实时整库同步
最近更新时间:2024.04.29 14:48:23
首次发布时间:2023.08.14 10:14:48
一键实时整库同步解决方案支持多种数据源之间,进行数据的全增量一体化同步,方案中先将源端全量数据通过离线任务方式同步迁移,然后再通过实时同步增量任务,将数据采集至目标端数据源中。
您也可以单独选择进行实时增量数据同步,该场景适用于您已经通过其他方式将全量数据同步至目标端数据源库表中。您可根据实际场景,进行同步方案选择配置,助力您将业务数据更高效、更便捷的同步至目标数据库中。
本文将为您介绍如何创建实时整库同步解决方案,将源端 MySQL、VeDB、PostgreSQL、SQLServer、Mongo、Oracle 数据采集至湖仓一体分析服务(LAS)、Doris、StarRocks、Elasticsearch、ByteHouse 云数仓版(ByteHouse CDW)、ByteHouse 企业版(ByteHouse CE) 数据源的库表/索引中。
1 关键步骤概述
- 目标表创建:将源端表数据写入到目标表中,目标表创建可以是以下三种方式:
- 已有表:手动在目标数据库环境中,已创建好源端同名表来接收数据,此时方案步骤执行时,将跳过建表的流程。
- 自动建表:在目标数据库环境中,还没有与源端数据表同名的目标表,此时方案步骤执行时,会自动在流程中创建同名目标表。
- 数据表不存在:当目标端无法通过 DataSail 自动建表时,您需要进入目标端数据库中,手动创建数据表后,再继续配置解决方案。
- 增量实时任务位点初始化:首次启动时,会自动指定增量流式任务的初始化位点位置。
- 任务创建:视实际使用场景,将会创建不同的任务类型。
- 全增量场景:一次性全量批式任务+增量流式任务
- 首先创建一次性全量批式任务,将历史全量数据,同步至目标端数据库表中;
- 待全量批式任务执行完成后,再创建增量流式任务,通过启动流式任务的方式,将源端数据实时同步至目标端数据库表中。
说明
同步方案产生的一次性全量批式任务个数,与方案中设置的数据来源表个数有关。
- 增量场景:增量流式任务
仅创建增量流式任务,通过流式任务运行的方式,仅将源端增量数据实时同步至目标端数据库表中。
- 全增量场景:一次性全量批式任务+增量流式任务
2 前置操作
- 已开通并创建 DataLeap 项目,创建的全量增量任务均会同步到该项目下。详见新建项目。
- 已开通全域数据集成(DataSail)产品。详见服务开通。
- 已创建合适资源规格的独享数据集成资源组,并将其绑定至创建成功的 DataLeap 项目下。购买操作详见资源组管理,项目绑定操作详见数据集成资源组。
- 已完成来源和目标端的数据源准备,创建数据源操作详见配置数据源。
3 注意事项
- 同步解决方案同时支持选择的表数量目前上限为 2000 张,但建议先以 100 张以下表数量来试用。
- 目标端数据库需要提前先创建好,暂不支持在解决方案中自动创建。
- 目前表建立方式为选用已有表时,需要保证目标表 Schema 和源表 Schema 的表名称、字段名称和字段数量数量保持一致。
- 解决方案同步数据至目标端 LAS、Doris、StarRocks、ByteHouse CDW、ByteHouse CE 时,仅支持将数据写入非分区表,暂不支持写入数据至分区表。
4 数据同步解决方案
4.1 数据源配置
