GPU-部署基于DeepSpeed-Chat的行业大模型
最近更新时间:2023.12.07 17:10:25
首次发布时间:2023.10.17 11:07:04
本文以搭载了一张A100显卡的ecs.pni2.3xlarge为例,介绍如何在GPU云服务器上进行DeepSpeed-Chat模型的微调训练。
背景信息
DeepSpeed-Chat简介
DeepSpeed-Chat是微软新公布的用来训练类ChatGPT模型的一套代码,该套代码基于微软的大模型训练工具DeepSpeed,通过使用它可以非常简单高效地训练属于自己的ChatGPT。DeepSpeed-Chat具有以下特点:
- 完整的训练类ChatGPT的代码:包括预训练模型下载、数据下载、InstructGPT训练过程和测试。
- 多种规模的模型:模型参数从1.3B到66B,既适合新手学习也可用于商用部署。
- 高效的训练:通过使用最新技术,如ZeRO和LoRA等技术改善训练过程,让训练过程更高效。
- 推理API:提供易于使用的推理API,方便进行对话式的交互测试。
模型微调
模型微调是一种迁移学习技术,通过在预训练模型的基础上进行额外训练,使其适应特定任务或领域。这一过程包括选择预训练模型,准备目标任务的数据,调整模型结构,进行微调训练,以及评估和部署。微调的优点在于节省时间和资源,提高性能,适用于数据受限或计算资源有限的情况。
通过在特定领域的数据上进行微调,模型可以逐渐学习到特定领域的特征和模式,从而提高在该领域的性能和泛化能力。
软件要求
- CUDA:使GPU能够解决复杂计算问题的计算平台。本文以11.4.152为例。
- Python:编程语言,并提供机器学习库Numpy等。本文以3.8.10为例。
- DeepSpeed:大模型训练工具。本文以0.10.2为例。
- Tensorboard:机器学习实验可视化的工具。本文以2.14.0为例。
- Transformers:一种神经网络架构,用于语言建模、文本生成和机器翻译等任务。本文以4.32.1为例。
- Gradio:快速构建机器学习Web展示页面的开源Python库。本文以3.43.2为例。
使用说明
下载本文所需软件需要访问国外网站,建议您增加网络代理(例如FlexGW)以提高访问速度。您也可以将所需软件下载到本地,参考本地数据上传到GPU实例中。
步骤一:准备环境
创建GPU计算型实例
请参考通过向导购买实例创建一台符合以下条件的实例:
- 基础配置:
- 计算规格:ecs.pni2.3xlarge
- 镜像:Ubuntu 20.04 with GPU Driver。
该镜像已默认安装Tesla 470.129.06版本的GPU驱动,适配的CUDA版本为11.4,需自行安装。
- 存储:云盘容量在100 GiB以上。
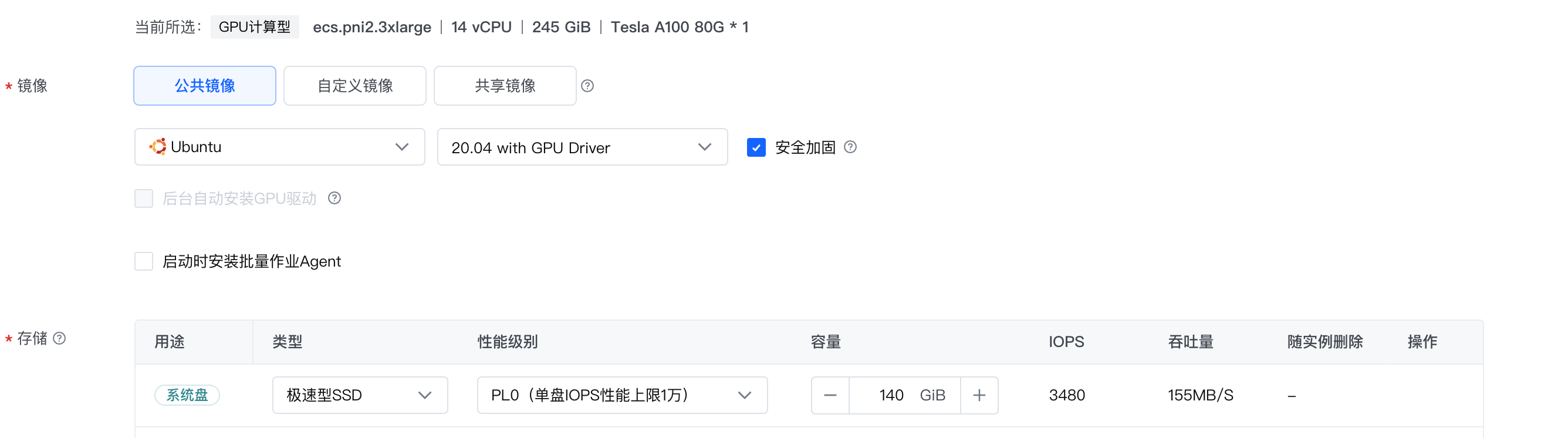
- 网络配置:勾选“分配弹性公网IP”。
- 基础配置:
创建成功后,在实例绑定的安全组中添加入方向规则:放行TCP 6006端口。具体操作请参见修改安全组访问规则。
安装并配置CUDA
登录实例。
依次执行以下命令,下载并安装CUDA 11.4。
