GPU 监控
最近更新时间:2024.02.28 20:04:51
首次发布时间:2023.08.11 10:50:28
容器服务支持监控集群节点的 GPU 资源状态。本文为您介绍如何配置和查看 GPU 监控信息。
前提条件
- 容器服务集群已接入托管 Prometheus,详情请参见 接入托管 Prometheus。
- 已安装 nvidia-device-plugin 组件,并同步安装了 dcgm-exporter 插件,详情请参见 安装组件。
- 已安装 mgpu 组件,并同步安装了 mgpu-exporter 插件,详情请参见 安装组件。
- prometheus-agent 组件已经升级到 v2.2.0 及以上版本。详情请参见 组件发布记录。
操作步骤
当您将容器服务集群正确接入托管 Prometheus,并安装了对应的组件后,需要配置对应的采集规则,才能正确采集指标。
- 登录 容器服务控制台。
- 在左侧导航栏中选择 集群。
- 在集群列表页面,单击目标集群。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在配置页面右上角,单击 指标采集配置。
- 选择 数据面组件 页签,在组件列表 是否采集 列,单击开关,开启 nvidia-device-plugin 和 mgpu 组件的采集规则。
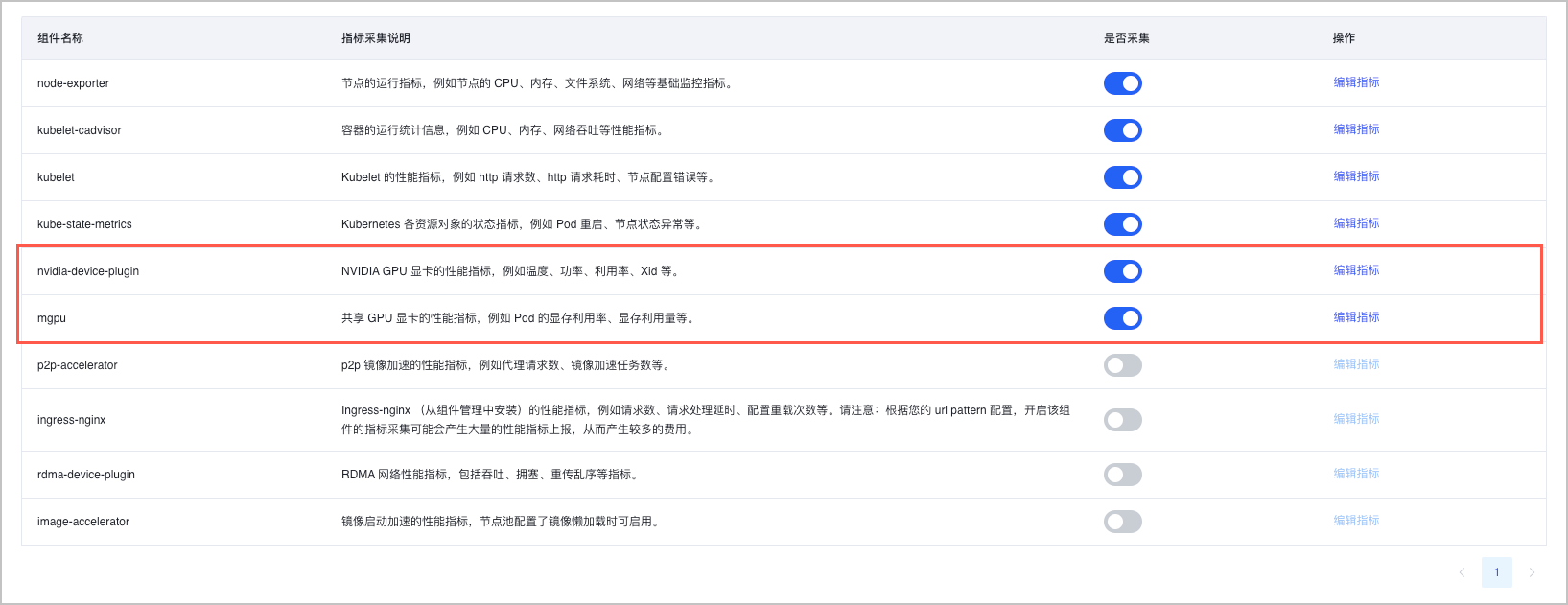
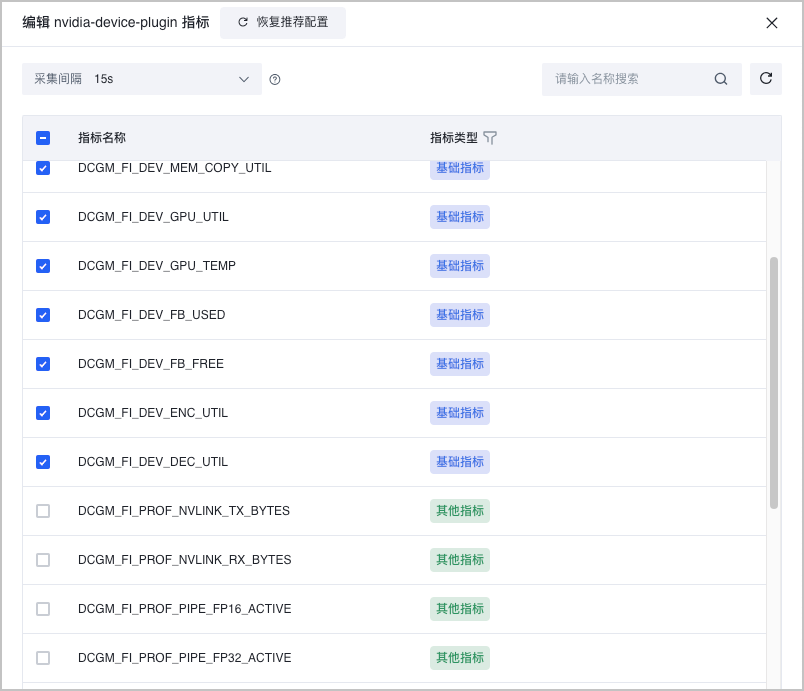
- (可选)单击组件列表 操作 栏中的 编辑指标,支持选择或丢弃组件的具体指标,并配置面向该组件的采集间隔。
- 在 采集间隔 下拉菜单中,选择该组件指标的采集间隔。不同组件支持的采集间隔不同。
- 在指标列表中,勾选指标,则采集该指标。取消勾选,则丢弃该指标。单击 指标类型 表头,允许基于指标类型对指标项进行筛选。
说明
- 减小指标采集间隔,会增加单位时间内上报的指标数量,可以提升监控精度。但会增加托管 Prometheus 标准版工作区的费用。增加指标采集间隔,会减少单位时间内上报的指标数量,可以减少托管 Prometheus 标准版工作区的费用,但会降低监控精度。请根据实际需要配置。
- 云产品的指标类型分为 基础指标 和 其他指标,不同类型指标的计费方式不同,详情请参见 托管 Prometheus 计费方式。
查看大盘
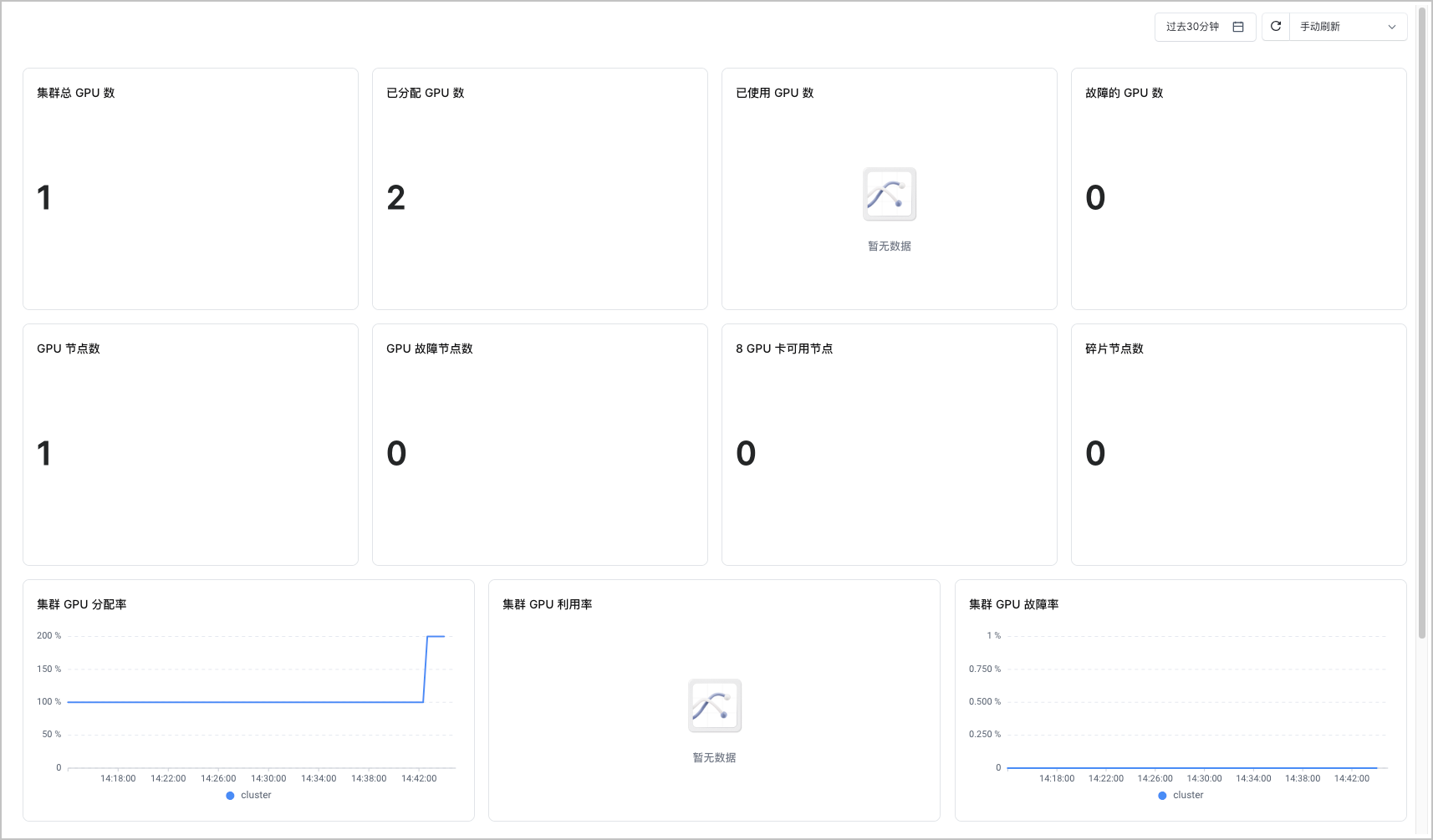
集群 GPU 监控
集群 GPU 监控大盘展示了集群纬度的 GPU 监控信息,包括:集群总 GPU 数、已分配 GPU 数、已使用 GPU 数等。您可以从该大盘中了解整个集群的 GPU 监控信息。支持设置查询的时间段,并指定刷新方式(手动刷新、自动刷新)。
- 登录 容器服务控制台。
- 在左侧导航栏中选择 集群。
- 在集群列表页面,单击目标集群。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 GPU 监控 > 集群 GPU 监控,即可查看监控大盘。
