Hadoop 使用 Proton
最近更新时间:2024.05.06 16:42:53
首次发布时间:2023.05.17 14:27:25
下文首先介绍在 火山引擎EMR 和 自建Hadoop集群 两种场景下,如何使用Proton实现存算分离架构。接着介绍存算分离模式下回收站的配置方式,最后介绍如何在开发环境中引入 proton 依赖。
1 火山引擎EMR
1.1 认证配置
1.1.1 使用 Assume Role 认证 TOS
Assume Role 不需要您显性的将自己账号 AK/SK 配置进集群,集群在运行过程中会自动通过 IAM 获取临时身份凭据。
前置条件
开通火山引擎 E-MapReduce(EMR)服务,且创建EMR集群。详见创建集群。
开通对象存储服务 TOS 服务,且创建 TOS 桶。详见:TOS快速入门。
创建 EMR 集群时,其他设置 > 高级设置 > 集群角色,选择的集群角色确保需有 TOS 的权限:
- 进入 IAM访问控制 > 角色管理,单击新建角色按钮创建角色。详见:角色管理
- 给角色添加对应的 TOS 全读写访问权限:TOSFullAccess。
说明
- 若创建 EMR 集群时,没有选择集群角色,则集群默认会添加 ECS 角色:VEECSforEMRRole。
- 高级设置 > 集群角色 选择时,下拉框没有展现新建的角色,请检查 角色详情 > 信任关系中,“Service”参数下是否有“Volc_ECS”的关系,添加上即可。
使用 TOS
可直接在 EMR 集群中使用 TOS 服务,例如可使用 HDFS 命令:
hadoop fs -ls tos://您的bucket name/
列出 TOS 桶内的文件,如果需要在计算引擎,例如 Hive 中以表的形式处理 TOS 内的数据,可以在创建 Hive 表的时候将 location 字段值设置成 TOS 地址,即可分析 TOS 的数据,例如:
CREATE EXTERNAL TABLE `palmplay_log_pv_csv`( `meta_id` STRING COMMENT 'from deserializer', `brand` STRING COMMENT 'from deserializer', `channel` STRING COMMENT 'from deserializer', `countrycode` STRING COMMENT 'from deserializer') PARTITIONED BY (dt String) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' STORED AS TEXTFILE LOCATION 'tos://您的tos bucket name/';
对于 EMR 内的任何组件,您均可以 tos:// 开头的地址去消费 TOS 的数据,关于更多引擎使用 TOS的内容,请查看对应的引擎文档。
1.1.2 使用静态 AK/SK
静态 AK/SK 会将永久的身份信息记录在集群的配置文件中,不方便管理。
前置条件
开通 EMR 服务,且创建EMR集群。详见:创建集群。
开通 TOS 服务,且创建 TOS 桶。详见:TOS快速入门。
通过 IAM 访问控制 > 密钥管理获取 Access Key ID 和 Secret Access Key。详见:访问秘钥。
在 EMR 集群详情页的服务列表 > HDFS > 服务参数 > 添加自定义参数配置中给 core-site 新增如下自定义参数:
fs.tos.access-key-id=您的AK fs.tos.secret-access-key=您的SK如果您的 EMR 版本为 Hadoop3 系列,且版本号小于 3.2.1(不包含),或者为 Hadoop2 系列,且版本号小于 2.2.0(不包含),请使用如下方式配置:
fs.tos.access.key=您的Access Key ID fs.tos.secret.key=您的Secret Access Key如果您想针对不同 bucket 使用不同的认证密钥,可使用如下配置:
fs.tos.bucket.您的bucket.access.key=您的Access Key ID fs.tos.bucket.您的bucket.secret.key=您的Secret Access Key使用 TOS
可直接在 EMR 集群中使用 TOS 服务,例如可使用 HDFS 命令:
hadoop fs -ls tos://您的bucket name/
