存储这些数据的最优方式是什么?
 社区干货
社区干货
[数据库系统] 业界列式存储浅析
相同column的数据组成一个一个的块,排列结构如下图所示: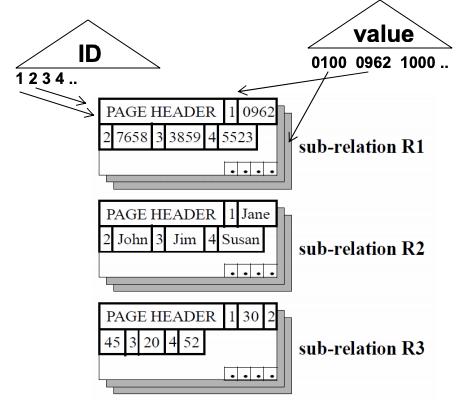通过两者的存储方式我们... 作用是提供高性能的 inserts和 updates;1. RS: Read-optimized Store,作用是提供针对读优化的高效查询,仅提供固定格式的insert方法;Tuple Mover 负责批量从WS搬运到RS;Query 需要访问WS和RS,然后合并结果;inse...
干货|DataLeap数据资产实战:如何实现存储优化?
解决了数据生产者和消费者对于元数据和资产管理的各项核心需求。** Data Catalog系统的存储层,依赖Apache Atlas,传递依赖JanusGraph。JanusGraph的存储后端,通常是一个Key-Column-Value模型的系统, **本... 数据存储由一系列行组成,每行都由一个键(key)唯一标识,每行由多个列值(column-value)对组成,也会对列进行排序和过滤; 如果是非 column-family的类型存储,则需要另行适配,适配时数据模型有两种方式:Key-C...
火山引擎云存储选型指南 x 自动驾驶场景最佳实践
高性价比的存储平台。# 云存储产品选型方法论## 存储选型考量在选型之前,我们应该对业务应用进行场景化分析,比如要存储什么类型的数据、需要什么样的接口协议、对功能和性能有怎样的要求、业内是否有相关场景的最佳实践等等。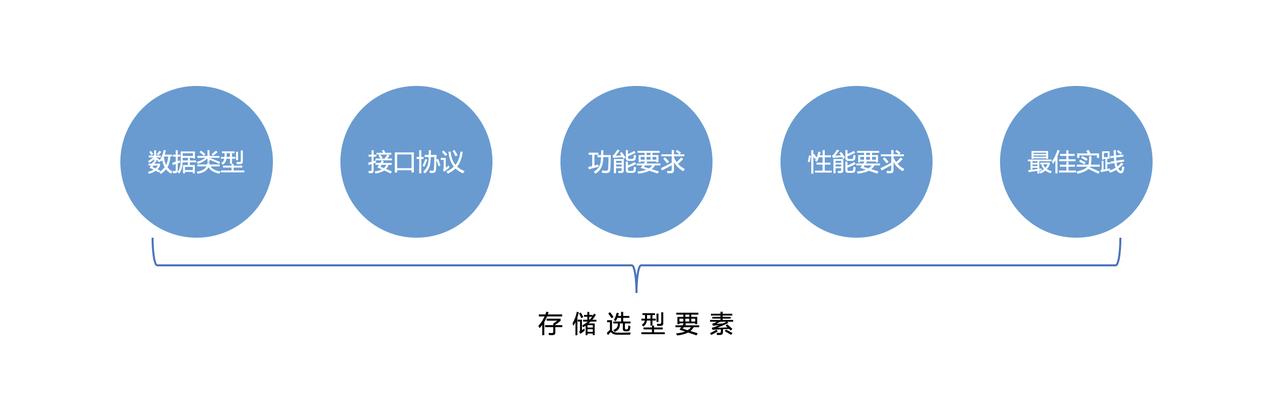以AI/ML场景举例,不同阶段的存储工作负载具有不同的特点(如下图...
表设计之数据类型优化 | 社区征文
## 1. 概述MySQL 支持的数据类型非常多,选择正确的数据类型对于获得高性能至关重要。不管存储哪种类型的数据,下面几个简单的原则都有助于做出更好的选择。## 2. 基本原则### 2.1 越小越好一般情况下,应该尽... 比如应该使用 MySQL 内建的类型而不是字符串来存储日期和时间。### 2.3 避免 NULL很多表都包含可为 NULL(空值)的列,即使应用程序并不需要保存 NULL 也是如此,这是因为可为 NULL 是列的默认属性。通常情况下最好...
 特惠活动
特惠活动
 存储这些数据的最优方式是什么?-优选内容
存储这些数据的最优方式是什么?-优选内容
 存储这些数据的最优方式是什么?-相关内容
存储这些数据的最优方式是什么?-相关内容
火山引擎云存储选型指南 x 自动驾驶场景最佳实践
高性价比的存储平台。# 云存储产品选型方法论## 存储选型考量在选型之前,我们应该对业务应用进行场景化分析,比如要存储什么类型的数据、需要什么样的接口协议、对功能和性能有怎样的要求、业内是否有相关场景的最佳实践等等。以AI/ML场景举例,不同阶段的存储工作负载具有不同的特点(如下图...