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600 wget https://developer.download.nvidia.com/compute/cuda/11.4.4/local_installers/cuda-repo-ubuntu2004-11-4-local_11.4.4-470.82.01-1_amd64.deb sudo dpkg -i cuda-repo-ubuntu2004-11-4-local_11.4.4-470.82.01-1_amd64.deb sudo apt-key add /var/cuda-repo-ubuntu2004-11-4-local/7fa2af80.pub sudo apt-get update sudo apt-get -y install cuda-11.4执行以下命令,检查CUDA是否安装成功。
dpkg -l | grep cuda-11
回显如下,表示CUDA已成功安装。
配置CUDA环境变量。
- 执行
vim ~/.bashrc命令,打开配置文件。 - 按
i进入编辑模式。 - 在文件末尾添加如下参数。
export CUDA_HOME=/usr/local/cuda-11.4 export PATH=$PATH:$CUDA_HOME/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CUDA_HOME/lib64 - 按
esc退出编辑模式,输入:wq并按Enter键,保存并退出文件。 - 执行
source ~/.bashrc命令,使配置文件生效。
- 执行
执行以下命令,查看CUDA。
nvcc -V
回显如下,表示CUDA安装成功。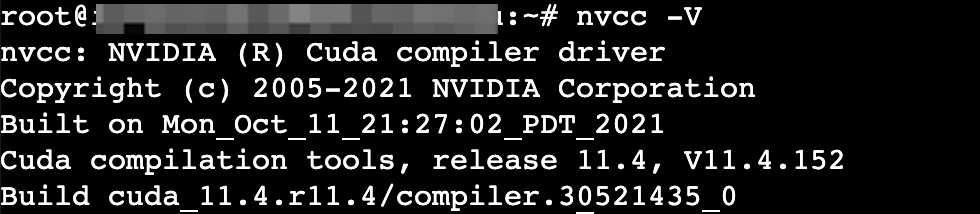
创建虚拟环境
- 执行以下命令,下载Anaconda安装包。
wget https://repo.anaconda.com/archive/Anaconda3-2023.07-2-Linux-x86_64.sh - 执行以下命令,安装Anaconda。
bash Anaconda3-2023.07-2-Linux-x86_64.sh- 持续按“Enter”键进行安装。
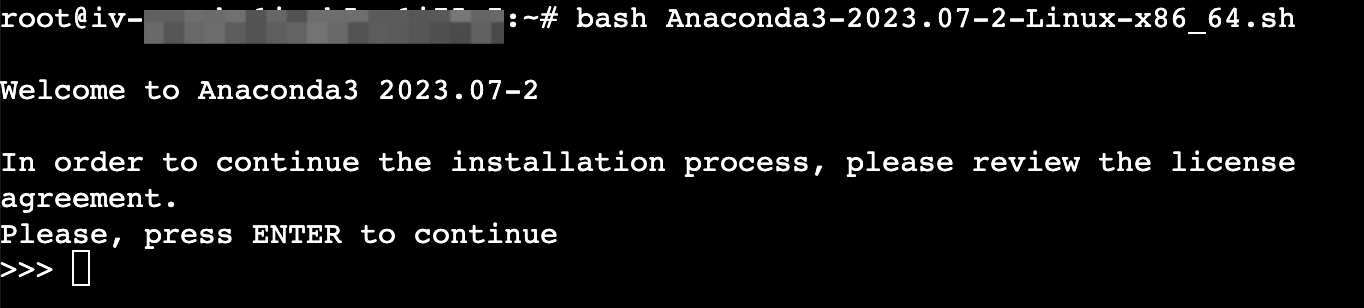
- 输入“yes”确认信息。

- Anaconda的安装路径
/root/anaconda3,请按“Enter”确认安装。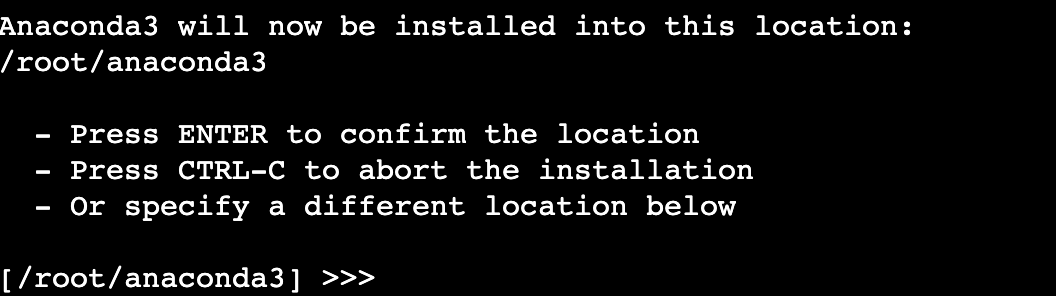
- 输入“yes”确定初始化Anaconda。
- 持续按“Enter”键进行安装。
- 执行以下命令使配置文件生效。
source ~/.bashrc
回显如下,表示配置成功,进入base环境。
- 创建一个名为“deepspeed”的虚拟环境,并指定该环境中的python版本为3.8。
- 执行
conda create -n deepspeed python=3.8命令。 - 回显
Proceed ([y]/n)?时输入“y”确认。 - 执行以下命令,激活虚拟环境。
conda activate deepspeed
回显如下,表示激活成功。
- 执行
安装DeepSpeed
执行以下命令,安装工具包。
sudo apt-get update && apt-get -y install git python3-pip libaio-dev tree执行以下命令,安装git并克隆DeepSpeed官方示例代码。
conda install git git clone https://github.com/microsoft/DeepSpeedExamples.git依次执行以下命令,安装相应的依赖包。
