使用文档
最近更新时间:2024.01.19 17:27:24
首次发布时间:2021.09.01 16:30:36
机器学习平台提供了命令行工具供用户在任何网络通畅的机器上管理平台上的训练任务。
sh -c "$(curl -fsSL https://ml-platform-public-examples-cn-beijing.tos-cn-beijing.volces.com/cli-binary/install.sh)" && export PATH=$HOME/.volc/bin:$PATH
安装完成后, 请确保 $HOME/.volc/bin 这个目录在你的 $PATH 下。
configure
在使用命令行工具之前,必须配置包含 AK、SK、Region 在内的用户身份凭证。
用户可以使用 volc configure 交互式地进行相关参数的配置。
- region 列表如下:
- 华北2(北京):cn-beijing。
- 华东2(上海):cn-shanghai。
- 华南1(广州):cn-guangzhou。
volc configure volc access key [********4M2Q]: █ volc secret access key [********TQ==]:█ volc region [cn-beijing]:█
设置完成后请检查 $HOME/.volc/config 和 $HOME/.volc/credentials 两个文件是否存在。
# 查看 config 文件 ls $HOME/.volc/ config credentials
version
查看当前命令行工具的版本。
upgrade
更新命令行工具。
help
查看命令行工具的帮助信息,包含了各命令的使用方法。
ml_task
针对机器学习平台【自定义训练】模块的命令集合。
submit
通过本地代码发起自定义训练任务。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --conf | -c | 训练任务的配置文件。 | 是 |
| --task_name | -n | 训练任务的名称。 | 否 |
| --description | -d | 训练任务的描述。 | 否 |
| --user_code_path | --cp | 用户的代码路径,配置该参数后将覆盖 conf 中的值。如是目录且以 '/' 结尾,则将该目录下所有内容上传至远端目录,如是目录且不以 '/' 结尾,则将该目录及该目录下所有内容上传到远端目录 | 否 |
| --entrypoint | -e | 指定训练任务的入口命令, 如含有空格需使用引号。 配置该参数后, conf 文件中的 Entrypoint 配置值将会被覆盖。 | 否 |
| --args | -a | 指定训练任务的命令参数(args), 如含有空格请使用引号。 支持一次使用多个,多个值最后会拼成一个,用空格分隔。配置该参数后, conf 文件中的 Args 配置值将会被覆盖。 | 否 |
| --image | -i | 镜像URL,配置该参数后将覆盖 conf 中的值。在镜像中心对应的详情页找到指定的镜像版本,即可获取镜像URL。 | 否 |
| --resource_group_id | -g | 资源组 ID,配置该参数后将覆盖 conf 中的 ResourceGroupID。在控制台的资源组模块列表页面上,将鼠标悬浮到指定资源组的名称上即可查看资源组 ID,后续该配置值将被弃用。 | 否 |
| --resource_queue_id | -q | 资源队列 ID,配置该参数后将覆盖 conf 中的 ResourceQueueID。在控制台的队列模块列表页面上,将鼠标悬浮到指定队列的名称上即可查看队列 ID。 | 否 |
| --resource_queue_name | -queue_name | 资源队列名称,配置该参数后将覆盖命令行参数 --resource_queue_id。在控制台的队列模块列表页面上,可以查看指定队列的名称。 | 否 |
| --framework | -f | 训练框架,支持的选项包含 TensorFlowPS、 PyTorchDDP、MXNet、BytePS、MPI、Custom。配置该参数后将覆盖 conf 中的值。 | 否 |
| --local_diff | 是否只上传增量的代码文件来加速提交任务的过程,支持的选项包含 on、off,不配置该参数是默认为 on。 | 否 | |
| --copy-links | -L | 上传代码碰到软链接时, 将上传实际的文件内容而不是软链接。 如软链接指向目录, 则指向的整个目录会上传。 该选项默认不打开, 如有需求或者上传的代码中有软链接指向绝对路径的情况, 则可以使用该选项。 | 否 |
| --links | 上传代码碰到软链接时, 会直接将软链接上传。 需要确保容器内存在相同的链接关系, 否则会报错。 该选项默认不打开, 如有需求则可以使用该选项。 | 否 | |
| --access_type | 指定训练任务的可见范围,支持的选项包含 Public、 Queue、Private,分别表示主账号内可见、队列内成员可见、仅创建人可见。仅可使用 Queue 选项搭配 --access_users 参数或 AccessUsers 字段来设置队列内、指定子账号可见。 | 否 | |
| --access_users | 指定训练任务的可见用户。 用户未设置可见范围或可见用户,默认可见范围为队列内成员可见。 | 否 | |
| --preemptible | 指定此任务可抢占。可抢占任务能够使用各队列出借的空闲资源,一定程度上减少排队时间。当各队列的不可抢占任务出现排队时,可抢占任务有可能被系统停止,并被复制后重新排队。(默认值:false) | 否 | |
| --priority | 指定训练任务的优先级。优先级的完整范围为 1~9(数值越大,优先级越高),提交任务时仅支持选择部分档位,其余档位供队列管理员使用。提交后平台将尝试按照优先级从高到低、创建时间从早到晚的顺序进行调度,最终结合实际的资源情况决定调度顺序(保证在资源充足、相同优先级下,先提交的任务先调度)。任务排队期间允许队列管理员调整优先级。若未指定,则使用队列中配置的默认优先级。 | 否 | |
| --output | 支持以某种格式展示指令的输出结果,目前仅支持 Json。 | 否 | |
| --set | 用于覆盖配置文件中的某个参数的值,但其优先级低于上述的其它 flag。支持以 --set Entrypoint="sleep 5s" --set Priority=4 的形式同时指定多个参数的值。 | 否 |
- conf 文件样例(可通过 get 获取线上已经存在的task config)
- SidecarMemoryRatio:挂载 TOS 数据盘时文件缓存服务能够使用的内存比例。