在配置实时整库同步解决方案前,您需在数据源管理界面中,配置来源端和目标端相应的数据源。详见配置数据源。
- 独享数据集成资源组所在的 VPC 需要和来源端、目标端数据库实例所在的 VPC 保持一致,火山引擎 RDS 数据库类型需要将 VPC 中的 IPv4 CIDR 地址,加入到 RDS 数据库的白名单下,保证资源组与数据源之间的网络互通;
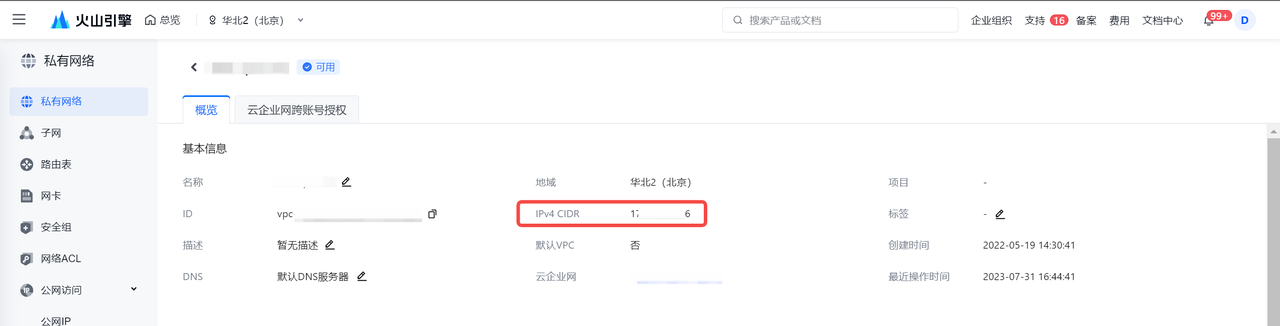
- 若资源组和数据源实例不在同一 VPC 环境时,您可通过公网或者通过专线形式进行互通。网络配置详见网络连通解决方案。
4.2 新建数据实时整库同步
数据源配置操作准备完成后,您可开始进行实时整库同步方案配置:
- 登录 DataSail 控制台。
- 在左侧导航栏中选择数据同步方案,进入同步方案配置界面。
- 单击目录树中项目选择入口,选择已创建的 DataLeap 项目。
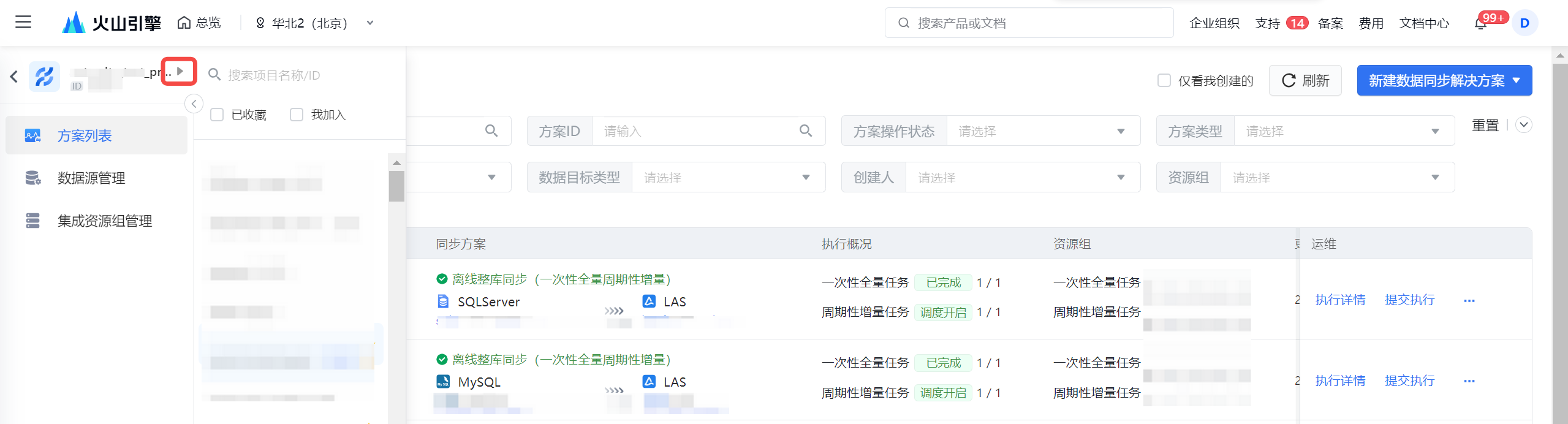
- 单击右上角新建数据同步解决方案按钮,下拉选择实时整库同步按钮,进入整库实时同步方案配置界面。按照以下配置,完成方案新建。
进入配置界面后,您可按实际场景需求,完成方案的基本配置、数据来源配置、数据缓存配置、数据目标配置、DDL 策略配置、运行配置等六个流程配置。
4.3 基本配置
基本配置参数说明如下表所示。其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。
配置项 | 说明 |
|---|---|
基本信息 | |
*方案名称 | 输入整库实时同步方案名称。只允许字符.、字母、数字、下划线、连字符、[]、【】、()、()以及中文字符,且需在127个字符以内。 |
方案描述 | 输入此方案的描述信息,方便后续维护管理。 |
*保存至 | 下拉选择方案保存路径,此路径为数据开发项目中的任务路径。创建方式详见任务目录树管理。 |
*链路类型 | 下拉选择来源和目标端数据源类型,不同来源数据源支持写入的目标数据源类型不同,详见产品配置界面。
|
网络与资源配置 | |
*数据来源 | 下拉选择数据源管理中创建成功的源端数据源名称。 |
数据缓存 | 选择实时同步解决方案执行过程,采集数据时是否使用缓存配置方式:
缓存说明详见“4.5 数据缓存配置”。 |
*数据目标 | 下拉选择数据源管理中创建成功的目标端数据源名称。 |
*离线/实时集成任务资源组(离线全量/实时整理) | 下拉选择 DataLeap 项目控制台中已绑定的独享数据集成资源组:
|
方案基本配置完成后,单击右下角下一步按钮,进行方案的数据来源配置。
4.4 数据来源配置
在数据来源配置界面中,完成数据来源设置与库表映射规则匹配策略:
其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。
配置项 | 说明 |
|---|---|
数据源设置 | |
*数据源 | 下拉选择数据源管理中创建成功的数据源。若此前仍未创建相应数据源,您可单击右侧数据源管理按钮,前往数据源管理界面,进行数据源的创建。 |
*表选择模式 | 支持通过指定表或正则方式进行表的选择:
|
*数据表 | 指定表模式选择时,在左侧您可选择来源数据库表信息:
|
*源库、源 Schema、源表/集合选择限定条件 | 正则模式选择时,您可通过设置源库、源 Schema、源表的限定条件,来获取源表信息。