cd DeepSpeedExamples/applications/DeepSpeed-Chat/ pip3 install -r requirements.txt执行以下命令,验证环境是否可用。
python >>>import torch >>>torch.cuda.is_available()回显为
True,表示环境正常可用。输入exit()退出当前环境。
步骤二:选择预训练模型并整理数据集
为了适配DeepSpeed-Chat的微调训练,需要对预训练模型的数据集做一些调整。
说明
本文以预训练模型OPT的医疗数据集为例,为您介绍如何整理数据集。整理好的医疗数据集已上传至Hugging Face,如果符合业务需求,您可以跳过此步骤,直接使用整理好的数据集进行训练。
选择预训练模型。
本文以Facebook的OPT模型为例,您也可以按需选择与您的任务和领域最相关的预训练模型。选择时需考虑多种因素,具体请参见附录一:如何选择预训练模型?。
下载原始数据集并整理。本文采用数据集为医疗数据(Chinese-Medical-Question-Answering-System)。
使用git将原始数据集下载到本地。
git clone https://github.com/GongFuXiong/Chinese-Medical-Question-Answering-System cd Chinese-Medical-Question-Answering-System/ChineseMed_QaData # tree . ├── 1.txt ├── answers.csv # 回答文件 ├── dic4.txt ├── model.txt └── questions.csv # 问题文件整理数据集格式。
为了便于数据处理,将原数据的两个文件合并成一个json文件(dataclean.py),方便程序读取。执行
vim dataclean.py命令,打开dataclean.py文件。按
i进入编辑模式,添加如下内容。import pandas def transform_group(group): group.reset_index(inplace=True) group.drop('que_id', axis='columns', inplace=True) return group.to_dict(orient='records') main = pandas.read_csv('questions.csv', encoding='utf8') attributes = pandas.read_csv('answers.csv', index_col=0, encoding='utf8') attributes = attributes.groupby('que_id').apply(transform_group) attributes.name = "answers" main = main.merge( right=attributes, on='que_id', how='left', validate='m:1', copy=False, ) main.to_json('medical_consultation.json', orient='records', indent=2, force_ascii=False)按
esc退出编辑模式,输入:wq并按Enter键,保存并退出文件。
合并后的json格式为:
