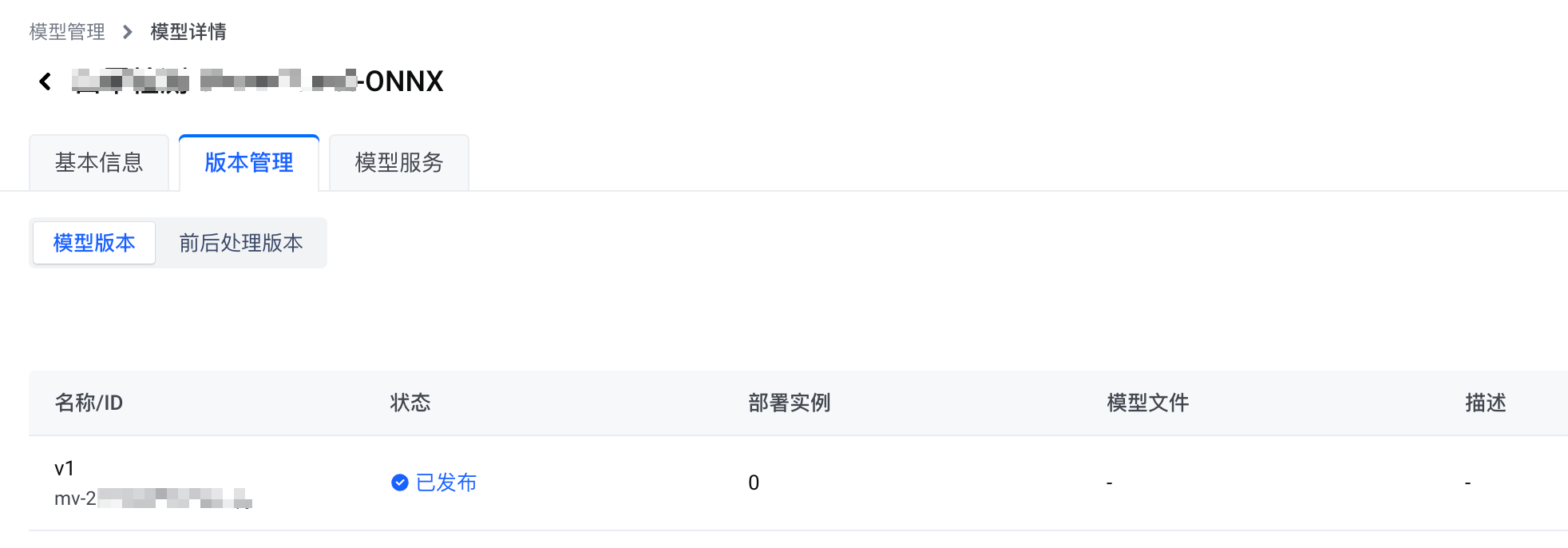
- 部署官方模型。
- 单击 模型服务 页签,然后单击 部署模型服务。
- 在 部署模型服务 页面,完成相关参数的设置,然后单击 确认。
| 区域 | 参数 | 说明 |
|---|---|---|
| 基本信息 | 项目 | 固定为当前选择的项目。 |
| 一体机 | 选择需要部署模型服务的一体机。 | |
服务名称 | 为模型服务设置名称。输入要求如下:
| |
| 模型信息 | 模型 | 固定为当前选择的官方模型。 |
| 模型版本 | 选择要部署的模型版本。 | |
| 模型前后处理版本 | 选择要部署的模型前后处理版本。关于前后处理版本的详细说明,请参见为模型创建版本。 | |
| 服务配置 | 服务状态类型 | 固定为 无服务状态。 |
| 最大批处理大小 | 设置最大批处理数量。取值范围:0 ~ 100。 | |
HTTP端口 | 输入 HTTP 服务端口。端口范围:30000 ~ 40000。 | |
GRPC端口 | 输入 GRPC 服务端口。端口范围:30000 ~ 40000。 | |
部署实例 | 为每个子模型分别配置 CPU模型服务实例数 和 GPU模型服务实例数。
| |
资源配置 | 为模型服务分配一体机资源。
注意 如果模型服务在 CPU 或内存方面超过限额,容器将会被终止。 | |
| 高级配置 | 动态批处理 | 设置是否开启动态批处理功能。该功能让模型服务器得以将多个推理请求组合,动态地生成一个批次。一般来说,创建请求批次可以优化吞吐量。 |
最大批处理延迟 | 设置批处理延迟的最大时间。单位:us。取值范围:0~1000000。超过该时间会立刻开始推理。 说明 该参数只在 动态批处理 为 是 时出现。 | |
是否开启压缩模式 | 选择是否采用输入压缩模式来部署模型服务。 说明 当 模型 是 Ensemble 类型时,无法开启压缩模式。 在模型服务与数据流分开部署的场景(如云边协同)建议开启输入压缩模式。开启输入压缩模式后,模型服务的部署会自动转化为一个 Ensemble 联合模型服务的部署,它包含三部分:Ensemble 模型,Python 前处理模型以及您选择的模型本身。
| |
参数配置 | 您可以通过该参数自定义参数配置,并将您的参数配置发送到一体机。 说明
|
完成上述操作后,您可以在 模型服务 列表查看已经部署的模型服务。当模型服务的状态变为 运行中,表示模型服务已经部署成功。