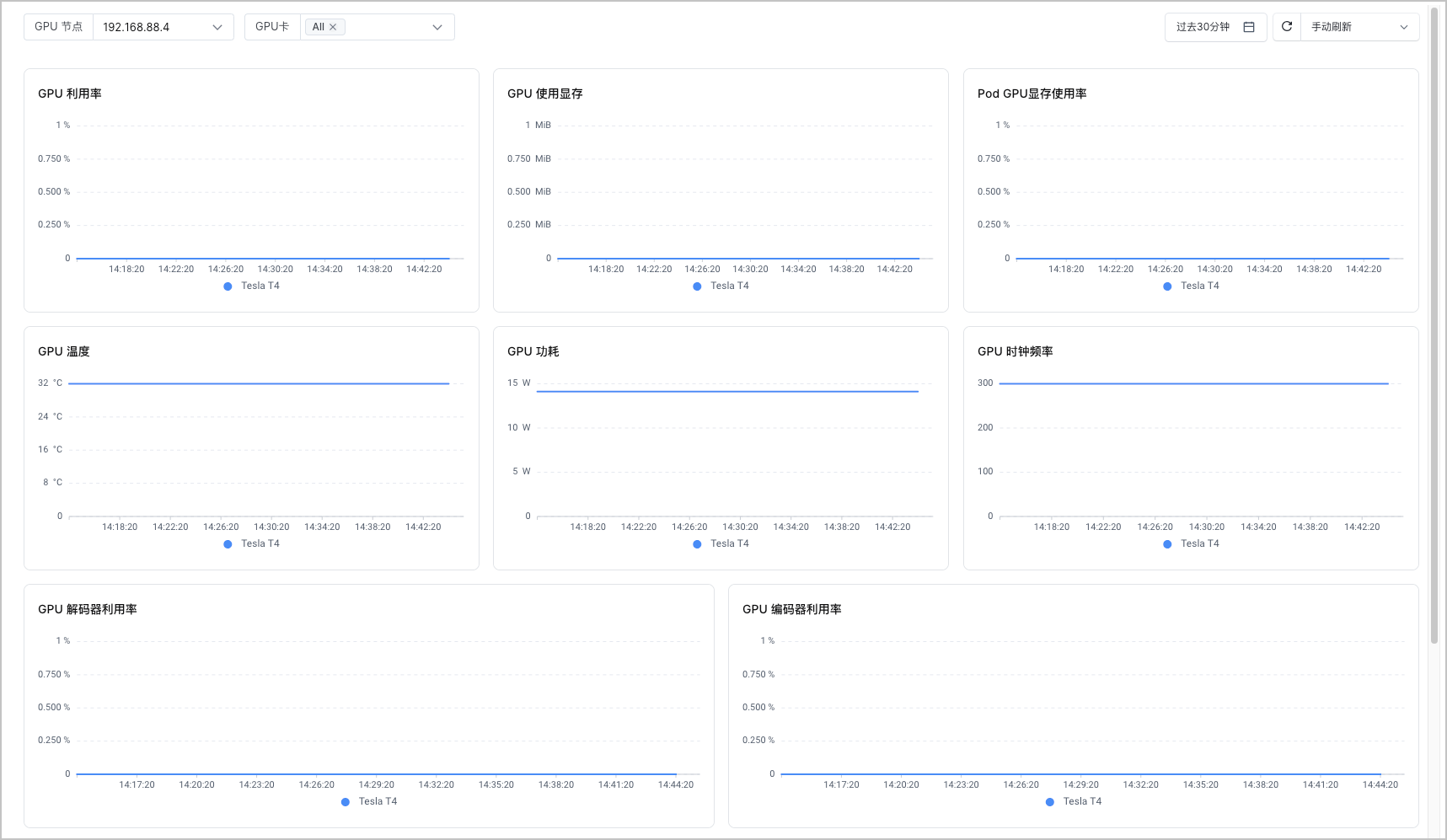
GPU 实例监控
GPU 实例监控大盘展示了 GPU 卡实例纬度的 GPU 监控信息,包括:GPU 利用率、GPU 使用显存、GPU 温度、GPU 功耗等。您可以从该大盘中了解指定 GPU 卡的监控信息。支持设置查询的时间段,并指定刷新方式(手动刷新、自动刷新)。
- 登录 容器服务控制台。
- 在左侧导航栏中选择 集群。
- 在集群列表页面,单击目标集群。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 GPU 监控 > GPU 实例监控,即可查看监控大盘。
容器组 GPU 监控
容器组 GPU 监控大盘展示了容器组纬度的 GPU 监控信息,包括:GPU 使用率、GPU 显存使用率、GPU 显存用量等。您可以从该大盘中了解指定容器组的 GPU 监控信息。支持设置查询的时间段,并指定刷新方式(手动刷新、自动刷新)。
- 登录 容器服务控制台。
- 在左侧导航栏中选择 集群。
- 在集群列表页面,单击目标集群。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 GPU 监控 > 容器组 GPU 监控,即可查看监控大盘。
指标清单
GPU 监控大盘的指标清单如下表所示。
| 大盘分类 | 大盘名称 | 指标单位 | PromQL 语句 |
|---|---|---|---|
| 集群 GPU 监控 | 集群总 GPU 数 | Count | sum(kube_node_status_capacity{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"}) |
| 已分配 GPU 数 | Count | sum(kube_pod_container_resource_limits{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"}) | |
| 已使用 GPU 数 | Count | count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"}>0) | |
| 故障的 GPU 数 | Count | count(DCGM_FI_DEV_XID_ERRORS{cluster="$clusterId",job=~"dcgm"}>0) or on() vector(0) | |
| GPU 节点数 | Count | count(kube_node_status_capacity{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"}>0) | |
| GPU 故障节点数 | Count | count(count(DCGM_FI_DEV_XID_ERRORS{cluster="$clusterId",job=~"dcgm"}>0)by(nodename)) or on() vector(0) | |
