U-Net,损失函数在某一点后不再减少。
 社区干货
社区干货
使用pytorch自己构建网络模型总结|社区征文
当然这里的损失函数和优化器可以和我不同,感兴趣的也可以改变这些来看看我们最后训练的效果会不会发生变化【我测试了几个,对于本例效果差别不大】```python#5、设置损失函数、优化器#损失函数loss_fun = nn.CrossEntropyLoss() #交叉熵loss_fun = loss_fun.to(device)#优化器learning_rate = 1e-2optimizer = torch.optim.SGD(net.parameters(), learning_rate) #SGD:梯度下降算法``` ## 6、设置网络训练中...
【MindStudio训练营第一季】基于U-Net网络的图像分割的MindStudio实践
# 前情说明本作业基于Windows版MindStudio 5.0.RC3,远程连接ECS服务器使用,ECS是基于官方分享的CANN6.0.RC1_MindX_Vision3.0.RC3镜像创建的。# 基于ECS(Ascend310)的U-Net网络的图像分割## 1. U-Net网络介绍... np.save("softmax_result.npy", softmax_res) return softmax_res # ndarray# 自定义dice系数和iou函数def _calculate_accuracy(infer_image, mask_image): mask_image = cv2.resize(mask_image,...
在线学习FTRL介绍及基于Flink实现在线学习流程|社区征文
因此可以处理大数据量训练和在线训练。常用的有在线梯度下降(OGD)和随机梯度下降(SGD)等,Online Learning的优化目标是使得整体的损失函数最小化,它需要快速求解目标函数的最优解。现在做在线学习和CTR常常会用到逻辑回归( Logistic Regression),google先后三年时间(2010年-2013年)从理论研究到实际工程化实现的FTRL(Follow-the-regularized-Leader)算法,在处理诸如逻辑回归之类的带非光滑正则化项(例如1范数,做模型复杂度控制和...
【MindStudio训练营第一季】基于MindX的U-Net网络的工业质检实践作业
采用MindSpore深度学习框架构建U-Net网络,在华为云平台的ModelArts上创建基于昇腾910处理器的训练环境,启动训练并得到图像分割的模型;之后在华为云平台的ECS弹性云服务器上创建基于昇腾310处理器的推理环境,将该模... ue表示训练过程中同时进行验证。训练日志:```============== Starting Training ==============img shape: (1800, 1800, 3) mask shape (1800, 1800)step: 1, loss is 2.0795505, fps is 0.0158740409168...
 特惠活动
特惠活动
 U-Net,损失函数在某一点后不再减少。-优选内容
U-Net,损失函数在某一点后不再减少。-优选内容
 U-Net,损失函数在某一点后不再减少。-相关内容
U-Net,损失函数在某一点后不再减少。-相关内容
人工智能之自然语言处理技术总结与展望| 社区征文
选择平滑指的是结合不同类型的损失函数从而达到更好的效果。举例来说,同时结合使用交叉熵和二元交叉熵作为损失函数,从而使得模型学习不同颗粒度的特征;数据增强指的是增加了翻译后的数据(DRCD和SQuAD)、其他数据集... 而常用的finetune范式和它并不一致。而Prompt Learning解决了预训练与测试阶段中的差异。经过研究表明,Prompt Learning在小样本(few-shot)场景下很有效。 值得一提的是,清华大学的几位学者提出了用于**细粒度...
万字长文带你弄透Transformer原理|社区征文
就像是15年的resnet,不管是物体分类,目标检测还是语义分割的榜单前几名基本都是用VIT实现的!!!朋友,相信你点进来了也是了解了VIT的强大,想一睹VIT的风采。🌼🌼🌼正如我的标题所说,作为一名CV程序员,没有接触过NLP(... 这里有一点我需要说明,如果你看attention的论文或者一些文章解读,在经过softmax层前会除了一个$\sqrt {{{\rm{d}}_k}}$,起到了一个归一化的作用,我这里没有除, 因为后面代码举例时不除这个$\sqrt {{{\rm{d}}_...
万字长文带你漫游数据结构世界|社区征文
可以减少很多复杂的电路,以及各种符号转换的开销,计算也更加高效。我们可以看到,下面负数参加运算的结果也是符合补码的规则的:```txt 00100011 35 + 11011101 -35----------------------... 红黑树的算法简单一点。## 栈栈是一种数据结构,在`Java`里面体现是`Stack`类。它的本质是**先进后出**,就像是一个桶,只能不断的放在上面,取出来的时候,也只能不断的取出最上面的数据。要想取出底层的数据,只有...