- 挂载的 TOS 存储桶的数据规模以及读写的并发量越大,该比例就需要配置的越大。
- conf 文件中不填写该参数时,系统将根据当前选择的实例规格及挂载的 TOS 数量自动分配内存,分配的内存大小(GiB) =
(0.15 * CPU 的核数 + 3) * TOS 数据盘的数量。 - 若填写该参数,建议 SidecarMemoryRatio * 实例规格的内存 不少于
4GiB,否则容易挂载 TOS 数据盘失败或导致用户容器异常。
- NasAddr:挂载 NAS 数据盘时需要填写 NAS 文件系统的挂载点地址,该地址在文件存储 NAS 的控制台查看。
- ImageUrl:镜像地址,可在机器学习平台【镜像中心】中选择待使用的镜像并进入详情页,在【版本列表】中复制获得。
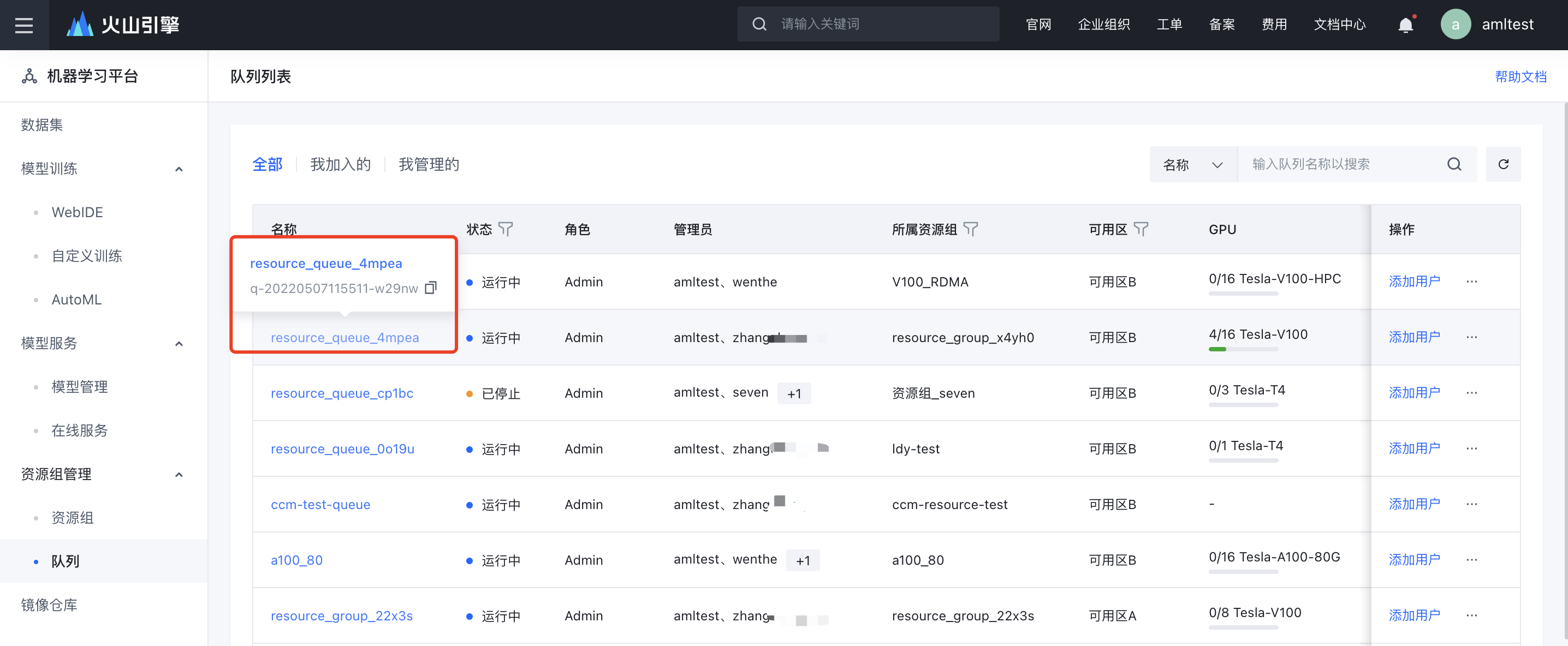
- ResourceQueueID:提交任务到指定的队列上,获取队列 ID 的方式如下图所示。
- Flavor:提交任务需要的实例规格,详见实例规格及定价。
- SidecarMemoryRatio:挂载 TOS 数据盘时文件缓存服务能够使用的内存比例。
# 任务名称 TaskName: "tf_random_mono_repo_ecs" # 任务描述 Description: "" # 入口命令 Entrypoint: echo 'hello' & echo "world" && sleep 1d # 入口命令的参数,平台将其拼接在入口命令后 Args: "" # 标签 Tags: [tag1,tag2] # 本地的代码路径,如是目录且以 '/' 结尾,则将该目录下的所有内容上传到 RemoteMountCodePath,如是目录且不以 '/' 结尾,则将该目录及该目录下 # 所有内容上传到 RemoteMountCodePath. UserCodePath: ./project_xxx/src # 容器中的代码挂载路径 RemoteMountCodePath: "/xxx_path/project_xxx/src/" # 环境变量 Envs: - Name: "env1" Value: "value1" - Name: "env2" Value: "value2" IsPrivate: false # 是否将某个环境变量设置为在详情页中仅创建人可见 # 镜像 URL 地址 ImageUrl: "replace with your ImageUrl" # 当 ImageUrl 为私有仓库的镜像时需要填写仓库的用户名和密钥才能拉取镜像 ImageCredential: RegistryUsername: "replace with your RegistryUsername" RegistryToken: "replace with your RegistryToken" # 所属资源组的 ID,为空时默认使用公共资源组,不为空时修改成用户的专有资源组的 ID. 最新版本的 volc 将逐步废弃该字段的支持 # ResourceGroupID: "replace with your ResourceGroupID" # 队列 ID,为空时使用公共队列 ResourceQueueID: "replace with your ResourceQueueId" # 队列名称,优先级高于 ResourceQueueID ResourceQueueName: "replace with your ResourceQueueName" # 训练框架,支持 TensorFlowPS / PyTorchDDP / MPI / BytePS / Custom Framework: "Custom" # 实例配置,包含角色名称(RoleName)、角色数量(RoleReplicas)以及具体的实例规格(Flavor) TaskRoleSpecs: - RoleName: "worker" RoleReplicas: 1 Flavor: "ml.c1e.xlarge" GpuRate: 0.1 # 非必填,当需要切分 GPU 时请填写切分比例,取值范围为 (0, 1]。不同型号的 GPU 的可切分数不同,比如 ml.g1v.2xlarge(Tesla-V100) 可以切分成 8 份,当 GpuRate 填写 0.1 时,会向上取整为 1/8 卡。 # 最长运行时间 ActiveDeadlineSeconds: 432000 # 实例保留时长 DelayExitTimeSeconds: 0 # 可见范围,支持 Public / Queue / Private AccessType: "Public" # 可见用户 AccessUsers: - "xxx" Preemptible: false # 非必填,配置该任务是否为可抢占任务,默认不可抢占 Priority: 4 # 非必填,配置任务优先级(数字越大优先级越高),仅支持配置部分档位(默认为2、4、6)。不配置时以队列中自定义任务的默认优先级为准 # 自动重试 RetryOptions: EnableRetry: false # 是否开启自动重试,默认关闭 MaxRetryTimes: 5 # 最大重试次数 IntervalSeconds: 120 # 重试间隔 = 新任务提交的时刻 - 上个任务终止的时刻 PolicySets: # 自动重试的触发条件,支持 Failed(任务失败)、InstanceReclaimed(闲时资源回收) - "Failed" # 是否开启 TensorBoard EnableTensorBoard: true # 开启 TensorBoard 后填写,将日志写入到 NAS 或 vePFS 内,需开白 TensorBoardStorage: Type: "Nas/Vepfs" # 必填,TensorBoard 日志写入存储实例类型,可填写 Nas 或 Vepfs NasId: "replace with your NAS Id" # NAS 实例 Id,当 Type 为 Nas 时填写,与 NasAddr 至少选填一个 NasAddr: "replace with your NAS Addr" # NAS 实例挂载点地址,当 Type 为 Nas 时填写,与 NasId 至少选填一个 VepfsId: "replace with your VepfsId" # type为Vepfs时:若在平台挂载了两个Vepfs实例,则需要指定对应VePFS实例ID;只有一个实例时,可以为空 SubPath: "replace with NAS sub path" # 必填,TensorBoard 日志写入的存储实例子目录,当 Type 为 vePFS 时,需要拥有该子目录的挂载权限 # 挂载数据盘至训练容器中 SidecarMemoryRatio: "replace with your ratio" # TOS 数据盘的缓存服务所需的内存比例 Storages: - Type: "Tos" # 挂载 TOS 数据盘 