{ "que_id":43823757, "ques_content":"头痛,低烧,检查是新型隐球菌脑膜炎?头痛,低烧,检查是新型隐球菌脑膜炎。", "answers":[ { "ans_content":"口服抗病毒药物和感冒冲剂试试.有炎症还是应该加上抗生素。口服药物不见效的,建议输液治疗为好。在当地医生指导下使用。有痰的加上鲜竹沥口服试试。如果发烧还需要适当加上额外的退烧药物。" } ] }, { "que_id":33890331, "ques_content":"刚出生的小孩感冒了,鼻子不通怎么办?", "answers":[ { "ans_content":"你好,刚出生的小孩感冒了,鼻子不通,多与受寒有关。服用小儿氨酚黄那敏颗粒等等看看,注意体温变化,有发热时,要及时就医。" } ] },将数据上传至Hugging Face。
如下图,数据集分为两个文件,分别是用于训练的数据集train.json和用于验证的数据集test.json。为方便使用,后续可直接使用
jisoul/medical_consultation的数据集进行实践操作。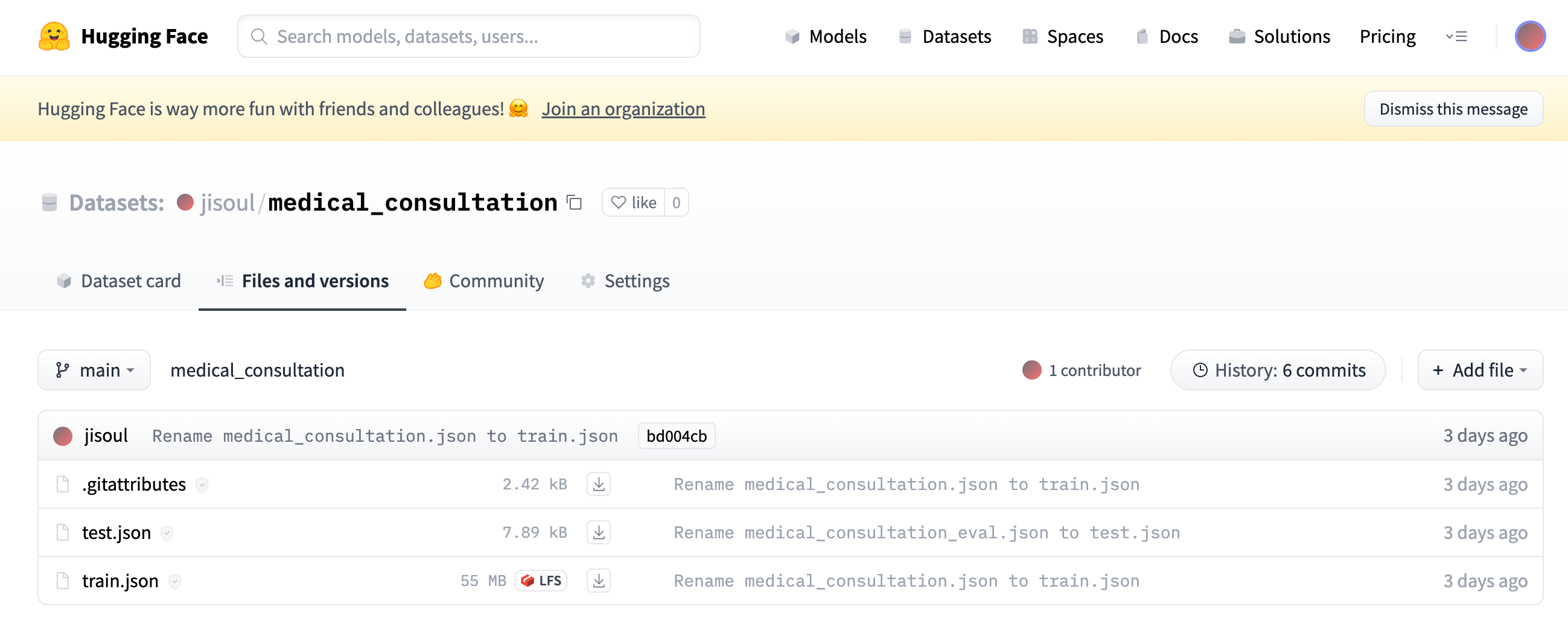
步骤三:创建并调用自定义的数据集类
- 登录实例。
- 创建自定义的数据集类。
- 执行以下命令,打开raw_datasets.py文件。
vim /root/DeepSpeedExamples/applications/DeepSpeed-Chat/training/utils/data/raw_datasets.py - 按
i进入编辑模式,添加如下class类。class MedicalConsultationDataset(PromptRawDataset): def __init__(self, output_path, seed, local_rank, dataset_name): super().__init__(output_path, seed, local_rank, dataset_name) self.dataset_name = "jisoul_medical_consultation" self.dataset_name_clean = "jisoul_medical_consultation" def get_train_data(self): from .data_utils import get_raw_dataset_split_index print(self.raw_datasets) dataset = self.raw_datasets["train"] index = get_raw_dataset_split_index(self.local_rank, self.output_path, self.dataset_name_clean, self.seed, "train_eval", "10,1", 0, len(dataset)) dataset = Subset(dataset, index) return dataset def get_eval_data(self): from .data_utils import get_raw_dataset_split_index dataset = self.raw_datasets["test"] index = get_raw_dataset_split_index(self.local_rank, self.output_path, self.dataset_name_clean, self.seed, "train_eval", "10,1", 