列出 TOS 桶内的文件,如果需要在计算引擎,例如 Hive 中以表的形式处理 TOS 内的数据,可以在创建 Hive 表的时候将 location 字段值设置成 TOS 地址,即可分析 TOS 的数据,例如:
CREATE EXTERNAL TABLE `palmplay_log_pv_csv`( `meta_id` STRING COMMENT 'from deserializer', `brand` STRING COMMENT 'from deserializer', `channel` STRING COMMENT 'from deserializer', `countrycode` STRING COMMENT 'from deserializer') PARTITIONED BY (dt String) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' STORED AS TEXTFILE LOCATION 'tos://您的tos bucket name/';
对于 EMR 内的任何组件,您均可以 tos:// 开头的地址去消费 TOS 的数据,关于更多引擎使用 TOS 的内容,请查看对应的引擎文档。
1.1.3 环境变量配置 AK/SK
前置条件
export TOS_ACCESS_KEY_ID=您的Access Key ID export TOS_SECRET_ACCESS_KEY=您的Secret Access Key export ENV_TOS_SESSION_TOKEN=您的Token在当前 shell 上下文中使用 export 关键字将对应的 AK/SK 通过环境变量的方式注入。
使用 TOS
可直接在 EMR 集群中使用 TOS 服务,例如可使用 HDFS 命令:
hadoop fs -ls tos://您的bucket name/
列出 TOS 桶内的文件。
1.2 参数调优
由于火山 EMR 默认集成了 Proton,且已经在相关组件开启,您无需做额外配置,可通过修改 core-site.xml 配置文件,对参数进行调优设置,具体的参数内容请参考 Proton 参数配置 的参数调优部分。
2 自建 Hadoop 集群
2.1 Hadoop3 系列
2.1.1 下载依赖
请参考 Proton 发行版本 中的版本信息,选择您对应的 Proton 版本,下载对应的 Proton 包,放入 HDFS 安装目录下的 share/hadoop/hdfs/ 中。
2.1.2 配置修改
修改 core-site.xml,新增如下内容:
<configuration> <!--Required properties--> <!--Filesystem implementation class for TOS--> <property> <name>fs.AbstractFileSystem.tos.impl</name> <value>io.proton.fs.ProtonFS</value> </property> <property> <name>fs.tos.impl</name> <value>io.proton.fs.ProtonFileSystem</value> </property> <property> <name>fs.tos.endpoint</name> <value>http://tos-cn-beijing.volces.com</value> </property> <property> <name>proton.cache.enable</name> <value>false</value> </property> <!--Optional properties--> <!--Job Commiter implementation class--> <property> <name>mapreduce.outputcommitter.factory.class</name> <value>io.proton.commit.CommitterFactory</value> <description>The job committer implementation class accelerate read and write data to TOS object storage via MPU instead of rename.</description> </property> <property> <name>fs.tos.credentials.provider</name> <value>io.proton.common.object.tos.auth.DefaultCredentialsProviderChain</value> </property> <!