MountPath: "replace with your path" # 容器中的挂载目录 Bucket: "replace with your bucket" # 待挂载的 TOS Bucket Prefix: "replace with your prefix" # 待挂载的 TOS Bucket 下的目录路径 MetaCacheCapacity: "replace with cache number" # 缓存TOS文件元数据的数量, 缓存量越大性能越好,但有额外内存消耗 MetaCacheExpiryMinutes: "replace with cache expired time" # 缓存元数据过期时间(min),过期后会重新缓存,若不刷新可设为-1 FsName: "replace with CloudFS instance name" # 用于挂载 TOS 和缓存加速的 CloudFS 实例名称,不配置该字段时平台将从用户的 CloudFS 实例中自动选择一个 - Type: "Vepfs" # 挂载 vePFS 数据盘 VepfsId: "replace with your VepfsId" # 若在平台挂载了两个Vepfs实例,则需要指定对应VePFS实例ID;只有一个实例时,可以为空 MountPath: "replace with your path" # 容器中的挂载目录 SubPath: "replace with vePFS sub path" # 拥有挂载权限的 vePFS 子目录,挂载 vePFS 根目录时可忽略 ReadOnly: true # 以只读方式挂拥有挂载权限的 vePFS 子目录,以读写方式挂载时可忽略 - Type: "Nas" # 挂载 NAS 数据盘 MountPath: "replace with your path" # 容器中的挂载目录 NasId: "replace with your Nas Id" # NAS 实例 Id,与 NasAddr 至少选填一个 NasAddr: "replace with your NAS address" # NAS 实例的挂载点地址,与 NasId 至少选填一个 PrivateNetwork: # 非必填,默认使用全局配置中设置的私有网络 VpcId: "replace with your vpc id" # 指定的私有网络 SubnetId: "replace with your subnet id" # 指定私有网络中的一个子网 SecurityGroupIds: # 绑定的安全组 - "replace with your security group id"
--entrypoint的用法:
--entrypoint=./start.sh --entrypoint="python main.py" --entrypoint='python main.py'
--args的用法:(以下四种形式效果相同)
--args=--aaa=1 --args=--bbb=2 --args=--ccc=3 --args="--aaa=1 --bbb=2 --ccc=3" --args='--aaa=1 --bbb=2 --ccc=3' --args='--aaa=1 --bbb=2' --args=--ccc=3
--copy-links用法详解:- --copy-links一般用于文件上传场景中,如代码上传、模型上传,默认不开启。
- 当开启此参数时,将上传软链接对应的实际文件,而不是软链接文件。
- 以下两种情况建议开启:
- 软链接使用了绝对路径路径。
- 软链接指向的文件在待上传的目录之外。
--links用法详解:- --links一般用于文件上传场景中,如代码上传,默认不开启。
- 当开启此参数时,将直接上传软链接。
- 以下情况建议开启:待上传的目录中存在指向 code_path 之外的文件,且链接的文件会在容器中存在(如链接指向 TOS 挂载路径内的文件)。
upload
训练代码可以在创建任务时上传,也支持通过 upload 命令提前上传训练代码,然后创建任务时指定该代码时将不会重复上传从而加速创建任务的速度。
| 参数 | 说明 | 必填 |
|---|---|---|
| --local_code_path | 用户的代码路径。 | 是 |
| --tos_end_point | TOS 的访问域名。目前 TOS 支持的域名列表详见TOS-地域和访问域名。 | 否 |
| --region | 地域。支持 cn-beijing、cn-shanghai、cn-guangzhou。 | 是 |
| --timeout | 上传的超时时间(单位:秒)。 | 否 |
| --local_diff | 是否只上传增量的代码文件来加速提交任务的过程,支持的选项包含 on、off,不配置该参数是默认为 on。 | 否 |
| --copy-links | 上传代码碰到软链接时, 将上传实际的文件内容而不是软链接。 如软链接指向目录, 则指向的整个目录会上传。 该选项默认不打开, 如有需求或者上传的代码中有软链接指向绝对路径的情况, 则可以使用该选项。 | 否 |
| --links | 上传代码碰到软链接时, 会直接将软链接上传。 需要确保容器内存在相同的链接关系, 否则会报错。 该选项默认不打开, 如有需求则可以使用该选项。 | 否 |
list
获取训练任务的列表,默认列举排队中、部署中、运行中、停止中的任务。在得到任务列表的同时会展示具体的快捷键说明,使用快捷键可完成相应的操作。
- 快捷键:
- 【回车】:查看详情。
- 【j / k】:上下选择。
- 【q】:退出到上一层。
- 【e】:导出当前任务配置。
- 【r】:刷新任务/任务实例。
- 【d】:下载任务代码。
- 任务状态:
- Initialized:创建中。
- Queue:排队中。
- Staging:部署中。
- Running:运行中。
- Killing:停止中。
- Success:完成。
- Failed:失败。
- Killed:已停止。
- Exception:异常。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --status | -s | 通过状态筛选特定的任务列表,多个状态用 , 分割。 | 否 |
| --name | -n | 通过任务名称 ID 筛选特定的任务列表。 | 否 |
| --profile | -p | 用户凭证配置,通过 cat $HOME/.volc/credentials 查看当前配置的凭证列表。 | 否 |
| --output | 指定输出数据展示格式,当前仅支持 json。使用该参数后,输出不再提供交互式方式。 | 否 | |
| --format | 指定需要输出的字段列表。格式为 --format=FieldName[=outputFieldName],可以用 --format=FieldName=outputFieldName 来指定输出字段名字,也可以通过 --format=FieldName 使用默认的 FieldName 作为输出字段。 | 否 | |