1, len(dataset)) dataset = Subset(dataset, index) return dataset def get_prompt(self, sample): if sample['ques_content'] is not None: return " Human: " + sample['ques_content'] + " Assistant:" return None def get_chosen(self, sample): if sample['answers'][0]['ans_content'] is not None: return " " + sample['answers'][0]['ans_content'] return None def get_rejected(self, sample): print( f"Warning: dataset {self.dataset_name} does not include rejected response." ) return None def get_prompt_and_chosen(self, sample): if sample['ques_content'] is not None and sample['answers'] is not None: if sample['ques_content'] is not None and sample['answers'][0]['ans_content'] is not None: return " Human: " + sample['ques_content'] + " Assistant: " + sample['answers'][0]['ans_content'] return None def get_prompt_and_rejected(self, sample): print( f"Warning: dataset {self.dataset_name} does not include rejected response." ) return None - 按
esc退出编辑模式,输入:wq并按Enter键,保存并退出文件。
- 执行以下命令,打开raw_datasets.py文件。
- 调用对应的数据集类。
- 执行以下命令,打开data_utils.py文件。
vim /root/DeepSpeedExamples/applications/DeepSpeed-Chat/training/utils/data/data_utils.py - 按
i进入编辑模式,添加如下条件。elif "jisoul/medical_consultation" in dataset_name: return raw_datasets.MedicalConsultationDataset(output_path, seed, local_rank, dataset_name) - 按
esc退出编辑模式,输入:wq并按Enter键,保存并退出文件。
- 执行以下命令,打开data_utils.py文件。
步骤四:初始化模型参数&微调模型
- 创建训练脚本。
- 执行以下命令,创建训练脚本。
vim /root/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/training_scripts/opt/single_gpu/run_medical_consultation.sh - 按