-- Credential provider mode 2: static AK/SK for all buckets --> <property> <name>fs.tos.credentials.provider</name> <value>io.proton.common.object.tos.auth.SimpleCredentialsProvider</value> </property> <property> <name>fs.tos.access-key-id</name> <value>yourAk</value> </property> <property> <name>fs.tos.secret-access-key</name> <value>yourSk</value> </property> <!--TOS Client configuration--> <!--we can overwrite these properties to optimize TOS read and write performance--> <property> <name>fs.tos.http.maxConnections</name> <value>1024</value> </property> </configuration>
2.2 Hadoop2 系列
2.2.1 下载依赖
请参考 Proton 发行版本 中的版本信息,选择您对应的 Proton 版本,下载对应的 Proton 包,放入 HDFS 安装目录下的 share/hadoop/hdfs/ 中。
2.2.2 配置修改
Hadoop2 下的配置与 Hadoop3 相同,请参考 Hadoop3 关于 Job committer 的配置,由于开源 Hadoop2 中的 HDFS 默认不支持外部 Job Committer 接口,因此如果要使用 JobComitter,需要下载火山修改过后的 HDFS 依赖包。具体的下载方式,您可通过提工单的方式联系 EMR 技术同学进行支持。
2.3 参数调优
自建集群参数调优与火山 EMR 相同,请参考使用 Proton 概述-参数调优。
3 回收站配置
HDFS删除文件后,文件并不会立即删除,而是会将文件移入回收站,默认地址为 hdfs://cluster/user/用户名/.Trash/ ,可在core-site中使用如下参数配置回收站中的文件的生命周期时间:
<property> <name>fs.trash.interval</name> <value>1440</value> <description>Number of minutes after which the checkpoint gets deleted. If zero, the trash feature is disabled.</description> </property>
NameNode将会基于配置的值,定期的清理回收站中的文件,在存算分离架构下,使用对象存储后,EMR成为了一个无状态的计算引擎,因此并不会存在一个常驻的回收站管理服务,需要用户自行管理,可通过如下两种方式,控制回收站的生命周期。
3.1 禁用回收站
如果不存在回收站的诉求,可在 EMR的服务列表-hdfs-配置管理中修改core-site的fs.trash.interval配置项,将其对应的值设置为0。
3.2 配置对象存储生命周期管理方案
如果对回收站存在诉求,希望保留回收站功能,则可在对象存储页面中,进入对应的bucket,创建对应的生命周期管理规则:
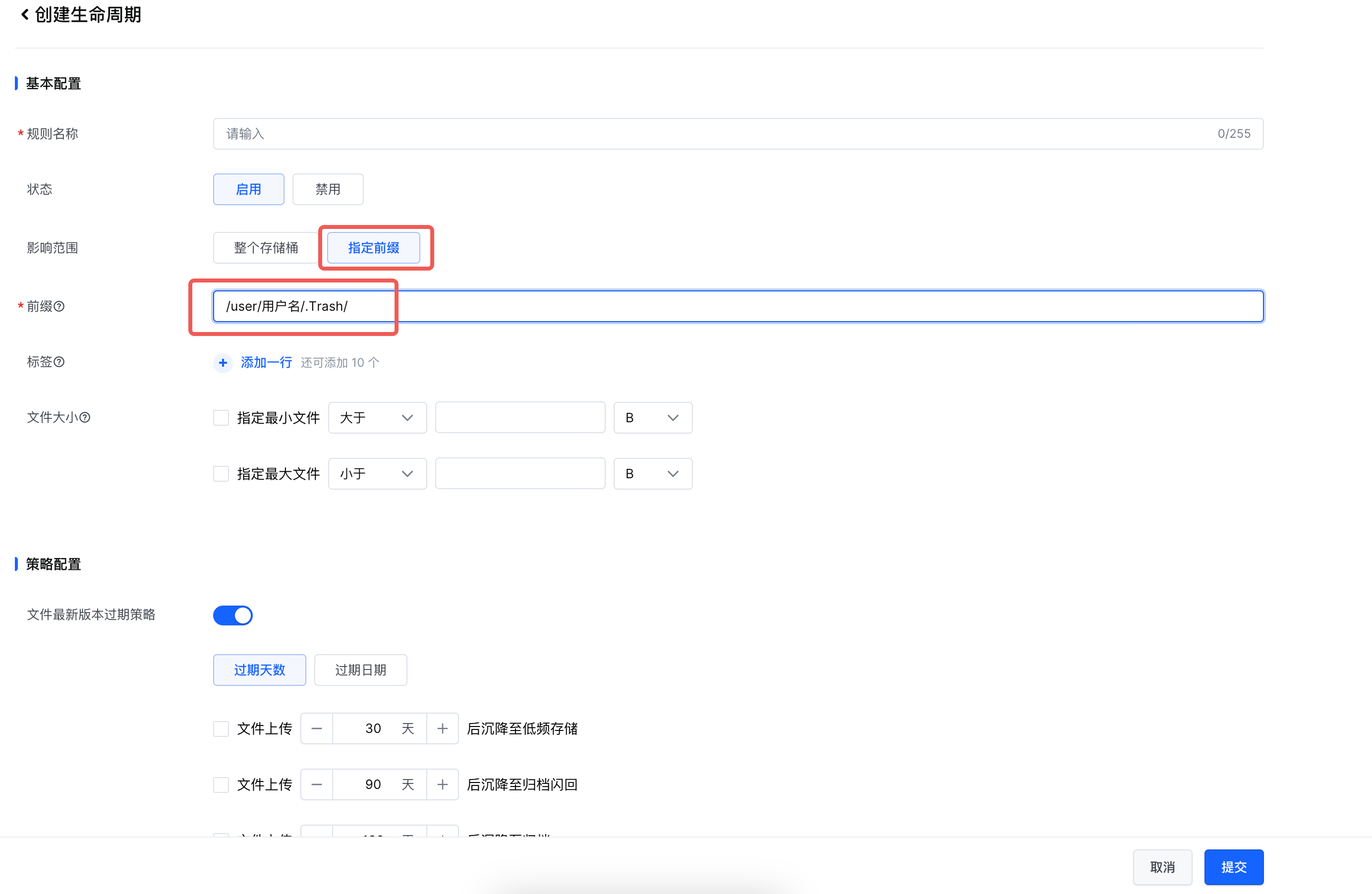
选择使用指定前缀方式,且基于当前使用的bucket和用户,确定对应回收站的地址,进行生命周期的配置,更多使用方式,请参考:设置生命周期规则
4 开发指导
如果您在本地开发类似代码,需要调试测试 TOS 且使用 Committer,可下载对应的 Job committer bundle 依赖包,放入工程根目录,再您的 pom.xml 中新增:
<dependency> <groupId>io.proton/groupId> <artifactId>proton-hadoop您的Hadoop版本-bundle</artifactId> <version>1.1</version> <scope>system</scope> <systemPath>${project.basedir}/Name_Your_JAR.jar</systemPath> </dependency>