| --helpformat | 列出支持的字段列表。 | 否 |
get
查看训练任务详情。
| 参数 | 说明 | 必填 |
|---|---|---|
| --id | 训练任务的 ID,可通过 volc ml_task list 指令查看,如 t-20211216120106-vx7d4。 | 是 |
| --profile | 用户凭证配置,通过 cat $HOME/.volc/credentials 查看当前配置的凭证列表。 | 否 |
| --output | 指定输出数据展示格式,当前仅支持 json。使用该参数后,输出不再提供交互式方式。 | 否 |
| --format | 指定需要输出的字段列表。格式为 --format=FieldName[=outputFieldName],可以用 --format=FieldName=outputFieldName 来指定输出字段名字,也可以通过 --format=FieldName 使用默认的 FieldName 作为输出字段。 | 否 |
| --helpformat | 列出支持的字段列表。 | 否 |
cancel
取消已提交的训练任务。
| 参数 | 说明 | 必填 |
|---|---|---|
| --id | 训练任务的 ID,可通过 volc ml_task list 指令查看,如 t-20211216120106-vx7d4。 | 是 |
logs
获取训练任务实例的日志。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --task | -t | 训练任务的 ID,可通过 volc ml_task list 指令查看,如 t-20211216120106-vx7d4。 | 是 |
| --instance | -i | 训练任务下某个实例的 ID,可通过 volc ml_task list 指令查看,如 worker_0。 | 是 |
| --content | -c | 检索关键词,支持 Lucene 语法,如 --content error 将返回包含了 error 字段的日志条目。 | 否 |
| --reverse | -r | 是否以倒序的方式查看日志。默认不开启。 | 否 |
| --start-time | 获取该时间之后的日志,格式为yyyy-MM-dd HH:mm:ss,例如2006-01-02 15:04:05。 | 否 | |
| --end-time | 获取该时间之前的日志,格式为yyyy-MM-dd HH:mm:ss,例如2006-01-02 15:04:05。 | 否 | |
| --lines | -l | 获取的日志行数,默认为 500。 | 否 |
| -f | 持续地滚动更新日志,仅支持正在运行的任务。开启-f 参数时检索关键词不支持 Lucene 语法。 | 否 | |
| --timestamp | -ts | 显示日志的时间戳,暂仅在开启-f 参数时有效。 | 否 |
| --profile | -p | 用户凭证配置,通过 cat $HOME/.volc/credentials 查看当前配置的凭证列表。 | 否 |
sbatch
sbatch 子命令支持提交单节点和多节点 slurm 任务。
单节点 slurm 任务:
volc ml_task sbatch --nodes 1 --partition q-20220110153047-xxxx a.sh
任务脚本在单个节点上运行。
多节点 slurm 任务:
volc ml_task sbatch --nodes 2 --partition q-20220110153047-xxxx a.sh
当 nodes > 1时,会创建一个有 1 个 master 和 nodes个 worker 的 slurm 集群,并在 master 节点使用 sbatch 命令提交任务脚本。
当前支持的参数列表如下:
| 参数 | 缩写 | 别名 | 说明 | 是否必须提供 |
|---|---|---|---|---|
| --nodes | 无 | - | 指定提交多少个节点的任务, 支持通过环境变量 SLURM_NNODES 设置 | 是, 可通过命令行参数, 环境变量或者 #SBATCH 提供, 下同 |
| --ntasks-per-node | 无 | - | 每个节点拉起多少个 tasks, 同时影响资源分配。 支持通过环境变量 SLURM_NTASKS_PER_NDOE 设置 | 否 |
| --partition | -q | --resource_queue_id,--resource_queue_name | 指定任务至指定的 partition/队列(机器学习平台概念), 支持通过 SBATCH_PARTITION 环境变量设置 | 是 |
| --gres | 无 | - | 通用资源需求申明, 目前仅支持表达 GPU 资源, 如 --gres=gpu:1。 GPU 资源申明详见下述的 --gpus。支持通过 SBATCH_GRES 环境变量设置 | 否 |
| --gpus | 无 | - | GPU 资源需求申明, 支持 [GPUType:]GPU个数, 如 --gpus=1,--gpus=Tesla-T4:1,支持通过环境变量 SBATCH_GPUS 设置。当前支持的 GPUType 为: Tesla-V4,Tesla-V100,Tesla-V100-HPC | 否 |
| --job-name | -J | --task_name | 作业名字. 支持通过环境变量 SBATCH_JOB_NAME 设置 | 否 |
| --image | -i | - | 机器学习平台专有的配置, 用户可指定当前任务运行在特定的镜像下面。当前默认运行在机器学习平台一个预置镜像内。 | 否 |
| --description | -d | - | 任务描述 | 否 |
| --user_code_path | 无 | --cp | 除提交的主脚本外, 可额外指定一个代码目录, 该目录下所有的文件和子目录均会上传. 当前需确保主脚本在代码目录下 | 否 |
| --conf | -c | - | 机器学习平台专有配置, 类似于 submit 提供的额外配置参数. 有进阶配置需求可配置 conf 文件和指定该参数,正常情况下无需关注。 | 否 |
| --copy-links | -L | - | 上传代码碰到软链接时, 将上传实际的文件内容而不是软链接。 如软链接指向目录, 则指向的整个目录会上传。 该选项默认不打开, 如有需求或者上传的代码中有软链接指向绝对路径的情况, 则可以使用该选项。 | 否 |
| --links | - | 上传代码碰到软链接时, 会直接将软链接上传。 需要确保容器内存在相同的链接关系, 否则会报错。 该选项默认不打开, 如有需求则可以使用该选项。 | 否 |