i进入编辑模式,添加如下内容。参数说明请参见附录二:训练脚本参数介绍。#!/bin/bash # Copyright (c) Microsoft Corporation. # SPDX-License-Identifier: Apache-2.0 # DeepSpeed Team # Note that usually LoRA needs to use larger learning rate OUTPUT=$1 ZERO_STAGE=$2 if [ "$OUTPUT" == "" ]; then OUTPUT=./output/medical_consultation fi if [ "$ZERO_STAGE" == "" ]; then ZERO_STAGE=0 fi mkdir -p $OUTPUT deepspeed --num_gpus 1 main.py \ --data_path jisoul/medical_consultation \ --model_name_or_path facebook/opt-125m \ --gradient_accumulation_steps 4 \ --zero_stage $ZERO_STAGE \ --per_device_eval_batch_size 4 \ --enable_tensorboard \ --tensorboard_path $OUTPUT \ --deepspeed --output_dir $OUTPUT - 按
esc退出编辑模式,输入:wq并按Enter键,保存并退出文件。
- 执行以下命令,创建训练脚本。
- 依次执行以下命令,运行脚本开始训练。
cd /root/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning bash training_scripts/opt/single_gpu/run_medical_consultation.sh
步骤五:对模型进行调优和评估
执行以下命令,启动Tensorboard。
tensorboard --logdir=/root/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/output/ds_tensorboard_logs --bind_all回显如下:

打开浏览器,访问
http://<公网IP>:6006/,查看模型训练过程中的监控信息。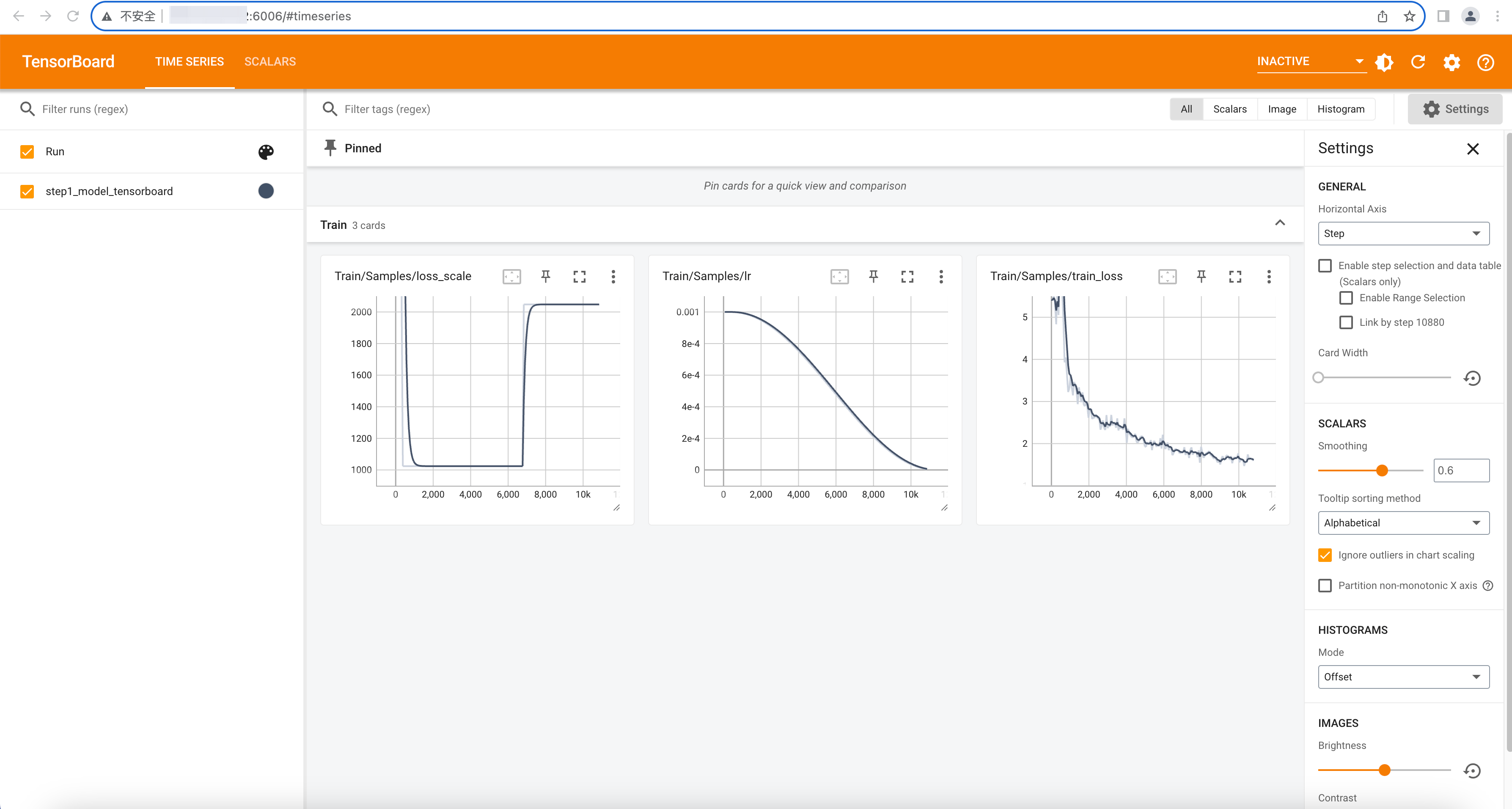
对模型进行评估。
- 执行以下命令,创建模型评估脚本。
vim evaluation_scripts/run_prompt.sh - 按
i进入编辑模式,修改文件内容。
修改后的文件如下图所示。--language Chinese \ --model_name_or_path_baseline facebook/opt-125m \ --model_name_or_path_finetune /root/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/output/medical_consultation/
- 按
esc退出编辑模式,输入:wq并按Enter键,保存并退出文件。
- 执行以下命令,创建模型评估脚本。
执行以下命令,运行脚本。
bash evaluation_scripts/run_prompt.sh
