K-means聚类算法的问题包括哪些条件
 社区干货
社区干货
时效准确率提升之承运商路由网络挖掘
聚类方法,证实了我们的猜想。下面图中,横轴表示的是出分拣中心的小时,每一个点表示历史上的某一个运单,纵轴没有业务含义,只是为了方便显示。绘制上述图时使用的是kmeans聚类算法,kmeans聚...
Katalyst:字节跳动云原生成本优化实践
(https://github.com/kubewharf/katalyst-core)## 1.背景字节从 2016 开始着手服务云原生化改造,截至今日字节服务体系主要包含四类:**传统微服务**大多是基于 Golang 的 RPC Web 服务;**推广搜服务**是传统 C++ 服务,对性能要求更高;此外还有**机器学习和大数据**以及**各类存储服务**。云原生后需要解决的核心问题是如何提高集群的资源利用效率;以典型的在线服务的资源使用情况为例,深蓝色部分是业务实际使用的资源量,浅蓝...
【Flocking算法】海王的鱼塘是怎样炼成的 | 社区征文
## 一、引言目前,人工智能的热潮可以节节攀升,今天我通过unity动态化演示的方法为大家介绍人工智能领域的一个算法 -- **集群算法**。正式开始之前,我们先来搞懂一下究竟什么叫Flocking算法?**Flocking algorithm** 国内一般称为**蜂拥算法**,由许多离散的动物形成,但群体整体上是流动的,这是个体行为的综合结果。典型的自然现象包括:蜂群、鸟群、鱼群、兽群等,这些动物聚集的现象(包括人类)可以帮助生物更好的躲避天敌、...
VikingDB:大规模云原生向量数据库的前沿实践与应用
我们在火山引擎推出了 VikingDB 的商业化版本,以更好地对外部客户进行赋能。**应用:Retrieval-Augmented Generation**大语言模型在生成文本方面表现出色,但也存在一些限制,如知识局限性和幻觉问题。为了克服... VikingDB 集成了常用的 embedding 模型,用户可以方便地导入、检索文本等非结构化数据,之后 VikingDB 再自动将其转换为向量并存储,最终提供检索能力。除了近似向量检索,VikingDB 还提供聚类查询、基于向量的相关...
 特惠活动
特惠活动
 K-means聚类算法的问题包括哪些条件-优选内容
K-means聚类算法的问题包括哪些条件-优选内容
 K-means聚类算法的问题包括哪些条件-相关内容
K-means聚类算法的问题包括哪些条件-相关内容
【Flocking算法】海王的鱼塘是怎样炼成的 | 社区征文
## 一、引言目前,人工智能的热潮可以节节攀升,今天我通过unity动态化演示的方法为大家介绍人工智能领域的一个算法 -- **集群算法**。正式开始之前,我们先来搞懂一下究竟什么叫Flocking算法?**Flocking algorithm** 国内一般称为**蜂拥算法**,由许多离散的动物形成,但群体整体上是流动的,这是个体行为的综合结果。典型的自然现象包括:蜂群、鸟群、鱼群、兽群等,这些动物聚集的现象(包括人类)可以帮助生物更好的躲避天敌、...
VikingDB:大规模云原生向量数据库的前沿实践与应用
我们在火山引擎推出了 VikingDB 的商业化版本,以更好地对外部客户进行赋能。**应用:Retrieval-Augmented Generation**大语言模型在生成文本方面表现出色,但也存在一些限制,如知识局限性和幻觉问题。为了克服... VikingDB 集成了常用的 embedding 模型,用户可以方便地导入、检索文本等非结构化数据,之后 VikingDB 再自动将其转换为向量并存储,最终提供检索能力。除了近似向量检索,VikingDB 还提供聚类查询、基于向量的相关...
观点|词云指北(上):谈谈词云算法的发展
而经典的 Wordle 算法诞生并流行至今,其排序方法多与词频或其他单词重要性有关。与此同时,力导向布局也是词云中常见的布局方式。1. **行列布局,** 即将单词在画布上从左到右/从上到下进行对齐排列,是早期常见的... 算法大致步骤为:1. **使用 k-means 对有相同标签的点进行聚类。** 可能有相隔很远的两个点有相同的标签,此时会被聚集成两簇,如上图中的 Tomme。聚类后的每个簇各代表一个单词。2. **聚类后,为每个簇设置合适的...