| 8 GPU 卡可用节点 | Count | count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""})by(nodename) ==8) or on() vector(0) | |
| 碎片节点数 | Count | (count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""})by(nodename) ==1 and (count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"})by(nodename) >3)) or on() vector(0) )+ (count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""})by(nodename) ==2 and (count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"})by(nodename) >3) ) or on() vector(0)) + (count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""}) by(nodename) ==1 and (count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"})by(nodename) ==2) ) or on() vector(0)) | |
| 集群 GPU 分配率 | % | sum(kube_pod_container_resource_requests{resource="nvidia_com_gpu",cluster="$clusterId",node!~"vci.*"})/sum(kube_node_status_capacity{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"})by(cluster)*100 | |
| 集群 GPU 利用率 | % | count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"}>0)by(cluster)/sum(kube_pod_container_resource_requests{resource="nvidia_com_gpu",cluster="$clusterId",node!~"vci.*"})*100 | |
| 集群 GPU 故障率 | % | 100*count(DCGM_FI_DEV_XID_ERRORS{cluster="$clusterId",job=~"dcgm"}>0)by(cluster)/sum(kube_node_status_capacity{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"}) or on() vector(0) | |
| GPU 节点故障率 | % | 100*count(count(DCGM_FI_DEV_XID_ERRORS{cluster="$clusterId",job=~"dcgm"}>0)by(nodename))/count(kube_node_status_capacity{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"}>0) or on() vector(0) | |
| 节点空闲率 | % | (count(kube_node_status_capacity{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"}>0)-count(sum(kube_pod_container_resource_requests{resource="nvidia_com_gpu",cluster="$clusterId",node!~"vci.*"}) by(node) >0))/count(kube_node_status_capacity{resource="nvidia_com_gpu",cluster="$clusterId",node !~"vci.*"}>0) *100 | |
| 节点碎片率 | % | ((count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""}) by(nodename) ==1 and (count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"})by(nodename) >3)) or on() vector(0) )+(count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""}) by(nodename) ==2 and (count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"})by(nodename) >3) ) or on() vector(0)) + (count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""}) by(nodename) ==1 and (count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"})by(nodename) ==2) ) or on() vector(0))/count(kube_node_status_capacity{resource="nvidia_com_gpu",cluster="$clusterId",node !~"vci.*"}>0)*100 ) or on() vector(0) | |
