SQL诊断使用说明
最近更新时间:2024.05.11 17:44:16
首次发布时间:2024.01.12 15:35:37
1 SQL诊断功能介绍
SQL 诊断开启后会自动记录所有的慢查询,您可以使用前端界面使用各种条件进行检索。选中具体的查询,SQL 诊断还能为您提供查询的细节、每个算子的统计数据、查询计划的可视化界面、以及自动生成的查询诊断和调优建议。
SQL 诊断自动记录所有的慢查询和失败查询的 Query Profile,最多会保存过去 30 天、最多 50000 条查询记录。
1.1 进入SQL诊断页面
登陆火山引擎,进入 EMR Serverless OLAP控制台;
点击实例列表,选中你需要查看的StarRocks实例,进入实例详情页面;
点击左侧的 SQL 诊断标签。
1.2 SQL诊断自动收集参数
SQL 诊断自动记录两类查询:大于等于 5 秒的慢查询,和失败的查询。
您可以通过 Session 变量 auto_profile_slow_query_threshold_ms 调整慢查询的阈值,或者完全关闭慢查询自动收集:
auto_profile_slow_query_threshold_ms为 -1 时,关闭自动收集关闭。auto_profile_slow_query_threshold_ms为 0 时,收集所有查询的信息。auto_profile_slow_query_threshold_ms大于 0 时,会自动收集执行时间大于配置值的慢查询。
例如,set global auto_profile_slow_query_threshold_ms= 10000 修改为自动记录大于等于 10 秒的慢查询,使用 global 关键字全局生效。
您可以通过 Session 变量 enable_profile 配合 auto_profile_slow_query_threshold_ms收集特定查询的 Runtime Profile 信息存储并展示在SQL诊断中。例如,临时配置任意查询并记录到查询诊断中,
