jdbc链接hbase
 社区干货
社区干货
干货 | 看 SparkSQL 如何支撑企业级数仓
Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN 上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以... MapReduce 和 HBase,形成了早期 Hadoop 的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似 SQL 语法的分析入口,同时在编程态的支撑也不够友好,只有 Map 和 Reduce ...
观点|SparkSQL在企业级数仓建设的优势
Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式任务执行,以及元数据中心,... MapReduce和HBase,形成了早期Hadoop的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似SQL语法的分析入口,同时在编程态的支撑也不够友好,只有Map和Reduce两阶段,...
SparkSQL 在企业级数仓建设的优势
Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以及... MapReduce和HBase,形成了早期Hadoop的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似SQL语法的分析入口,同时在编程态的支撑也不够友好,只有Map和Reduce两阶段,严重...
一文读懂火山引擎云数据库产品及选型
宽列型NoSQL数据库(以HBase为代表)、时序型NoSQL数据库(以InfluxDB为代表)以及图NoSQL数据库(以Neo4j为代表)。虽然这些类型都属于NoSQL数据库范畴,但是不同类型的NoSQL数据库所适用的场景各有不同,需要根据业务特征... OLTP与OLAP系统之间通常会使用ETL进行连接。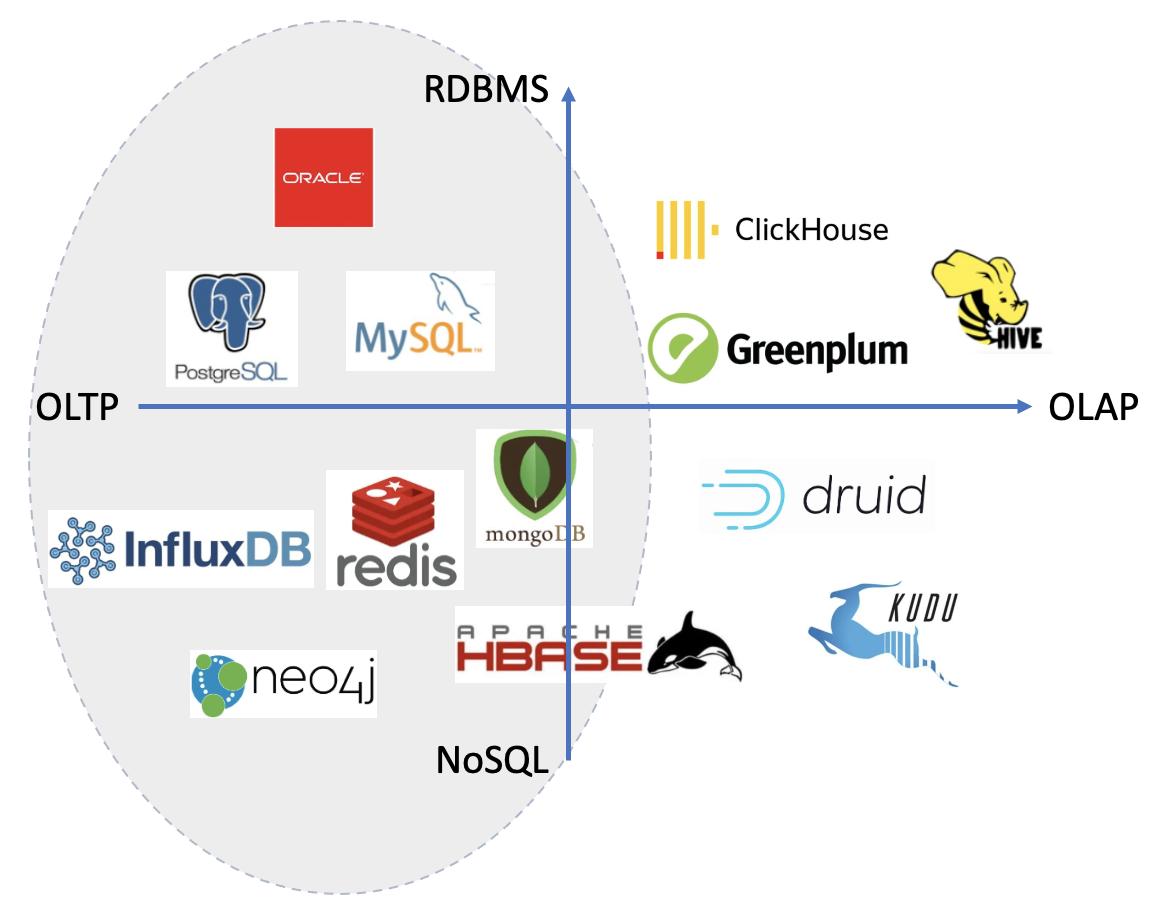本文主要侧重于OLTP系统的选型指南...