|
表/集合 | 单击获取源表/获取源集合按钮,平台根据源库、源表/集合限定条件的设置,自动加载符合条件的表/集合。 注意 选择的多个库表,需保证其 Schema 信息一致(包括字段名称、字段类型)。 |
映射规则 | |
*库表匹配策略 | 支持选择与来源库表同名和自定义方式匹配:
|
数据来源配置完成后,单击右下角下一步按钮,进行方案的数据缓存配置。
4.5 数据缓存配置
使用缓存,可对同步任务进行缓冲,在性能和稳定性上有所提升,适合对稳定性要求高以及数据量大的场景,但需额外增加缓存数据源及相应成本,请按需配置。
实时整库同步解决方案,目前支持“增加缓存”、“无需缓存,直接同步”这两种缓存配置方式:
4.5.1 增加缓存
可通过使用中间缓存来采集源端数据,增加缓存需要绑定数据来源对应的 CDC 采集数据进入的 MQ。若还未创建采集方案,您需到解决方案-实时数据采集界面,进行方案创建。详见实时数据采集方案。这种方式需要额外配置 Kafka 数据源、DataSail(内置 Topic) 数据源、BMQ 数据源。
说明
Kafka、BMQ 数据源类型,也可通过创建相应的 CDC 数据订阅采集任务,将源端 MySQL 中的数据,通过数据库传输服务中数据订阅方式,实时采集到 Kafka 实例中。在数据来源配置时绑定对应的 CDC 采集数据进入的 Kafka。数据订阅操作详见数据库传输服务。
- 数据源选择:根据实际情况,按需选择数据源类型。
- 映射配置:
数据源类型选择完成后,单击刷新数据源和Topic映射按钮,根据数据源类型,进行相关的映射配置。您可在下拉框中,选择已创建的来源、目标端数据源、Topic 名称和绑定解决方案信息。说明
实时采集解决方案支持绑定多个。
- 单击“添加映射配置”按钮,您可按需添加多个数据源和 Topic 映射关系;
- 单击“映射字段全量配置”按钮,可为多个映射关系,批量操作添加对应的 Topic 和绑定解决方案操作。
4.5.2 无需缓存,直接同步
无需缓存方式,可通过直接采集 MySQL Binlog 日志,进行数据实时读取。
说明
火山引擎中 RDS 云数据库已默认开启 Binlog 协议,若源端为其他云数据库或自建数据库,您需确认数据库是否已开启 Binlog。
确认数据缓存同步方式后,单击右下角下一步按钮,进入数据目标设置。
4.6 数据目标设置
在数据目标配置界面中,完成数据源目标端设置与映射相关配置:
其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。
配置项 | 说明 | |
|---|---|---|
数据源设置 | ||
*数据源 | 下拉选择数据源管理中创建成功的目标端数据源。 | |
映射配置 | ||
高级配置 | 使用已有表配置 | 当目标表已存在,即下方“表建立方式”为“使用已有表”时,若此时源表与目标表中已有字段列不一致时,可通过列匹配规则,根据实际场景进行列映射规则设置,目前支持自动映射、同名取交映射两种匹配规则配置:
|
高级参数配置 | 您可为同步解决方案配置全局的高级参数,以 key-value 的形式输入。 | |
*刷新源表和目标表映射 | 单击刷新源表和目标表映射按钮,自动加载源表和目标表信息,您可以在列表中进行以下操作: | |
筛选库表 | 单击漏斗按钮,您可输入源端与目标端的库表信息,进行筛选搜索。 | |