set enable_profile=true; set auto_profile_slow_query_threshold_ms=0;
此例子设置了 auto_profile_slow_query_threshold_ms=0,会将本次会话的查询全部收集,包括耗时低于5s的查询。当需要重新调整慢查询记录的阈值时,只需要更改auto_profile_slow_query_threshold_ms 为默认值即可。
2 SQL诊断界面
2.1 查询监控图
查询监控图显示耗时 Top 100 的查询分布,可以方便快速定位耗时长的查询。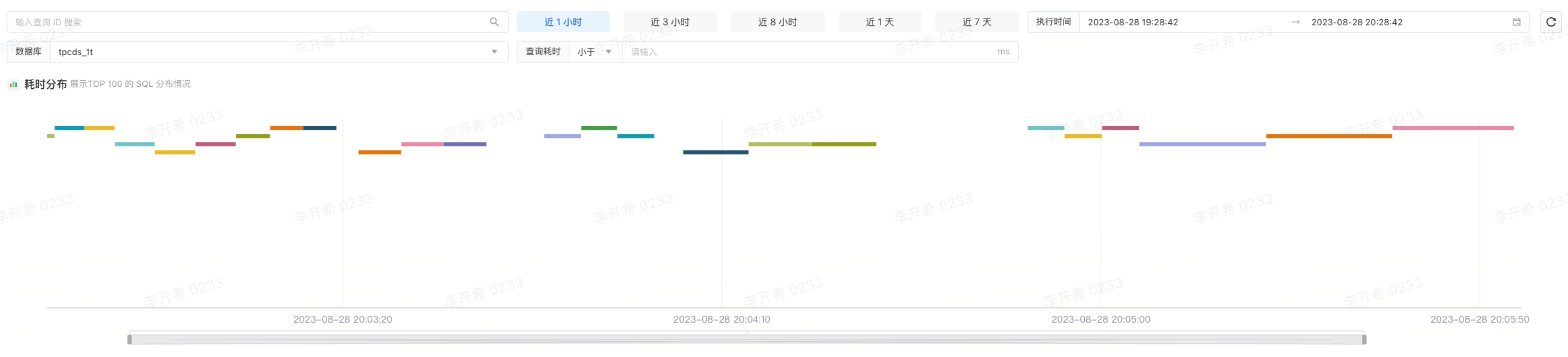
2.2 SQL列表
SQL列表展示了查询的各种基本信息,可以按照不同条件进行搜索。点击查询 ID 可以进入查询详情页。
2.3 查询详情页
2.3.1 查询概述
查询总览展示了查询的详细信息,例如开始时间、执行用户、 SQL 文本等信息。
如果查询失败,还会展示失败的原因。失败查询的执行时间和 Profile 等信息可能缺失或者不完整。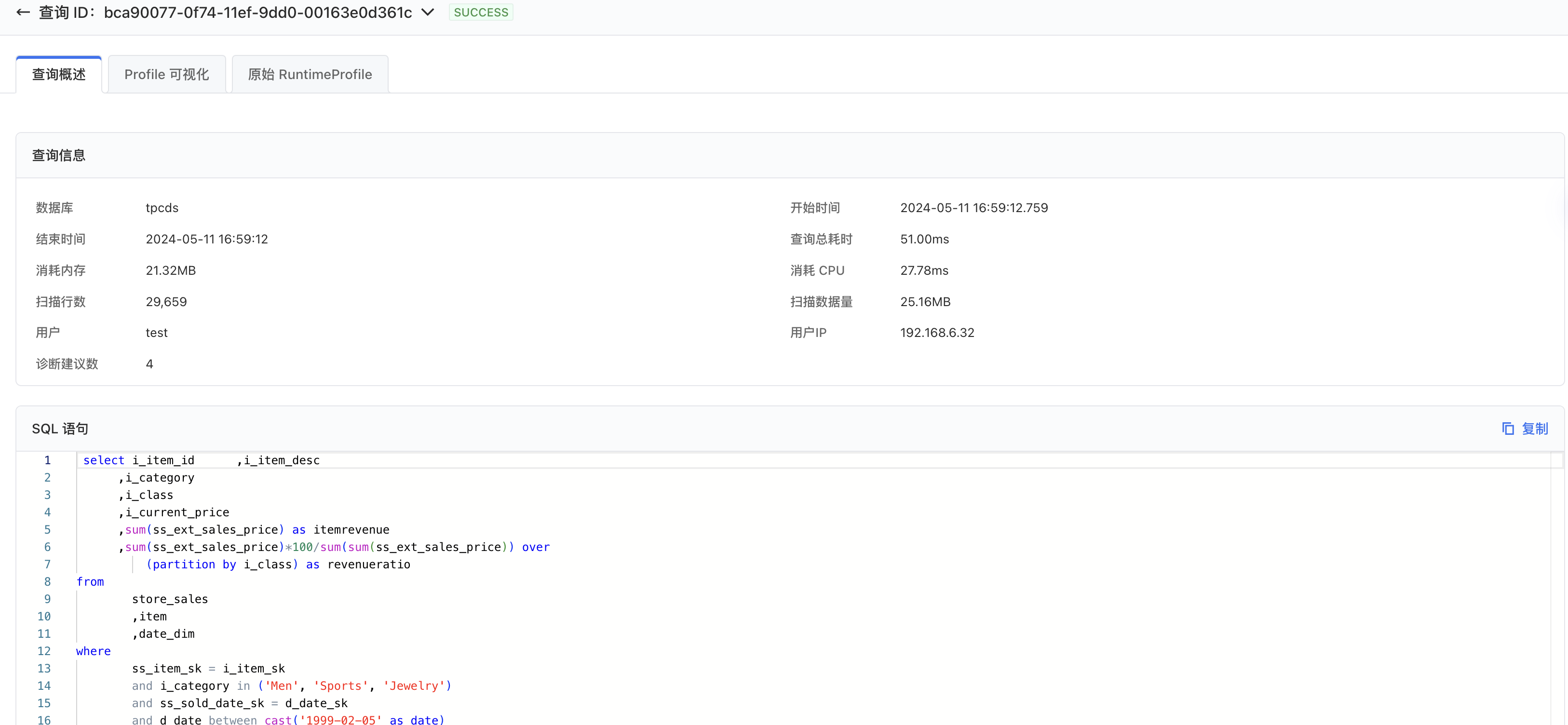
2.3.2 计划可视化
SQL 诊断可以可视化您的 Query Profile。
计划可视化页面包含左侧的树形图形式展示的节点树,和右侧的详情栏。
节点树
查询计划是由多个 Operator 的节点组成,每个节点代表了一个 Operator,数据流向自下而上,从数据源,经过中间算子层层处理后,最终由最上层的算子返回给客户端或者写入其他数据源。
节点会展示该 Operator 的名字,node id,简要信息,处理的行数,处理消耗的CPU 时间。
通过选中右上角按行数或按耗时,可以改变 Operator 展示的百分比规则,帮助您定位耗时最长或者处理数据最多的 Operator,确认查询的瓶颈。
