作业。归并排序,填写空白。
 社区干货
社区干货
基于 LoserTree 的 Paimon 多路归并优化
并将相同的 Key 使用 MergeFunction 进行合并,其中每个 RecordReader 的数据是有序的。整个读取过程实际上是对多个 RecordReader 的数据进行多路归并。在归并过程中,数据之间的比较次数越多,整体排序耗时越高。... 整体排序完成的时间复杂度为 O(nlogN);3)单次调整的时间复杂度为 O(logN),由于需要和两个子节点都进行比较,因此单次调整的比较次数为 2logN。**2.2 LoserTree**LoserTree 也是一种常用于归并排序算法中的数据...
基于 LoserTree 的 Paimon 多路归并优化
并将相同的 Key 使用 MergeFunction 进行合并,其中每个 RecordReader 的数据是有序的。整个读取过程实际上是对多个 RecordReader 的数据进行多路归并。在归并过程中,数据之间的比较次数越多,整体排序耗时越高。... LoserTree 也是一种常用于归并排序算法中的数据结构,它也是一棵完全二叉树。在这棵完全二叉树中,叶子节点代表待排序列,非叶子节点代表两个子节点中的败者。对于 Node0,代表全局 Winner。相比堆排序,LoserTree 可以...
精选文章|MySQL深分页优化
没有排序**把然后把排序后的数据写到临时文件。3. 将所有数据取出排序后,对所有临时文件按顺序做合并(归并排序)再写回到文件,直到最后所有文件合并完成。4. 从临时文件中读取满足...
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
批处理和流处理的结果会进行合并。** Lambda 架构的优势集中体现在职责边界明确、高容错性与复杂性隔离上,主要包含以下三方面: **●** **职责边界清晰** :流处理专注于增量数据计算,批... 会按照主键基于时间戳做排序后合并 Flush 成 Hudi 的 log file;对于非主键表,会按照 offset 有序进行 Flush;**●** WAL Log:Block 对应的持久化存储,在 Block 遭驱逐后可用作流式回溯;**●** 计算引擎中 T...
 特惠活动
特惠活动
 作业。归并排序,填写空白。-优选内容
作业。归并排序,填写空白。-优选内容
 作业。归并排序,填写空白。-相关内容
作业。归并排序,填写空白。-相关内容
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
批处理和流处理的结果会进行合并。** Lambda 架构的优势集中体现在职责边界明确、高容错性与复杂性隔离上,主要包含以下三方面: **●** **职责边界清晰** :流处理专注于增量数据计算,批... 会按照主键基于时间戳做排序后合并 Flush 成 Hudi 的 log file;对于非主键表,会按照 offset 有序进行 Flush;**●** WAL Log:Block 对应的持久化存储,在 Block 遭驱逐后可用作流式回溯;**●** 计算引擎中 T...
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
批处理和流处理的结果会进行合并。**Lambda 架构的优势集中体现在职责边界明确、高容错性与复杂性隔离上,主要包含以下三方面: **●** **职责边界清晰**:流处理专注于增量数据计算,批处理专注于全量数据计算... 会按照主键基于时间戳做排序后合并 Flush 成 Hudi 的 log file;对于非主键表,会按照 offset 有序进行 Flush; **●** WAL Log:Block 对应的持久化存储,在 Block 遭驱逐后可用作流式回溯; **●** 计算引擎中 Tas...
VikingDB:大规模云原生向量数据库的前沿实践与应用
基于向量的相关性排序和多样性打散等能力,以更好地满足 AI 原生应用程序多样的向量计算需求。另外,除了以向量为核心的基础能力之外,VIkingDB 从模型迭代,信息安全等角度或场景做了特性支持,以更好的产品形态或功... 然后把每个分片的结果合并在一起,只要有一个分片耗时较长,就会拖累整个索引的延迟。因此从延迟的角度,分片数在满足约束的前提下,应越小越好。为此,VikingDB 提供了自动分片的机制,通过综合考虑各种约束条件计算出最...