排序策略 | 排序策略将影响实时增量任务,若无排序字段,可能会出现上游乱序导致下游数据源错误,建议增加排序策略。
| |
表建立方式 | 表建立方式分为使用已有表、自动建表和数据表不存在几种方式:
| |
全量同步 |
| |
清表策略 | 您可根据实际情况,选择是否开启清表策略,开启表示在数据写入目标表前,会清空原有目标表中的数据,通常是为了使任务重跑时支持幂等操作。 | |
查看字段信息 | 可以查看来源表、目标表的字段名和其对应的字段类型等信息。在弹窗中,您也可对自动创建的目标表字段类型和字段描述信息,进行手动编辑调整。 | |
配置 | 您可为同步解决方案配置多表映射高级参数,以 key-value 的形式输入。 | |
移除 | 单击操作列中的更多 > 移除按钮,可将当前源端与目标端的映射删除。 | |
重置 | 单击操作列中的更多 > 重置按钮,可重置源表与目标表的映射关系。 | |
说明
当目标表数量较多时,您可勾选多个表后,批量对目标表进行全量同步设置、清表策略设置或移除等操作。
数据目标配置完成后,单击右下角下一步按钮,进行方案的 DDL 策略配置。
4.7 DDL 策略配置
在实时整库 CDC、分库分表、离线整库解决方案中,通常会遇到较多来源端新增表、新增列等 DDL 操作场景。此时您可根据实际业务场景,对来源端不同的 DDL 消息,在配置解决方案同步到目标端数据源时,可进行预设不同的处理策略。
不同数据源中不同的 DDL 消息目前可能支持的处理策略不同,整体处理策略如下:
- 自动处理: 即会在来源端捕获的 DDL 消息,下发给目标数据,由目标数据来自动响应处理,包括自动加表、自动加列、自动变更列类型等。不同目标数据对 DDL 消息处理策略可能不同,平台仅执行转发操作。
- 忽略变更: 即会丢弃掉此 DDL 消息,不向目标数据源发送此消息,目标端数据源不做任何响应。
- 日志告警: 即会丢弃掉此 DDL 消息,但会在同步日志中记录 DDL 变更消息详情。
- 任务出错: 即一旦源端出现 DDL 变更,同步任务将显示出错状态并终止运行。
目前不同 DDL 消息处理策略情况如下:
DDL 消息 | 自动处理 | 忽略变更 | 日志告警 | 任务出错 |
|---|---|---|---|---|
新建表 | ✅ | ✅ | ✅ | ✅ |
删除表 | ✅ | |||
重命名表 | ✅ | |||
新增列 | ✅ | ✅ | ✅ | ✅ |
删除列 | ✅ | |||
重命名列 | ✅ | |||
修改列类型 | ✅ | ✅ | ✅ | ✅ |
清空表 | ✅ |
注意
- 若在数据缓存配置中,您使用 Kafka 缓存的同步方式时,则所有源端的 DDL 消息均只能做忽略变更处理。
- 目前仅实时整库、分库分表方案中 MySQL2StarRocks、MySQL2Doris、MySQL2ByteHouse_CDW 通道,离线整库方案中 PostgreSQL2Hive 通道,方可设置新建表、新增列、修改列类型的所有处理策略,其余通道,仅支持对 DDL 消息做忽略变更处理。
- 新建表的自动处理策略,仅在数据来源表选择模式为“正则”模式下时生效。来源表配置详见4.4 数据来源配置
- 新增列变更消息自动处理策略目前存在以下限制:
- 源端中主键列不支持自动加列;
- 目标端自动增加的列,需允许存在 null 值;