Operator 会按照其所在的 Fragment 分组。Fragment 之间的数据流是通过网络完成的。不同的 Fragment 也意味着这些 Operator 属于不同的调度任务,可能有不同的并行度。
详情栏
没有选中任何节点时,右侧详情栏展示了查询 Query 级别的详细信息。
选中 Operator 节点时,右侧详情栏会展示该 Operator 的所有指标,以及该算子所属 Pipline 的指标。
选中 Fragment 节点时,右侧详情栏会展示该 Fragment 的所有指标。
2.3.3 原始 RuntimeProfile
SQL诊断是收集 StarRocks 的 RuntimeProfile,进行分析和处理,获取查询信息。最后绘制出可视化页面,得到诊断结果和建议。
原始 RuntimeProfile 展示 StarRocks 原始的 RuntimeProfile 信息。如果 Profile 可视化界面中缺少了某些信息,可以在原始 RuntimeProfile 中搜索。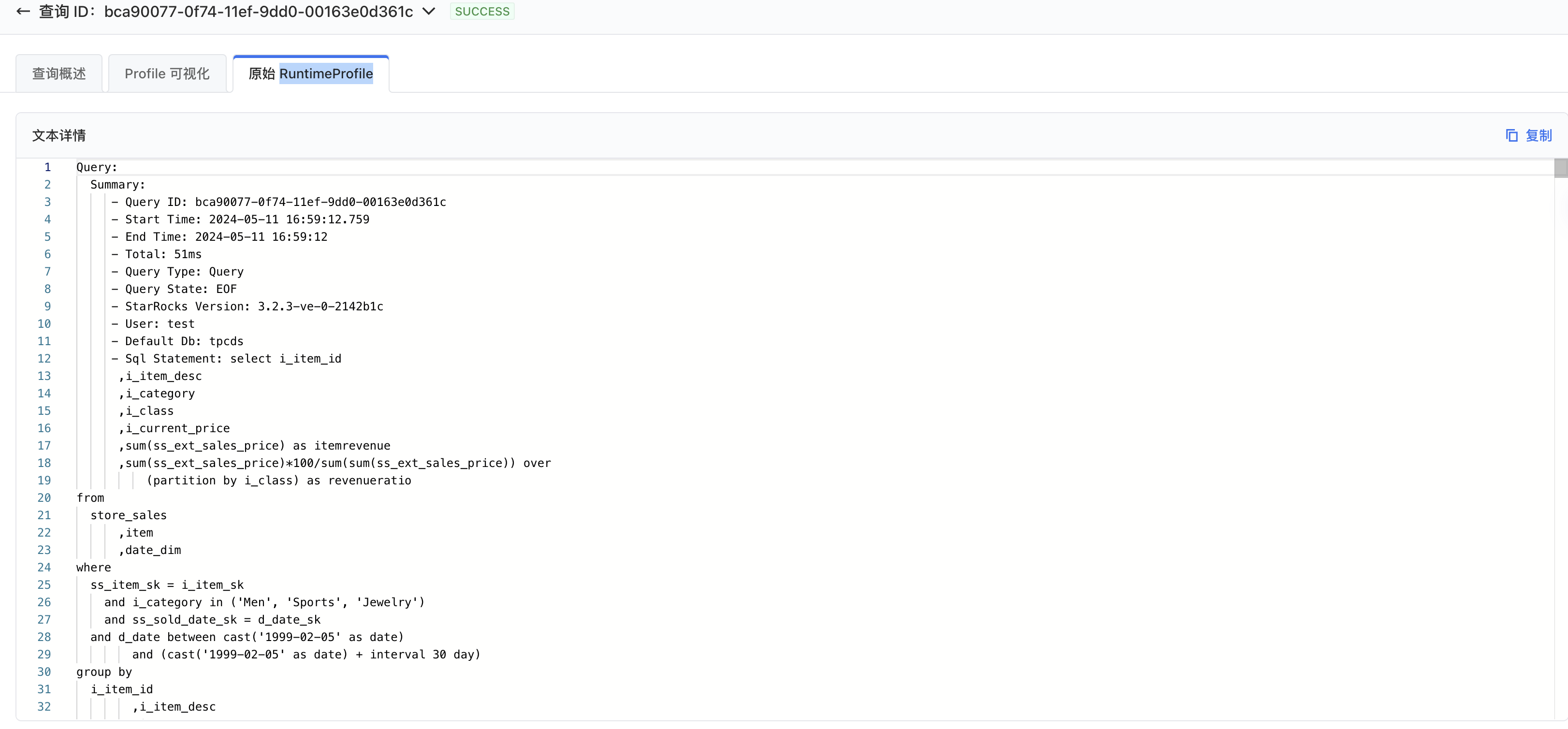
2.3.4 参考
- StarRocks 查看分析 Query Profile。
3 查询诊断
查询诊断会自动化的分析查询的各种指标,帮助您发现查询中的常见错误,定位潜在的性能瓶颈,给出一些诊断建议。诊断建议会展示在 Profile 可视化页面中的对应 Node 上。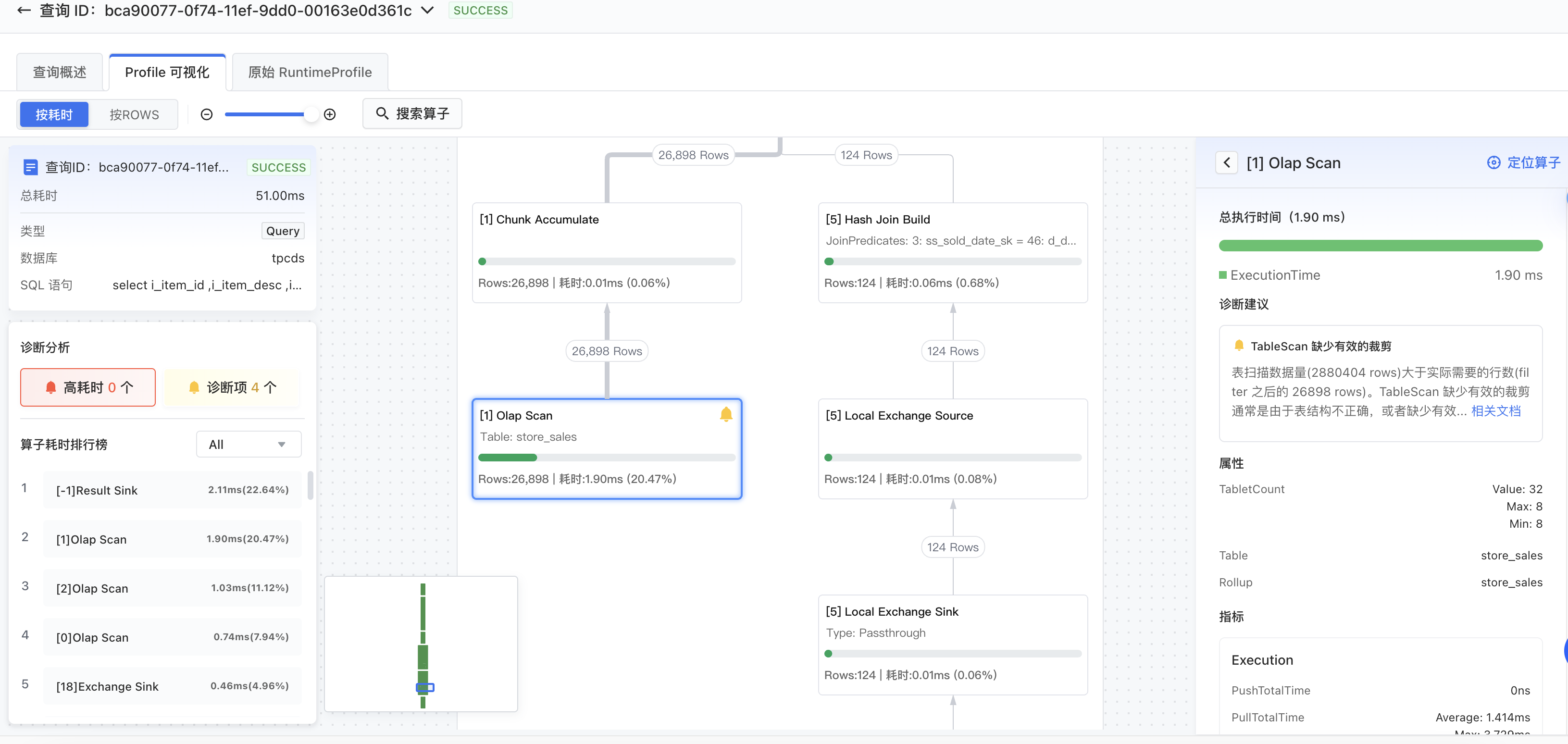
3.1 TableScan 缺少有效的裁剪
StarRocks 能够根据查询过滤条件,跳过表中不不需要的部分,减少数据扫描量。表扫描数据量大于实际需要的行数,称为 TableScan 缺少有效的裁剪。
TableScan 缺少有效的裁剪通常是由于表结构不正确,或者缺少有效的索引,导致存储无法利用查询条件过滤数据。还有可能是查询条件包含复杂的函数,无法用于过滤数据。