golang pprof
执行`top`命令可以可以看到占用量逆序排列的函数,如下。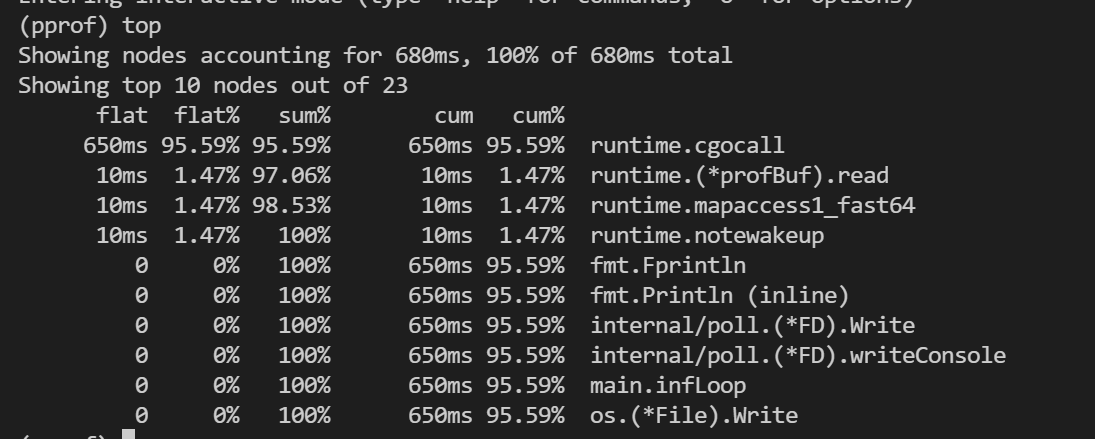可以看到总共有6列信息,这六... 而是将所有的函数调用栈合并后,按函数名字母顺序排列的。**火焰图就是看哪个函数占据的宽度最大。只要有"平顶",就表示该函数可能存在性能问题。**"平顶" 的意思是没有再次进行子函数调用,"平顶" 段越长,证明该...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
EMR 存算分离JobCommitter最佳实践
会调用CompleteUpload将多次UploadPart的数据排序合并,并写入到key中。 借助MPU能力,可以避免文件在写入过程中,尚未写完的文件被读取到,因此就不需要写临时目录,可以直接写最终目录,在Job Committer的流程下,MR作业的写入流程优化为:可见当有了Job Committer后,无需再写临时文件,直接写最终目录,当文件全部写完后,通过调用MPU的CompleteUpload让文件可见,减少原有的copy+delete,极大的提升了写入速度。 如下图所示,在常见的Hado...
最新动态(2024年前)
包含报告概览核心指标显著性去除60天最大限制和指标报告的实验版本排序优化 优化创建指标弹窗速度 2022年08月11日 V1.9.8版本 迭代说明: 数据管理优化:用户属性-预置属性支持更改状态,不包括:ab_version、app_pla... 调整上线公告的icon大小 修复指标事件空白hover + 创建漏斗提示虚拟事件被删除的问题 修复公共属性重复的问题 分流服务:更新组件版本 修复报告页同步转异步导致的埋点问题 2022年05月20日 V1.9.37版本 功能 【场...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
会有一些作业在后台对写入的数据进行更进一步的处理。ByteHouse 中主要包括如下 3 种后台任务。 - Merge:将不同的 parts 文件按 Primary Key 做排序合并成一个大的 part 文件。- Checkpoint: 对表的任意更新,例如元数据的改变,数据字典等异步构建操作会产生新的增量数据文件,这部分新产生的增量和原有的数据文件会在后台合并成一个新的数据文件。- GC:空间回收,当数据文件中的垃圾空间超过一定阈值后,会触发后台作...
离线数据同步
填写任务基本信息:任务名称:输入任务的名称,只允许字符.、字母、数字、下划线、连字符、[]、【】、()、()以及中文字符,且需要在127个字符以内。 保存至: 选择任务存放的目标文件夹目录。 单击确定按钮,完成任务... SQL -- 字段重排序: 源表有 a, b, c 三个字段,但下游目的表只有 c, b 两个字段SELECT c, b FROM Source-- 字段合并: 把源表的 first_name 字段和 last_name 字段用空格连接起来,并作为一个新的字段 full_nameSEL...