 特惠活动
特惠活动
 jdbc链接hbase-优选内容
jdbc链接hbase-优选内容
 jdbc链接hbase-相关内容
jdbc链接hbase-相关内容
连接地址介绍
本文介绍表格数据库 HBase 版支持的访问方式以及连接地址类型,您可以根据业务需要选择合适的连接地址来访问管理 HBase 实例。 访问方式HBase 提供了私网和公网访问方式,下表对比介绍了两种访问方式。 访问方式 说明 注意事项 私网访问 通过私网连接地址访问 HBase 实例可以最大限度地保障安全性和性能。 创建 HBase 实例时会默认提供一个可用于私网访问的 ZK 连接地址。 您也可以根据业务需要为 HBase 实例申请 Thrift2 连接地址...
JDBC
JDBC 连接器提供了对 MySQL、PostgreSQL 等常见的关系型数据库的读写能力,支持做数据源表、结果表和维表。 DDL 定义 用作数据源(Source)sql CREATE TABLE jdbc_source ( name String, score INT ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://192.*.*.*:3306/doc_db', 'table-name' = ' ', 'username' = 'admin', 'password' = 'Passord', 'scan.partition.column' = 'score...
HBase数据连接
1. 产品概述 支持HBase数据连接。 2. 使用限制 用户需具备 项目编辑 或 权限-按内容管理-模块-数据连接-新建连接 权限,才能新建数据连接。 3. 操作步骤 1.点击 数据融合 > 数据连接 。2.在数据连接目录左上角,点击 新建数据连接 按钮,选择 HBase 。 填写所需的基本信息,并进行 测试连接 。 注意 用户需将以下IP设置为出口白名单后,方可在Saas环境接入数据。180.184.64.81 连接成功后点击 保存 即可。
连接器列表
本文介绍流式计算 Flink 版支持的连接器和 Format。 支持的连接器下表列举了流式计算 Flink 版目前提供的连接器,以及各连接器支持的表类型。 连接器 描述 源表 结果表 维表 引擎版本 kafka 提供从 Kafka Topic 或 BMQ Topic 中消费和写入数据的能力。 ✅ ✅ ❌ Flink 1.11、Flink 1.16 upsert-kafka 提供以 upsert
JDBC
JAVA 应用可以通过 ClickHouse JDBC Driver 与 ClickHouse 进行交互。 前置准备系统安装有 Java 环境。 下载 ClickHouse 官方 JDBC 驱动: https://github.com/ClickHouse/clickhouse-java 。 注意 在使用 ByteHouse BitMap64 数据类型时,需要安装ByteHouse JDBC专用补丁,详见后文。 您可以参考获取集群连接信息来查看相关集群的连接信息。 连接 ByteHouse创建一个 HelloClickHouse.java,将以下代码贴入,即可连接 ByteHouse 并进...
HBase
1. 概述 支持接入 HBase 去创建数据集。在连接数据之前,请收集以下信息: 数据库所在服务器的 IP 地址和端口号; 数据库的 rootdir 和 zk.znode.parent。 2. 快速入门 2.1 从数据连接新建(1)进入火山引擎,点击进入到某个具体项目下,点击数据准备,在下拉列表找到数据连接,点击数据连接。(2)在页面中选择 HBase。(3)填写所需的基本信息,并进行测试连接,连接成功后点击保存。(4)确认数据连接的基本信息无误后即完成数据连接。(5)可使...
HBase
HBase 连接器提供了对分布式 HBase 数据库表的读写数据能力,支持做数据源表、结果表和维表。 使用限制Flink 目前提供了 HBase-1.4 和 HBase-2.2 两种连接器,请根据实际情况选择: 在 Flink 1.11-volcano 引擎版本中仅支持使用 HBase-1.4 连接器。 在 Flink 1.16-volcano 引擎版本中支持使用 HBase-1.4 和 HBase-2.2 两种连接器。 注意事项在公网环境中连接火山 HBase 时,您需要添加以下两个参数: 'properties.zookeeper.znode.me...
功能概览
本文汇总了表格数据库 HBase 版实例支持的功能。 类别 功能 实例管理 变更实例配置 冷热分离 重启实例 修改实例参数 删除或退订实例 实例删除保护 标签管理 连接管理 申请 Thrift2 连接地址 释放 Thrift2 连接地址 开启公网访问 关闭公网访问 使用 Java API 连接实例 使用 HBase Shell 连接实例 监控告警 查看监控数据 设置告警 白名单管理 创建白名单 编辑白名单 绑定实例和白名单 解绑实例和白名单 删除白名单 ...
干货 | 看 SparkSQL 如何支撑企业级数仓
Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN 上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以... MapReduce 和 HBase,形成了早期 Hadoop 的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似 SQL 语法的分析入口,同时在编程态的支撑也不够友好,只有 Map 和 Reduce ...