查询诊断的结果不一定正确。存储能做到的裁剪和过滤条件不同,只能减少部分的扫描量,其效果取决于数据量,正确的表结构和索引,同时也和查询条件以及真实数据有关。此外,不同条件有不同的过滤效果,可能适合不同的表结构和索引。
建议
检查表结构是否正确;
检查排序键是否合适;
检查是否需要添加索引;
检查查询条件是否包含函数,导致无法用于过滤数据。
参考
3.2 TableScan 扫描数据倾斜
StarRocks 数据分布在不同的存储节点上,如果分布字段不正确,数据据存储在各个节点上时也会不均匀。最终导致数据读取时,部分节点需要扫描更多的数据,导致查询长尾。
建议
- 检查分桶键是否合适。
参考
选择合适的分桶键。
使用 StarRocks 官方 table 分析工具, 下载 tools-20230413.tar.gz。
3.3 TableScan 读取字段个数较多
StarRocks 默认是列存引擎,读取字段较多会消耗更多的 IO 资源。
建议
优化SQL中不需要的字段;
考虑将查询按列拆分成多条查询。
3.4 Join 结果膨胀
合理 Join 条件,Join 的输出行数会小于或等于输入行数。如果 Join 的输出行数大于输入行数,会导致较多的计算资源和内存资源被占用,导致查询较慢。
Join 结果膨胀通常是缺少 Join 条件造成 Cross Join,或者错误的 Join 的条件导致一个表中一条记录与另一个表多条记录匹配。还有一些情况是缺少统计信息,或者数据变更后统计信息过期,导致优化器选择了错误的计划。
建议
检查 Join 条件是否缺失,添加更多的查询条件,避免 Join 结果膨胀;
Join 条件对应的列,更应该使用 INT、DATE 等简单类型;
检查统计信息是否收集或过期;
如果是多表 Join,检查 Join 顺序是否正确,如果不正确,可以设置 session 参数
disable_join_reorder,手动调整查询中的 Join 顺序。