- 如配置列名映射规则,则不再支持自动加列操作。
- 修改列类型变更消息自动处理策略目前存在以下限制:
- 源端中主键列不支持自动修改列类型;
- 如目标端列已为 string 类型,则不再跟随源端类型变更;
- 列类型的存储数据范围不支持由大改小,例如目标端列类型已为 bigint 类型,源端即使再次变更为 int,目标端将依然保持为 bigint,否则可能引起字段溢出问题。
- 如需对已创建的任务进行 DDL 策略修改,您可在解决方案列表界面,单击运维列中方案编辑 > DDL 策略配置流程,修改 DDL 消息规则。示例详见解决方案源表字段类型变更实践
DDL 策略配置完成后,单击右下角下一步按钮,进行任务运行配置。
4.8 运行配置
离线全量同步
其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。配置项
说明
*离线集成任务资源组
下拉选择 DataLeap 项目控制台中已绑定的独享数据集成资源组:
- 选择的资源组,需要确保能与源端、目标端数据源连通,您可单击右侧的连通性测试按钮,进入测试窗口,单击连通性测试按钮,测试选择的资源组是否可以和两侧数据源连通成功。
- 您也可以单击资源组管理按钮,前往资源组管理界面进行资源组的查看或新建等操作,详见资源组管理。
*默认 Quota 数
设置可同时提交执行的集成任务数量,可根据独享集成资源组规格进行配置,如资源组的大小为 40CU,则 Quota 配置需必须小于 20(40/2),否则会因资源问题导致任务执行时异常。
*期望最大并发数
设置离线任务同步时,可以从源端并行读取或并行写入目标端的最大线程数。
并发数影响数据同步的效率,并发设置越高对应资源消耗也越多,由于资源原因或者任务本身特性等原因,实际执行时并发数可能小于等于设置的期望最大并发数。脏数据设置
设置脏数据处理方式,当任务中字段映射没有匹配到的数据,如格式非法,或同步过程中源端数据进入目标端时发生了异常。例如:源端是 String 类型的数据写到 INT 类型的目标字段中,因为类型转换不合理而无法写入的数据。
您可以在此通过以下两种方式设置脏数据的处理方式:- 勾选忽略所有脏数据,任务正常运行,脏数据不写入目标端。
- 设置脏数据的最大容忍条数或占比情况,如果配置 0,则表示不允许脏数据存在,任务会运行失败退出。
集成高级参数设置
打开高级参数输入按钮,根据实际业务要求,以 Key\Value 形式,在编辑框中输入离线任务所需的高级参数。支持参数详见高级参数。
实时增量同步
设置解决方案中实时增量任务的运行参数情况。
其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。配置项
说明
*实时集成任务资源组
下拉选择 DataLeap 项目控制台中已绑定的独享数据集成资源组:
- 选择的资源组,需要确保能与源端、目标端数据源连通,您可单击右侧的连通性测试按钮,进入测试窗口,单击连通性测试按钮,测试选择的资源组是否可以和两侧数据源连通成功。
- 您也可以单击资源组管理按钮,前往资源组管理界面进行资源组的查看或新建等操作,详见资源组管理。
*资源设置
可通过自定义和默认两种设置方式,进行实时任务运行资源的设定,如单TaskManager CPU数量、单TaskManager内存大小、JobManager CPU数量等。
说明
默认设置中,各运行资源设置如下:
- 单 TaskManager CPU 数:2
- 单 TaskManager 内存:4096 MB
- 单 TaskManager slot 数:4
- JobManager CPU 数:1
- JobManager 内存:2048 MB
集成高级参数设置
打开高级参数输入按钮,根据实际业务要求,以 Key\Value 形式,在编辑框中输入实时任务所需的高级参数。支持参数详见高级参数。
Flink 运行参数设置
支持输入 Flink 相关的动态参数和执行参数,具体参数设置详见 Flink 官方文档。
调度设置
离线全量任务还需要任务调度资源组,来支持任务下发分配至独享数据集成资源组中运行,目前调度资源组支持选择公共调度资源组和独享调度资源组。提交方案
方案运行配置完成后,单击右下角提交方案按钮,进行方案的提交,在弹窗中,您可根据实际情况勾选方案是否立即执行,并单击确定按钮,完成实时数据同步解决方案的创建。
5 实时整库方案运维
方案创建完成后,进入到方案列表界面,便可查看方案的执行概况,同时您也可以在列表界面进行以下操作:
5.1 解决方案筛选
在创建众多的解决方案后,您可在方案列表界面通过搜索或筛选的方式进行快速定位方案。
- 您可通过方案名称、方案 ID、数据来源名称、数据目标名称等信息,输入搜索的方式进行筛选。
- 您也可通过下拉选择方案操作状态、方案类型、数据来源名称、数据目标类型、创建人等选项进行任务的定位操作。
5.2 解决方案运维
在方案列表的运维列中,您可操作执行方案运维相关内容:
说明
启动中的解决方案不支持进行提交执行、方案编辑、方案删除操作。
运维操作 | 说明 |
|---|---|
执行详情 |
|
提交执行 | 未在启动中的任务,您可单击运维操作列的提交执行按钮,将任务提交到运行状态,开启增量流任务的运行。
|
方案查看 | 单击运维操作列更多中的方案查看按钮,可对当前解决方案的各个配置步骤进行查看。 |
方案编辑 | 单击运维操作列更多中的方案编辑按钮,可对当前解决方案的方案名称、数据来源端、目标端、DDL 策略配置、运行配置步骤进行修改编辑,如您可在数据来源配置步骤中,为当前解决方案新增同步表或删除已选择的同步表等操作。 |
方案删除 | 单击运维操作列更多中的方案删除按钮,将处于非运行中、非启动中的方案进行删除,当前仅删除解决方案本身,已生成的表和集成任务不会被删除。 |
运行监控 | 单击运维操作列更多中的运行监控按钮,为当前实时整库同步方案配置一次性全量、实时增量任务的运行监控。 |
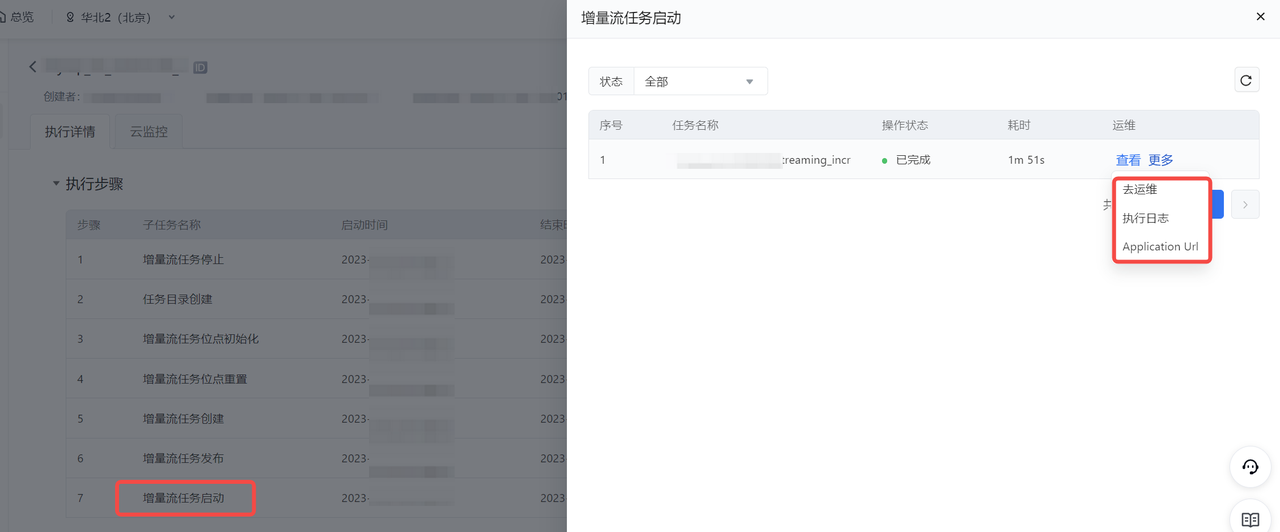
强制重启 | 单击运维操作列更多中的强制重启按钮,将之前创建的解决方案再次提交执行,区别于提交执行,强制重启会位点初始化、全量批任务清理、重启全量批任务等操作。 |
提交停止 | 单击运维操作列更多中的提交停止按钮,可将处于正常运行中的增量流任务进行停止操作。 |
操作历史 | 单击运维操作列更多中的操作历史按钮,您可查看当前同步方案的操作历史情况,如创建方案、重启方案、提交停止等操作,均会记录在操作历史中。您可单击操作列中的查看详情按钮,对历史版本的操作进行查看。 |
6 后续步骤
方案提交完成,任务处于运行中后,您也可以前往运维中心 > 实时任务运维界面,对实时增量任务进行一系列运维操作,如对任务配置监控报警,开启停止任务等操作。运维操作详见实时任务运维。