步骤六:对微调后的模型进行部署和应用
安装Gradio和Transformers。
执行以下命令进行安装。
pip3 install gradio transformers==4.32.1 -i https://mirrors.ivolces.com/pypi/simple/依次执行以下命令,查看是否安装成功。
pip3 list | grep gradio pip3 list | grep transformers回显如下,表示Gradio和Transformers均已安装。

编写
medical_consultation_gradio.py文件用于加载微调后的模型。- 执行
vim medical_consultation_gradio.py命令。 - 按
i进入编辑模式,添加如下内容。import gradio as gr import torch from transformers import AutoModelForCausalLM, AutoTokenizer, StoppingCriteria, StoppingCriteriaList, TextIteratorStreamer from threading import Thread tokenizer = AutoTokenizer.from_pretrained("/root/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/output/medical_consultation/") model = AutoModelForCausalLM.from_pretrained("/root/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/output/medical_consultation/") model = model.to('cuda:0') class StopOnTokens(StoppingCriteria): def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool: stop_ids = [29, 0] for stop_id in stop_ids: if input_ids[0][-1] == stop_id: return True return False def predict(message, history): history_transformer_format = history + [[message, ""]] stop = StopOnTokens() messages = "".join(["".join(["\n<human>:"+item[0], "\n<bot>:"+item[1]]) #curr_system_message + for item in history_transformer_format]) model_inputs = tokenizer([messages], return_tensors="pt").to("cuda") streamer = TextIteratorStreamer(tokenizer, timeout=10., skip_prompt=True, skip_special_tokens=True) generate_kwargs = dict( model_inputs, streamer=streamer, max_new_tokens=1024, do_sample=True, top_p=0.95, top_k=1000, temperature=1.0, num_beams=1, stopping_criteria=StoppingCriteriaList([stop]) ) t = Thread(target=model.generate, kwargs=generate_kwargs) t.start() partial_message = "" for new_token in streamer: if new_token != '<': partial_message += new_token yield partial_message gr.ChatInterface(predict).queue().launch(share=True) - 按
esc退出编辑模式,输入:wq并按Enter键,保存并退出文件。
- 执行
执行以下命令,运行脚本。
python3 medical_consultation_gradio.py
浏览器访问public URL(
https://<公网IP>.gradio.live),如下图,表示成功使用Gradio构建生成式AI应用程序。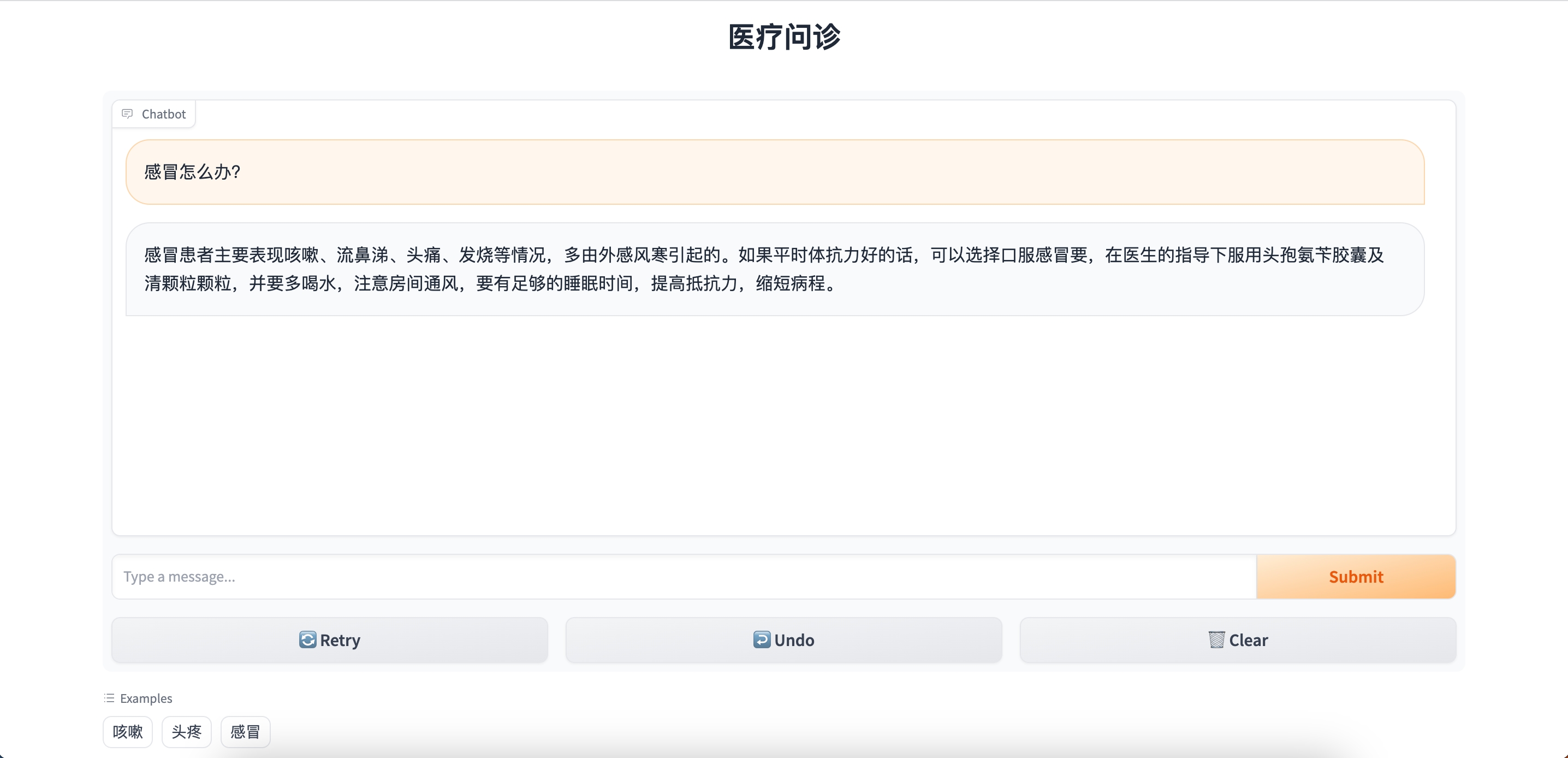
附录
附录一:如何选择预训练模型
预训练模型即已经用数据集训练好了的模型,选择预训练模型时可以考虑以下几个因素:
| 考虑因素 | 说明 |
|---|---|
选择与任务和领域最相关的预训练模型 | 不同的模型可能在不同的任务上表现更好,因此需要根据您的具体需求选择适合的模型。 |
| 了解预训练模型的性能和表现 | 查阅相关文献、研究论文或开发者文档,了解模型在不同任务和数据集上的表现。通常,可以使用常见的性能指标(如准确率、召回率、F1分数等)来评估模型的性能。 |
| 考虑预训练模型的规模和复杂度 | 大型模型通常具有更多的参数和更高的计算成本,但也可能具有更好的表现。如果您有足够的计算资源和数据量,可以选择规模较大的模型来获取更好的性能。 |
| 优先选择开放源代码和广泛可用的预训练模型 | 此类模型通常有更多的支持和社区贡献,可以更容易地获得文档、示例代码和工具。 |
| 考虑预训练模型的迁移学习性质 | 某些模型在不同任务和领域之间的迁移学习效果更好,可以更快地适应新任务。这对于数据量较小或计算资源受限的情况尤为重要。 |
| 了解模型的更新和维护情况 | 一些模型可能会定期更新,以改进性能或修复问题。选择有活跃维护和支持的模型,以确保您可以获得最新的改进和修复。 |
附录二:训练脚本参数介绍
| 参数 | 解释 |
|---|---|
| --data_path | 数据集名称,默认从Hugging Face下载数据集文件 |
| --model_name_or_path | 模型名称,默认从Hugging Face下载模型文件 |
| --gradient_accumulation_steps | 开启梯度累积的step数 |
| --zero_stage | Zero stage,可选0、1、2、3 |
| --per_device_train_batch_size | 每块GPU运行的batch_size数 |
| --enable_tensorboard | 打开Tensorboard |
| --tensorboard_path | Tensorboard events的输出路径 |
| --output_dir | 微调后的最终模型文件存储路径 |