浅谈AI机器学习及实践总结 | 社区征文
# 机器学习基础## 什么是机器学习机器学习是一种从数据生成规则、发现模型,来帮助我们预测、判断、分组和解决问题的技术。(机器学习是一种从数据中生产函数,而不是程序员直接编写函数的技术)说起函数就涉及到... 这些现象可以启发产品运营同学可以聚焦某个环节 去减少某个流程中的流失率# 机器学习工程实践的五个步骤## 定义问题需要我们剖析业务场景,设定清晰的目标,明确当前问题属于哪一种机器学习类型。场景:比如一...
干货|8000字长文,深度介绍Flink在字节跳动数据流的实践
**第一点**,**流量大,任务规模大**。- **第二点**,处在所有产品数据链路最上游,下游业务多,**ETL需求变化频繁**。- **第三点**,**高SLA**要求,下游推荐、实时数仓等业务对稳定性和时效性有比较高的要求。... 这样就减少了不必要的反序列化开销,同时降低了MQ集群带宽扇出比例。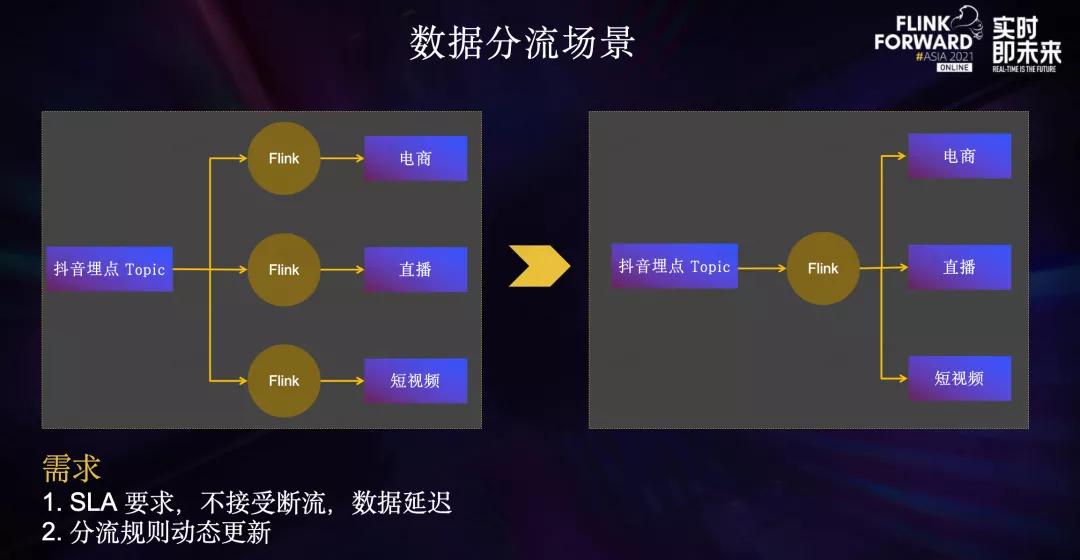在数据分流...
AI ASIC 的基准测试、优化和生态系统协作的整合|KubeCon China
TPC 也添加了 AI 负载常见的激活函数,作为特殊指令来支持 AI 负载。比如直接提供了 sigmoid、gelu 等。 **0****2** **为什么要做 ByteMlPerf?**回答这个问题之前,我们要先回答... 其实没有提到一点,就是已经有了 MLPerf,为什么还要另起炉灶,做一套 ByteMlPerf 呢?简单来说,这是因为 MLPerf 很难满足业务实际评估需求。这里可以简单做些对比:首先,评估的视角不一样,ByteMlPerf 是纯粹从用户的...
大象在云端起舞:后 Hadoop 时代的字节跳动云原生计算平台
这套系统很重要的一点是“一出生就是长在开源上,不管演进多少年,这套开源的协议始终不变。无论是 HDFS、Kafka、YARN,还是 Spark、Flink,都承载着巨大的用户体量。这套协议有时候可能没有那么好,没那么规范,但是我们... 带来精度上的损失。所以流式数据仅仅是作为参考,还是需要去以“天”级别重新跑一次历史数据,得到生产上的唯一的真实的结果。目前字节跳动的 Flink 批处理功能使用场景还处于相对较少的阶段。在一些标准的、基于...
Fastbot 开源版技术原理与架构
为了实现这一点,关键步骤是决定在当前 GUI 页面上选择哪个 UI 事件,可以快速地提高 Activity 覆盖率。具体而言,给定一个 GUI 页面,Fastbot 提取当前所有可用的超事件,并采用以下两种策略协同组合去选择执行的事件:... Fastbot 采用了 Sarsa N-Step 算法作为奖励函数去计算和更新 Q 值。(Microservices Engine)在全链路灰度发布场景的实践探索,介绍全链路灰度发布场景实践方法、方案设计思... 函数服务、服务网格、持续交付、可观测服务等。[