参考
3.5 Join 右表过大
StarRocks 的 Hash Join 使用右表在内存中构建 Hash 表。右表过大,会消耗更多的内存资源。
Join 右表过大可能是复杂的 Join 条件或关联查询导致优化器没有优化顺序,例如 FULL OUTER JOIN。也可能是缺少统计信息,或者数据变更后统计信息过期,导致优化器选择了错误的计划。
建议
检查统计信息是否收集或过期;
设置 session 参数
disable_join_reorder,手动调整查询中的 Join 顺序。
3.6 Join 不应该使用广播
StarRocks 是分布式引擎,Join 需要按 Join 条件将两张表的数据重分布到相同的节点。如果右表远小于左表,Broadcast Join 可以将右表广播到所有节点,避免左表的重分布,虽然复制了一部分数据,但是整体上减少了网络传输开销。
某些情况下,缺少统计信息,或者数据变更后统计信息过期,导致优化器错误地估计了表的大小,导致了较大的表也使用了 Broadcast Join,让大量的数据被广播。大量的数据被广播不仅会加重网络传输开销,也会导致计算的数据量变大。
建议
- 在 JOIN 关键字后添加 hint
[shuffle],限制使用 Boardcast Join。例如:select a.x, b.y from a join [shuffle] b on a.x1 = b.x1
3.7 Join 应该使用广播
StarRocks 是分布式引擎,Join 需要按 Join 条件将两张表的数据重分布到相同的节点。如果右表远小于左表,Broadcast Join 可以将右表广播到所有节点,避免左表的重分布,虽然复制了一部分数据,但是整体上减少了网络传输开销。
建议
- 在 JOIN 关键字后添加 hint
[broadcast],让 Join 使用 Broadcast。例如:select a.x, b.y from a join [broadcast] b on a.x1 = b.x1
