数据仓库和Hbase的区别
 社区干货
社区干货
我的大数据学习总结 |社区征文
开始学习Linux命令和系统基本概念。然后分别学习Java、Python以及Scala这几种在大数据开发中常用的编程语言。然后着重学习Hadoop核心技术如HDFS和MapReduce;接触数据库Hive后,学习数据流技术Kafka和分布式协调服务Zookeeper。深入研究Yarn和求执行引擎Spark。此外还了解其他技术如HBase、Sqoop等。同时学习计算机网络知识和操作系统原理。后面再系统学习关系数据库MySQL和数据仓库理论。学习分布式原理和架构也很重要。这个学习...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数据仓库中的数据?- 怎么组织才能使得数据的使用最为方便和便捷?- 怎么组织才能使得数据仓库具有良好的可扩展性和可维护性?> **Ralph Kimball 维度建模理论很好地回答和解决了上述问题。**维度建模理论和技术也是...
Hive SQL 底层执行过程 | 社区征文
Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。Hive直接访问存储在 HDFS 中或者 HBase 中的文件,通过 MapReduce、Spark 或 Tez 执行... 在reduce阶段保存LastKey区分不同的key。MapReduce的过程如下: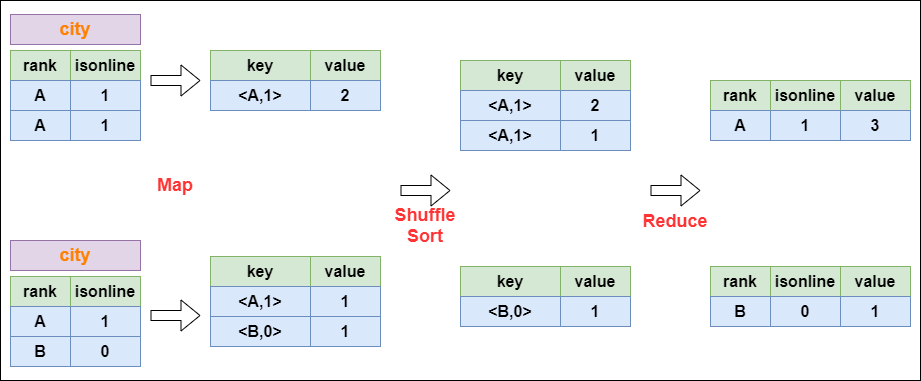#### 3. Distinct的实现原理以下面这个SQL为例,讲解 dist...
一文读懂火山引擎云数据库产品及选型
数据的存储与查询。从技术角度出发,数据库可以分为关系型数据库与 NoSQL 数据库。**从场景角度出发,数据库又可以分为 OLTP 数据库与 OLAP 数据库**。OLTP(Online trancaction processing),是关系型数据库的主要应用,侧重于交互式的事务处理,例如银行交易、在线订单处理等。OLAP(Online analytical processing) 是数据仓库系统的主要应用,支持复杂的分析操作,侧重分析决策支持,并且提供直观易懂的查询结果,主要跟大数据系统关系...
 特惠活动
特惠活动
 数据仓库和Hbase的区别-优选内容
数据仓库和Hbase的区别-优选内容
 数据仓库和Hbase的区别-相关内容
数据仓库和Hbase的区别-相关内容
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数据仓库中的数据?- 怎么组织才能使得数据的使用最为方便和便捷?- 怎么组织才能使得数据仓库具有良好的可扩展性和可维护性?> **Ralph Kimball 维度建模理论很好地回答和解决了上述问题。**维度建模理论和技术也是...
HBase
1. 概述 支持接入 HBase 去创建数据集。在连接数据之前,请收集以下信息: 数据库所在服务器的 IP 地址和端口号; 数据库的 rootdir 和 zk.znode.parent。 2. 快速入门 2.1 从数据连接新建(1)进入火山引擎,点击进入到某个具体项目下,点击数据准备,在下拉列表找到数据连接,点击数据连接。(2)在页面中选择 HBase。(3)填写所需的基本信息,并进行测试连接,连接成功后点击保存。(4)确认数据连接的基本信息无误后即完成数据连接。(5)可使...
Hive SQL 底层执行过程 | 社区征文
Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。Hive直接访问存储在 HDFS 中或者 HBase 中的文件,通过 MapReduce、Spark 或 Tez 执行... 在reduce阶段保存LastKey区分不同的key。MapReduce的过程如下:#### 3. Distinct的实现原理以下面这个SQL为例,讲解 dist...
一文读懂火山引擎云数据库产品及选型
数据的存储与查询。从技术角度出发,数据库可以分为关系型数据库与 NoSQL 数据库。**从场景角度出发,数据库又可以分为 OLTP 数据库与 OLAP 数据库**。OLTP(Online trancaction processing),是关系型数据库的主要应用,侧重于交互式的事务处理,例如银行交易、在线订单处理等。OLAP(Online analytical processing) 是数据仓库系统的主要应用,支持复杂的分析操作,侧重分析决策支持,并且提供直观易懂的查询结果,主要跟大数据系统关系...
ByConity 技术详解之 ELT
在数据流进时,针对一些需要出报表或者需要做大屏的数据直接内存中做聚合。聚合完成后,将结果写入HBase或MySQL中再去取数据,将数据取出后作展示。Flink还会去直接暴露中间状态的接口,即queryable state,让用户更好的使用状态数据。但是最后还会与批计算的结果完成对数,如果不一致,需要进行回查操作,整个过程考验运维/开发同学的功力。- **湖仓** **一体&HxxP**:将数据湖与数据仓库结合起来。## ELT in ByConity### 整体执行...
火山引擎DataLeap的Data Catalog系统公有云实践 (上)
Data Catalog公有云产品是基于火山引擎提供的数据引擎和云基础设施来部署和服务的,下面会简单介绍下我们所依赖和使用的产品和服务:- **数据引擎:** 是火山引擎提供的数据分析、数据仓库和数据湖相关产品,包括B... **数据库和中间件:** 是和业界主流云厂商对齐的存储和中间件领域的标准云服务,和公司内部对应组件也会有若干差异,Data Catalog为此也做了多版本的兼容。Data Catalog在元数据存储上使用到了Hbase/MySQL/ES/Red...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
基于HDFS/HBase的MPP SQL引擎,拥有和Hadoop一样的可扩展性、它提供了类SQL-类Hsql语法,在多用户场景下亦能拥有较高的响应速度和吞吐量,兼顾数据仓库,具有实时,批处理,多并发等优点。**Java接入:** 