表设计之数据类型优化 | 社区征文
## 1. 概述MySQL 支持的数据类型非常多,选择正确的数据类型对于获得高性能至关重要。不管存储哪种类型的数据,下面几个简单的原则都有助于做出更好的选择。## 2. 基本原则### 2.1 越小越好一般情况下,应该尽... 比如应该使用 MySQL 内建的类型而不是字符串来存储日期和时间。### 2.3 避免 NULL很多表都包含可为 NULL(空值)的列,即使应用程序并不需要保存 NULL 也是如此,这是因为可为 NULL 是列的默认属性。通常情况下最好...
干货|字节跳动在湖仓一体领域的最佳实践
> 数据湖的出现,为企业提供了一种更为灵活、更低成本的数据存储方式,同时也进一步普惠数据价值。然而,在企业数据湖的实践中,最主要的挑战不是构建数据湖,而是如何从数据湖的数据中获益。湖仓一体概念的提出,将用户... ```js火山引擎 湖仓一体分析服务 LAS(Lakehouse Analytics Service)是面向湖仓一体架构的Serverless 数据处理分析服务,提供字节跳动最佳实践的一站式 EB 级海量数据存储计算和交互分析能力,兼容 Spark、Presto、...
数据存储
数据存储支持查看火山引擎 E-MapReduce(EMR)Hive、湖仓一体分析服务 LAS 表存储资产明细情况,并提供公共规则及治理建议,可快速定位治理的主要侧重点,并提供治理操作/批量处理能力,协助治理负责人或治理实施者进行存... 下面为您介绍详细推荐优化项口径说明: 优化项 口径说明 优化建议 TTL 设置不合理 生命周期为未配置或永久保存,建议删除或者缩短 TTL。 根据近 90 天访问分区情况,建议删除或者缩短 TTL 为 7 天。 文件大小异...
9年演进史:字节跳动 10EB 级大数据存储实战
BookKeeper 在大规模多节点数据同步上表现得更稳定可靠)。Name Node 负责存储整个 HDFS 集群的元数据信息,是整个系统的大脑。一旦故障,整个集群都会陷入不可用状态。因此 Name Node 有一套基于 ZKFC 的主从热备的... 数据量继续增大,Federation 方式下的目录树管理也存在瓶颈,主要体现在数据量增大后,Java 版本的 GC 变得更加频繁,跨子树迁移节点代价过大,节点启动时间太长等问题。因此我们通过重构的方式,解决了 GC,锁优化,启动加...
DataLeap 数据资产实战:如何实现存储优化?
解决了数据生产者和消费者对于元数据和资产管理的各项核心需求。- Data Catalog 系统的存储层,依赖 Apache Atlas,传递依赖 JanusGraph。JanusGraph 的存储后端,通常是一个 Key-Column-Value 模型的系统,本文主要... 也就是说,数据存储由一系列行组成,每行都由一个键(key)唯一标识,每行由多个列值(column-value)对组成,也会对列进行排序和过滤,如果是非 column-family 的类型存储,则需要另行适配,适配时数据模型有两种方式:Key-Co...
免费公测|火山引擎大数据文件存储公测现已开启!
在云计算、人工智能、物联网等技术发展迅速的今天,海量数据的规模化增长成为常态。当前行业通用的存储方案也面临巨大挑战。而随着云原生的逐渐兴起,原有的存算一体架构越来越多地暴露出弊端:1. 计算资源和存储资... 数据强一致性保证。![]()## 客户案例火山引擎大数据文件存储脱胎于字节跳动内部超大规模业务最佳实践,实现了多种场景下的企业级功能增强,支持字节跳动多款产品核心场景的实现与优化。**案例一:抖音实...
免费公测|火山引擎大数据文件存储公测现已开启!
在云计算、人工智能、物联网等技术发展迅速的今天,海量数据的规模化增长成为常态。当前行业通用的存储方案也面临巨大挑战。而随着云原生的逐渐兴起,原有的存算一体架构越来越多地暴露出弊端: 1. 计算资源和... 多对象存储统一维护;* 完备的缓存策略提升机器学习场景下的 I/O 负载;* 数据强一致性保证。**客户案例**火山引擎大数据文件存储脱胎于字节跳动内部超大规模业务最佳实践,实现了多种场景下的...
火山引擎 Iceberg 数据湖的应用与实践
可以很好地应对这些挑战。本文将介绍火山引擎在云原生计算产品上使用 Iceberg 的实践,和大家分享高效查询、存储和治理 Iceberg 数据的方法。**相关产品**:https://www.volcengine.com/product/cfs 作者|火山... 最上层的 Catalog 也就是表的目录指向了每个表当前版本对应的 Metadata File,由于 Iceberg 使用 MVCC,所以每次对表的变更都会产生一个新版本的 Metadata File。这个 Metadata File 记录了 Schema 分区方式、快照列...