| GPU 实例监控 | GPU 利用率 | % | DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} |
| GPU 使用显存 | Byte | DCGM_FI_DEV_FB_USED{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} | |
| Pod GPU 显存使用率 | % | 100*DCGM_FI_DEV_FB_USED{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"}、(DCGM_FI_DEV_FB_USED{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"}+DCGM_FI_DEV_FB_FREE{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"}) | |
| GPU 温度 | ℃ | DCGM_FI_DEV_GPU_TEMP{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} | |
| GPU 功耗 | W | DCGM_FI_DEV_POWER_USAGE{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} | |
| GPU 时钟频率 | Hz | DCGM_FI_DEV_SM_CLOCK{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} | |
| GPU 解码器利用率 | % | DCGM_FI_DEV_DEC_UTIL{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} | |
| GPU 编码器利用率 | % | DCGM_FI_DEV_ENC_UTIL{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} | |
| GPU Xid (By instance) | Count | sum(DCGM_CUSTOM_XID_ERRORS_TOTAL_COUNTER{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"})by(gpu_id) | |
| GPU Xid (By xid) | % | sum(DCGM_CUSTOM_XID_ERRORS_TOTAL_COUNTER{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"})by(xid) | |
| 容器组 GPU 监控 | GPU 使用率 | % | DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",namespace="$namespace",pod="$pod",job=~"dcgm|dcgm-vci"} |