另外, sbatch 子命令也支持涉及到资源需求的 #SBATCH directive。假设 hello.sh 内容如下:
#SBATCH支持--nodes、--partition等所有 slurm 官方参数,详见slurm-sbatch。
#!/usr/bin/env bash #SBATCH --nodes 1 #SBATCH --gres=gpu:1 #SBATCH --partition q-20220110153047-xxxx echo "Hello Slurm on ML Platform"
则可以直接进行提交,不需要指定额外的参数。
volc ml_task sbatch hello.sh
export
导出指定任务的配置文件及代码,若只填写任务 ID 默认导出任务配置。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --task | -t | 训练任务的 ID,可通过 volc ml_task list 指令查看,如 t-20211216120106-vx7d4。 | 是 |
| --config | 导出任务配置到当前路径。 | 否 | |
| --code | 下载任务代码到当前路径。 | 否 |
instance
训练任务实例相关命令。
list
- 快捷键:
- 【回车】:查看详情。
- 【j / k】:上下选择。
- 【q】:退出到上一层。
- 【r】:刷新任务实例。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | -i | 训练任务的 ID,可通过 volc ml_task list 指令查看,如 t-20211216120106-vx7d4。 | 是 |
| --profile | -p | 用户凭证配置,通过 cat $HOME/.volc/credentials 查看当前配置的凭证列表。 | 否 |
| --output | 指定输出数据展示格式,当前仅支持 json。使用该参数后,输出不再提供交互式方式。 | 否 | |
| --format | 指定需要输出的字段列表。格式为 --format=FieldName[=outputFieldName],可以用 --format=FieldName=outputFieldName 来指定输出字段名字,也可以通过 --format=FieldName 使用默认的 FieldName 作为输出字段。 | 否 | |
| --helpformat | 列出支持的字段列表。 | 否 |
ml_model
针对机器学习平台【模型仓库】模块的命令集合。
register / create
创建一个新的模型,或者注册一个新的模型版本。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 模型ID。不为空时,则在对应的模型ID下注册一个新的模型版本。可通过 volc ml_model list 指令查看,如 m-20220519204748-qnfvj。 | 否 |
| --name | -n | 模型名称。当--id参数指定时,该参数被忽略。 | 否 |
| --description | -d | 模型描述。 | 否 |
| --version-description | --vd | 模型版本的描述。 | 否 |
| --format | --fm | 模型格式。可选值:SavedModel, GraphDef, TorchScript, TensorRT, ONNX, CaffeModel, NetDef, MXNetParams, Scikit_Learn, XGBoost, LightGBM, MATX, Custom。 | 是 |
| --framework | --fw | 模型框架,格式:<框架名称>:<框架版本号>。示例:TensorFlow:2.0。框架名可选值:TensorFlow, PyTorch, TensorRT, ONNX, Caffe, Caffe2, MXNet, Scikit_Learn, XGBoost, LightGBM, MATX, Custom。 | 是 |
| --path | 无 | 模型存储路径,可以是本地目录或者TOS上的一个路径。对于TOS路径,格式为:tos://bucket/prefix/。 | 是 |
| --source | -s | 模型来源。可选值:Local,TOS, AutoML, Perf。 | 是 |
| --category | -c | 模型类别,可选值:TextClassification, TabularClassification, TabularRegression, ImageClassification。 | 否 |
| --dataset | --ds | 训练模型所使用的数据集ID。在控制台的数据集模块列表页面上,将鼠标悬浮到指定数据集的名称上即可查看数据集 ID。 | 否 |
| --base-version-id | --bv | 转换生成的模型所基于的原始模型ID。当--source不是Perf时,该参数会被忽略。 | 否 |
| --source-id | --sid | 模型的来源ID。比如产生模型的训练任务的ID,或者模型转换任务的ID。 | 否 |
| --tags | -t | 模型标签列表。以逗号分隔,每个标签格式:<标签名>:<标签值>。 | 否 |
| --profile | -p | 用户凭证配置,通过 cat $HOME/.volc/credentials 查看当前配置的凭证列表。 | 否 |
| --copy-links | -L | 上传代码碰到软链接时, 将上传实际的文件内容而不是软链接。 如软链接指向目录, 则指向的整个目录会上传。 该选项默认不打开, 如有需求或者上传的代码中有软链接指向绝对路径的情况, 则可以使用该选项。 | 否 |
Tensor配置文件,示例:
Inputs: - TensorName: "Conv1_input" DType: "INT32" Shape: - -1 - 28 - 28 Outputs: - TensorName: "Softmax" DType: "INT32" Shape: - -1 - 10
使用CLI将本地模型包创建一个新的模型,示例:
volc ml_model create --name="demo-model" --description="demo model" --version-description="local upload" --format="SavedModel" --framework="TensorFlow:2.0" --path="./tmp" --source="Local" --tensor-config=""./docs/examples/model_tensor_config_example.yaml""