未来向量数据库的崛起与多元化场景创新 主赛道 | 社区征文
这些数据可能包括文本、图像、音频和视频,使用各种过程(如机器学习模型、词嵌入或特征提取技术)将其转换为向量。**典型的三大向量数据:****图像向量**:依据深度学习模型获得的图像特点向量捕捉图像的重要信息,如色彩、外型、线框等,可用作图像鉴别、检索等任务;**文本向量**:通过词嵌入技术如 Word2Vec、BERT 等生成的文本特征向量,这些向量包含了文本的语义信息,可以用于文本分类、情感分析等任务;**语音向量**:通过声学...
[数据库论文研读] HTAP行列混存 & 智能转换
但是以上提到的系统结构显然存在一些问题:1. **系统存在time lag。** OLTP和OLAP系统之间要通过第三方工具传递数据,数据量越大会导致同步的lag越大,限制了系统的能力(例如会要求用户K分钟后才能在刚写入的数据... 那么实现一个HTAP系统的主要难点是什么?论文里提到的是:系统要同时执行OLAP任务和OLTP任务,OLAP任务会同时访问即时 & 历史数据,OLTP任务也很可能会update新 & 老数据,一旦OLAP和OLTP任务要访问的数据有读写交叉,要...
我的技术年终总结——机器学习 |社区征文
**训练**:用数据训练算法模型(算法从数据中分析规律)- **预测**:利用训练后的算法完成任务(根据学习的规律为未知数据进行分类和预测) 通过周志华老师西瓜书上面的描述为下图: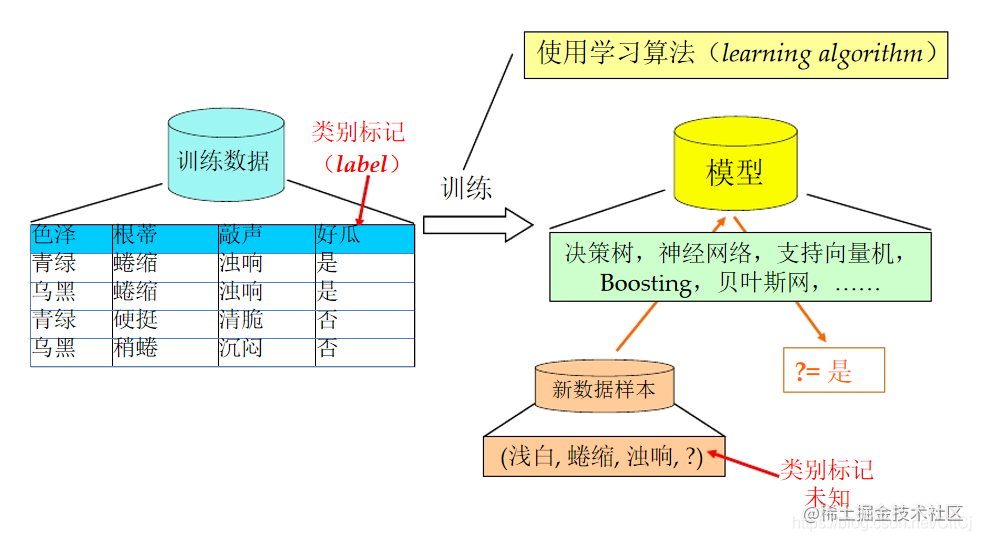## 二、机器学习能做什么? ### 数据集上 一个重要问题: 原书籍已经变成分散且混杂的多个书...
浅谈AI机器学习及实践总结 | 社区征文
回归问题的标签是连续的数值,比如预测房价、股市等,分类问题的标签是离散的数值,比如人脸识别、判断是否正确等,判断两款运营策略哪种更有效。可以根据特征快速拆分已有人群,搭配后续针对性的营销策略。- 聚类模型( K-means算法)可以根据特征快速拆分已有人群,场景举例: - ...
火山引擎ByteHouse:“专用向量数据库”与“数据库+向量扩展”,怎么选?
它使用不同的算法进行索引和相似度计算。当你拥有数百万个嵌入时,使用简单的 K 近邻(kNN)算法计算查询与你拥有的每个嵌入对象之间的相似度会变得耗时。通过使用近似最近邻搜索,你可以在一定程度上牺牲一些准确性... 以便快速地进行相似度匹配和聚类分析等操作。4. 数据查询向量化存储后,需要进行数据查询,包括相似度匹配和聚类分析等操作。相似度匹配是指在向量数据库中查找与查询向量最相似的向量,常用的相似度计算方法有余...