3.8 Aggreagte 聚合度低
StarRocks 是分布式执行引擎,聚合操作会先在本地聚合,减少网络传输;
聚合算子如果比较复杂,可能在本地聚合时无法减少数据,不但不能减少网络数据传输,反而会消耗大量的计算资源。
建议
- 通过 Session 参数
set new_planner_agg_stage = 1关闭二阶段 Aggreagte。
3.9 Fragment 处理数据量倾斜
StarRocks 是分布式执行引擎,每个 Fragment 会拆分成多个 Instance 在不同 BE 节点执行。如果源表数据倾斜,或者数据本身具有某种分布,会导致每个节点处理数据不均匀,导致长尾,影响查询性能。
建议
参考 TableScan 扫描数据量倾斜,检查表结构是否合理;
检查业务数据中是否存在大量非正常的数据,例如 null,导致分布不均。使用过滤条件前提过滤这些数据。
3.10 查询返回客户端的数据量较大
大量数据通过客户端返回会占用较多的 FE 资源。
建议
添加 LIMIT 或者添加更多的过滤条件;
通过数据导出工具,将数据导出至其他系统,避免使用客户端直接查询。
参考
- 使用 EXPORT 导出数据。
3.11 查询生成的Fragment个数较多
查询过于复杂,会占用较多的计算和网络资源,可能影响其他查询的查询性能。
建议
- 使用 Flink 等 ETL 工具,预处理数据减少查询中 Join 数量。
3.12 查询消耗的内存资源较大
查询占用了大量内存,可能影响其他查询的查询性能。
建议
减少 Aggregate,Sort 算子;
使用更大规模的集群。
3.13 查询读取的数据量较大
查询占用了大量的 IO 资源,可能影响其他查询的查询性能。
建议
检查表结构是否正确,或者缺少有效的索引;
添加更多的过滤条件,或者检查已有的查询条件能否用于 TableScan 裁剪;
使用更大规模的集群。