| GPU 显存使用率 | % | (DCGM_FI_DEV_FB_USED{cluster="$clusterId",namespace="$namespace",pod="$pod",job=~"dcgm|dcgm-vci"}/(DCGM_FI_DEV_FB_USED{cluster="$clusterId",namespace="$namespace",pod="$pod",job=~"dcgm|dcgm-vci"} + DCGM_FI_DEV_FB_FREE{cluster="$clusterId",namespace="$namespace",pod="$pod",job=~"dcgm|dcgm-vci"}))*100 | |
| GPU 显存用量 | Byte | DCGM_FI_DEV_FB_USED{cluster="$clusterId",namespace="$namespace",pod="$pod",job=~"dcgm|dcgm-vci"} | |
| GPU 显存未使用量 | Byte | DCGM_FI_DEV_FB_FREE{cluster="$clusterId",namespace="$namespace",pod="$pod",job=~"dcgm|dcgm-vci"} | |
| 共享 GPU 显存用量 | Byte | nvml_container_mem_usage{cluster="$clusterId",namespace="$namespace",pod="$pod"} | |
| 共享 GPU 显存未使用量 | Byte | nvml_container_mem_request{cluster="$clusterId",namespace="$namespace",pod="$pod"}-nvml_container_mem_usage{cluster="$clusterId",namespace="$namespace",pod="$pod"} | |
| 共享 GPU 显存使用率 | % | nvml_container_mem_utilization{cluster="$clusterId",namespace="$namespace",pod="$pod"} |
说明
如果您需要在托管 Prometheus 中的 Explore 功能或告警中心使用上述 PromQL 语句查看具体的指标或配置告警,请修改或删除语句中关于集群、节点、容器组的变量。例如:将 cluster=~"$Cluster"参数中的$Cluster变量修改为具体的集群 ID ,或直接删除该参数。
查看指标
您可以使用托管 Prometheus 的 Explore 功能来快速查询和展示指标数据。详情请参见 指标查询。
配置告警
您可以在托管 Prometheus 的告警中心配置集群相关告警。详情请参见 创建告警规则。