使用CLI将TOS存储的模型包注册为一个新的模型版本,示例:
volc ml_model register --id=m-20220124172610-48psg --version-description="tos register" --format="SavedModel" --framework="TensorFlow:2.0" --path="tos://model-beijing/tf-model/1/" --source="TOS" --tensor-config="./docs/examples/model_tensor_config_example.yaml" --tags="hd:T4,precision:float"
list
展示模型或模型版本列表。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 按照模型ID筛选模型。 | 否 |
| --name | 无 | 按照模型名称筛选模型。 | 否 |
| --offset | -o | 模型列表的起始偏移位置。默认为0。 | 否 |
| --limit | -l | 模型列表中每页的模型数量。默认为10。 | 否 |
| --sort-by | 无 | 按照哪个字段排序。可选值:ModelName, CreateTime。默认为CreateTime。 | 否 |
| --sort-order | 无 | 排序顺序。可选值:Ascend, Descend。默认为Descend。 | 否 |
| --profile | -p | 用户凭证配置,通过 cat $HOME/.volc/credentials 查看当前配置的凭证列表。 | 否 |
使用CLI获取模型列表,示例:
volc ml_model list
show / get
获取模型或模型版本信息。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 模型ID。可通过 volc ml_model list 指令查看,如 m-20220519204748-qnfvj。 | 是 |
| --version | -v | 模型版本号。 | 否 |
| --profile | -p | 用户凭证配置,通过 cat $HOME/.volc/credentials 查看当前配置的凭证列表。 | 否 |
使用CLI获取模型详情,示例:
volc ml_model show --id=m-20220119194754-rrdwf
使用CLI获取模型版本详情,示例:
volc ml_model show --id=m-20220119194754-rrdwf --version="V1.0"
update
更新模型或模型版本。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 模型ID。可通过 volc ml_model list 指令查看,如 m-20220519204748-qnfvj。 | 是 |
| --version | -v | 模型版本号。 | 否 |
| --name | -n | 修改后的模型名字。 如果指定了--version参数,该字段被忽略。 | 否 |
| --description | -d | 修改后的模型或者模型版本的描述。 如果指定了--version参数,该字段代表模型版本的描述,否则代表模型的描述。 | 否 |
| --tensor-config | --tc | 修改后的模型Tensor配置文件。yaml格式。 | 否 |
| --profile | -p | 用户凭证配置,通过 cat $HOME/.volc/credentials 查看当前配置的凭证列表。 | 否 |
使用CLI更新模型描述,示例:
volc ml_model update --id="m-20211208174903-d2snv" --v="V1.0" --description="test cli update"
使用CLI更新模型Tensor配置,示例:
volc ml_model update --id=m-20220124172610-48psg --version="V1.0" --tensor-config="./docs/examples/model_tensor_config_example.yaml"
download
下载模型。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 模型ID。可通过 volc ml_model list 指令查看,如 m-20220519204748-qnfvj。 | 是 |
| --version | -v | 模型版本号。 | 是 |
| --path | -v | 下载模型保存到本地的路径。默认下载到当前目录。 | 否 |
| --profile | -p | 用户凭证配置,通过 cat $HOME/.volc/credentials 查看当前配置的凭证列表。 | 否 |
使用CLI下载模型,示例:
volc ml_model download --id=m-20220124172610-48psg --version="V2.0" --path="./tmp"
delete
删除模型或模型版本。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 模型ID。可通过 volc ml_model list 指令查看,如 m-20220519204748-qnfvj。 | 是 |
| --version | -v | 模型版本号。 | 否 |
| --profile | -p | 用户凭证配置,通过 cat $HOME/.volc/credentials 查看当前配置的凭证列表。 | 否 |
使用CLI删除模型版本,示例:
volc ml_model delete --id="m-20220124172610-48psg" --version="V3.0"
使用CLI删除模型,示例:
volc ml_model delete --id="m-20220124172610-48psg"
ml_service
针对机器学习平台【推理服务】模块的命令集合。
create
创建推理服务。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --conf | -c | 参数配置文件,配置文件参数优先级低于命令行参数。 | 是 |
| --name | -n | 推理服务名称。 | 否 |
| --description | -d | 推理服务描述。 | 否 |
| --model | 无 | 模型Id。 | 否 |
| --model-version | 无 | 模型版本。 | 否 |
| --image | -i | 镜像地址。 | 否 |
