k均值聚类中的聚类区域面积公式
 社区干货
社区干货
Katalyst 支持reclaimed 资源的 NUMA 粒度上报|社区征文
## 引言本文回顾了我个人参与 Katalyst 开源项目的机缘巧合、过程中的挑战,以及所获得的感悟。一方面,这是对我的经历的记录;另一方面,我希望这些分享能对开源新人,对 Katalyst 项目感兴趣的新入门者有所帮助。## 自我介绍我本科毕业于南昌大学计算机科学与技术专业,目前在浙江大学攻读硕士学位,是 SEL 实验室的一名研究生。我的主要研究方向是混部集群的调度策略。GitHub: 在开源方面,我曾对阿里的 Sealer 社区和 OpenYu...
AB实验背后的秘密:样本量计算 |社区征文
个体:总体中的一个元素 xi样本:一部分个体 Xi ## 3、统计量(工具)常见统计量:**(1)样本均值**反映出总体X数学期望。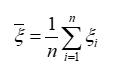**(2)样本方差**方差 是各数据偏离平均值 差值的平方和 的平均数。反映的是总体X方差。1. **系统的存储代价较高。** 要在OLTP和OLAP的系统各存一份同一内容但不同layout的数据,甚至中间传输的MQ也可能要持久化一份数据1. ... 还有一个**cluster的中心点(mean),也是一个query,实际上就是一个均值向量。**### Reorg的简单例子笔者在这里举个例子(非论文中的例子):- 表T = {a, b, c, d, e}- Query集合Q = {Q0, Q1, ... Q9}- K ...
干货 | A/B实验背后的秘密:样本量计算
=&rk3s=8031ce6d&x-expires=1715962850&x-signature=Oj3zZt6O0ZGBDwyEZBO2sPNQpCI%3D)**统计基础概念**研究对象总体X:研究问题某个数量指标。入手点个体:总体中的一个元素 xi样本:一部分个体 Xi统计量(工具) **(1)样本均值**反映出总体X数学期望。 特惠活动
特惠活动
 k均值聚类中的聚类区域面积公式-优选内容
k均值聚类中的聚类区域面积公式-优选内容
 k均值聚类中的聚类区域面积公式-相关内容
k均值聚类中的聚类区域面积公式-相关内容
[数据库论文研读] HTAP行列混存 & 智能转换
限制了系统的能力(例如会要求用户K分钟后才能在刚写入的数据上做查询分析)1. **系统的存储代价较高。** 要在OLTP和OLAP的系统各存一份同一内容但不同layout的数据,甚至中间传输的MQ也可能要持久化一份数据1. ... 还有一个**cluster的中心点(mean),也是一个query,实际上就是一个均值向量。**### Reorg的简单例子笔者在这里举个例子(非论文中的例子):- 表T = {a, b, c, d, e}- Query集合Q = {Q0, Q1, ... Q9}- K ...
干货 | A/B实验背后的秘密:样本量计算
=&rk3s=8031ce6d&x-expires=1715962850&x-signature=Oj3zZt6O0ZGBDwyEZBO2sPNQpCI%3D)**统计基础概念**研究对象总体X:研究问题某个数量指标。入手点个体:总体中的一个元素 xi样本:一部分个体 Xi统计量(工具) **(1)样本均值**反映出总体X数学期望。的限制,尤其是 gpt-3.5-turbo 模型,限制为 4K tokens(约3000字),这也就意味着GPT用户在与模型交互时最多只有3000字的内容来理解和推断。所以 ChatGPT 是不具备对话记忆功能... 中的表现。在机器学习任务中,我们通常使用向量表示数据,其中每个维度对应一个特征。Vector Embedding 这样的技术可以将特征映射到高维向量空间,以便更好地表示和处理数据。向量空间的概念也为相似性搜索、聚类等...
浅谈AI机器学习及实践总结 | 社区征文
(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/c63b1f1f9ba3459aabe711694fa7d106~tplv-k3u1fbpfcp-5.jpeg?)分类算法:逻辑回归、决策树分类、SVM分类、贝叶斯分类、随机森林、XGBoost、KNN...回归算法:线性回归、 决策树回归、SVN回归、贝叶斯回归...- 无监督学习:训练数据集没有标签,多应用在聚类、降维等有限的场景中,比如说为用户做分组画像,另外通常也会作为数据预处理的一个子步骤中。降维算法、聚类算法....
火山引擎DataTester:如何做A/B实验的假设检验
=&rk3s=8031ce6d&x-expires=1715962903&x-signature=a6fPECK0xChGciKXv7ff%2FH6WIh0%3D)对比上图,第一类错误指的是原假设正确但是我们做出了拒绝原假设的结论,这个错误在现实中常常表现为“我作出了统计显著的结... 阈值或置信区间包含0,则拒绝原假设;若p>0.05或统计量绝对值<=阈值或置信区间不包含0,则无法拒绝原假设。Note:有些其他的计算公式会假定两组的总体方差相等,在方差的计算方式上有区别,这类公式不推荐,因为该假设在...
观点 | 为什么在数据驱动的路上,AB实验值得信赖?(下)
[在连载的上中,我们介绍了AB实验与数据驱动的背景以及AB实验的基本架构](http://mp.weixin.qq.com/s?__biz=MzkwMzMwOTQwMg==&mid=2247490573&idx=1&sn=642397928815e58fc63b18a7dcba54bb&chksm=c0996d38f7eee42eaa... **总体参数的进行区间估计的样本均值范围**。一般来说,我们使用 95% 的置信水平来进行区间估计。置信区间可以辅助确定版本间是否有存在显著差异的可能性:* 如果置信区间上下限的值同为正或负,认为存在有显著...
工业大数据分析与应用——知识总结 | 社区征文
很大程度上改变中国高校信息技术相关专业的现有教学和科研体制### 1.4 典型大数据的应用略### 1.5 大数据关键技术* 数据采集:将**分布的、异构数据源**中的数据如关系数据、平面数据文件等,抽取到临时中间... * 网络接入存储(Network-Attached Storage, NAS) * 存储区域网络(Storage Area Network, SAN) * DAS/SAN/NAS组网示意图> DAS、NAS、SAN三种形态介绍与比较(最下面有比较表格)* DAS 直连式存储...
为什么在数据驱动的路上,AB 实验值得信赖?
> 在线 AB 实验成为当今互联网公司中必不可少的数据驱动的工具,很多公司把自己的应用来做一次 AB 实验作为数据驱动的试金石。