| --queue | -q | 队列Id。 | 否 |
| --flavor | -f | 实例规格。 | 否 |
| --replicas | -r | 实例数量。 | 否 |
配置文件示例:
# 推理服务名称 ServiceName: "test_service" # 推理服务描述 Description: "this is a description for test_service" # 镜像Url地址 ImageUrl: "replace with your ImageUrl" # 当 ImageUrl 为私有仓库的镜像时需要填写仓库的用户名和密钥才能拉取镜像 ImageCredential: RegistryUsername: "replace with your RegistryUsername" RegistryToken: "replace with your RegistryToken" # 模型id ModelID: "m-xxxxxxxx" # 模型版本 ModelVersion: "V1.0" # 服务的入口命令,预置的推理镜像有默认的入口命令 Command: "replace with your command" # 环境变量 Envs: - Name: "env1" Value: "value1" - Name: "env2" Value: "value2" # 端口配置,最多5个,ListenPort与ExposePort取值范围1-65535,type取值范围HTTP、RPC、Metrics、Others # 预置的推理镜像有默认的端口配置 Ports: - ListenPort: "2222" # 监听端口,取值范围1-65535 ExposePort: "2222" # 调用端口,取值范围1-65535 Type: "HTTP" # 端口用途,取值范围 HTTP、RPC、Metrics、Others - ListenPort: "2223" ExposePort: "2223" Type: "RPC" # 健康检查 ReadinessProbe: Enabled: true # 是否开启健康检查 true | false Command: "replace with your command" # 健康检查命令 InitialDelaySeconds: 120 # 首次检查等待时间 PeriodSeconds: 30 # 检查间隔 FailureThreshold: 3 # 最大失败次数 # 队列Id ResourceQueueID: "replace with your ResourceQueueID" # 计算规格 Flavor: "ml.c1ie.large" # 实例数 Replicas: 1 # 自动扩容 Autoscaler: Enable: true # 是否开启自动扩缩容 true or false,Crons和MetricsAutoscaler需二选一 Crons: # 定时自动扩缩容 - Schedule: "1 * * * *" # Cron语句,如:1 * * * *,代表每分钟执行1次 Target: 2 # 实例的目标数量 MetricsAutoscaler: # 指标自动扩缩容 Metrics: - Name: cpu # 指标名称,可选 cpu、memory、gpu TargetPercentage: 50 # 指标利用率 MinReplicas: 1 # 最小实例数 MaxReplicas: 2 # 最大实例数 # 共享文件系统的挂载配置,这部分配置与 ml_task submit 指令的 conf 中 Storages 完全相同 Storages: - Type: "Tos" MountPath: "replace with your path" Bucket: "replace with your bucket" Prefix: "replace with your prefix" MetaCacheCapacity: "replace with cache number" MetaCacheExpiryMsec: "replace with cache expired time" - Type: "Vepfs" VepfsId: "replace with your VepfsId" # 若在平台挂载了两个Vepfs实例,则需要指定对应VePFS实例ID;只有一个实例时,可以为空 MountPath: "replace with your path" SubPath: "replace with vePFS sub path" - Type: "Nas" MountPath: "replace with your path" NasId: "replace with your Nas Id" NasAddr: "replace with your NAS address" # 配置前,需先配置端口(Ports)字段,否则配置无效 NetWork: VpcId: vpc-xxxxxxxxxx # 私有网络Id(vpc-id) SubnetId: subnet-xxxxxxxxxx # 私有网络下子网Id(subnet-id) EnableEip: true # 是否开启公网访问 true or false EipId: eip-xxxxxxxxxx # 公网IP id
update
更新推理服务,若更新项包含健康检查、自动扩缩容、滚动更新和访问配置,须提交yaml配置文件。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 推理服务Id。 | 是 |
| --conf | -c | 参数配置文件,配置文件参数优先级低于命令行参数。 | 否 |
| --description | -d | 推理服务变更描述。 | 否 |
| --model | 无 | 模型Id。 | 否 |
| --model-version | 无 | 模型版本。 | 否 |
| --image | -i | 镜像地址。 | 否 |
| --flavor | -f | 实例规格。 | 否 |
更新服务配置文件样例:
- 更新服务配置文件支持的字段为创建服务配置文件的子集,下面为具体支持更新的字段。
# 变更描述 Description: "describe what you changed" # 镜像Url地址 ImageUrl: "replace with your ImageUrl" # 当 ImageUrl 为私有仓库的镜像时需要填写仓库的用户名和密钥才能拉取镜像 ImageCredential: RegistryUsername: "replace with your RegistryUsername" RegistryToken: "replace with your RegistryToken" # 模型id ModelID: "m-xxxxxxxx" # 模型版本 ModelVersion: "V1.0" # 入口命令 Command: "replace with your command" # 环境变量 Envs: - Name: "env1" Value: "value1" - Name: "env2" Value: "value2" # 端口配置 Ports: - ListenPort: "2222" # 监听端口,取值范围1-65535 ExposePort: "2222" # 调用端口,取值范围1-65535 Type: "HTTP" # 端口用途,取值范围 HTTP、RPC、Metrics、Others - ListenPort: "2223" ExposePort: "2223" Type: "RPC" # 健康检查 ReadinessProbe: Enabled: true # 是否开启健康检查 true | false Command: "your health check command" # 健康检查命令 InitialDelaySeconds: 120 # 首次检查等待时间 PeriodSeconds: 30 # 检查间隔 FailureThreshold: 3 # 最大失败次数 # 计算规格 Flavor: "ml.g1ie.large" # 共享文件系统挂载配置 Storages: - Type: "Tos" MountPath: "replace with your path" Bucket: "replace with your bucket" Prefix: "replace with your prefix" MetaCacheCapacity: "replace with cache number" MetaCacheExpiryMsec: "replace with cache expired time" - Type: "Vepfs" VepfsId: "replace with your VepfsId" # 若在平台挂载了两个Vepfs实例,则需要指定对应VePFS实例ID;只有一个实例时,可以为空 MountPath: "replace with your path" SubPath: "replace with vePFS sub path" - Type: "Nas" MountPath: "replace with your path" NasId: "replace with your Nas Id" NasAddr: "replace with your NAS address" # 访问配置 NetWork: VpcId: vpc-xxxxxxxxxx # 私有网络Id(vpc-id) SubnetId: subnet-xxxxxxxxxx # 私有网络下子网Id(subnet-id) EnableEip: true # 是否开启公网访问 true or false EipId: eip-xxxxxxxxxx # 公网IP id
list
列举所有的推理服务。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --status | 无 | 列举出状态为 status 的服务,status可选值为 Deploying, Running, Abnormal, Stopping, None。 | 否 |
| --name | -c | 筛选名字包含 name 的服务。 | 否 |
get
查看推理服务详细信息。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 推理服务Id。 | 是 |
delete
删除推理服务。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 推理服务Id。 | 是 |
| --delete-eip | -d | 是否删除该服务绑定的公网ip。 | 否 |
start
启动推理服务。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 推理服务Id。 | 是 |
stop
停止推理服务。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 推理服务Id。 | 是 |
rollback
将推理服务回滚至指定版本。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 推理服务Id。 | 是 |
| --version | v | 服务版本号,可先通过 list 命令列举服务,选中某个服务后按 v 键查询对应的变更记录,其中包含每条变更的版本号。 | 是 |
scale
推理服务扩缩容。
| 参数 | 缩写 | 说明 | 必填 |
|---|---|---|---|
| --id | 无 | 推理服务Id。 | 是 |
| --replicas | -r | 推理服务实例数量。 | 是 |
对于 Bash、Zsh 的 Shell 用户, 会自动安装 autocomplete 脚本。 Zsh 需要安装 oh-my-zsh。如发现自动提示不符合预期,可以参照如下方法重新安装。
Bash
mkdir autocomplete curl -o autocomplete/bash_autocomplete https://ml-platform-public-examples-cn-beijing.tos-cn-beijing.volces.com/autocomplete/bash_autocomplete sudo cp ./autocomplete/bash_autocomplete /etc/bash_completion.d/volc . /etc/bash_completion.d/volc
Zsh
mkdir autocomplete curl -o autocomplete/zsh_autocomplete https://ml-platform-public-examples-cn-beijing.tos-cn-beijing.volces.com/autocomplete/zsh_autocomplete # 方法一:在 .zshrc 文件中加入以下配置 PROG=volc _CLI_ZSH_AUTOCOMPLETE_HACK=1 source path/to/autocomplete/zsh_autocomplete(需要autocomplete绝对路径) # 方法二:安装 oh-my-zsh 插件 cp ./autocomplete/zsh_autocomplete $ZSH/custom/plugins/volc/volc.plugin.zsh # 编辑 .zshrc,在 plugins 配置添加 volc,如下: plugins=( git volc tmux zsh-autosuggestions zsh-syntax-highlighting )