重现LightGBM的自定义回归损失函数
 社区干货
社区干货
人工智能之自然语言处理技术总结与展望| 社区征文
选择平滑指的是结合不同类型的损失函数从而达到更好的效果。举例来说,同时结合使用交叉熵和二元交叉熵作为损失函数,从而使得模型学习不同颗粒度的特征;数据增强指的是增加了翻译后的数据(DRCD和SQuAD)、其他数据集... 甚至被称为自然语言处理的第四范式。那么它究竟是什么样的呢? 由于维基百科并没有给出权威的定义,那么通过查阅文献得到它的定义。在论文[Prefix-Tuning: Optimizing Continuous Prompts for Generation](http...
保姆级人工智能学习成长路径|社区征文
LightGBM、CatBoost)、NLP常用库(jieba:中文分词、nltk:英文文本处理、Gensim:获取词向量、CountVectorizer:获取n-gram表示)。 对于新手来说,学习过程中最重要的是不断重复学习,但需要注意的是单纯的重复是没... 逻辑回归- 支持向量机- 提升树- 隐马尔科夫- 条件随机场- 其他模型 作为一名老司机,先介绍初学者最容易犯的误区,仅仅关注于**学习机器学习模型**,而**忽略了对机器学习核心概念和核心思想...
使用pytorch自己构建网络模型总结|社区征文
设置损失函数、优化器 设置损失函数、优化器这些都是神经网络的一些基础知识,不知道的自行补充。当然这里的损失函数和优化器可以和我不同,感兴趣的也可以改变这些来看看我们最后训练的效果会不会发生变化【我测试了几个,对于本例效果差别不大】```python#5、设置损失函数、优化器#损失函数loss_fun = nn.CrossEntropyLoss() #交叉熵loss_fun = loss_fun.to(device)#优化器learning_rate = 1e-2optimizer = t...
浅谈AI机器学习及实践总结 | 社区征文
分组和解决问题的技术。(机器学习是一种从数据中生产函数,而不是程序员直接编写函数的技术)说起函数就涉及到自变量和因变量,在机器学习中,把自变量叫做特征(feature)多个自变量分别可以定义为X1,X2..Xn,因变量叫... 根据标签的特点 监督学习可以分为两类问题:回归和分类,回归问题的标签是连续的数值,比如预测房价、股市等,分类问题的标签是离散的数值,比如人脸识别、判断是否正确等,判断两款运营策略哪种更有效。![image.png]...
 特惠活动
特惠活动
 重现LightGBM的自定义回归损失函数-优选内容
重现LightGBM的自定义回归损失函数-优选内容
 重现LightGBM的自定义回归损失函数-相关内容
重现LightGBM的自定义回归损失函数-相关内容
VikingDB:大规模云原生向量数据库的前沿实践与应用
而向量数据库又是以 embedding 作为核心概念,并围绕其提供存储检索能力的基础软件,因此可以说 **向量数据库是 AI 原生应用程序的基础设施** 。为了更好地胜任 AI 基础设施的角色和贴合大模型的生态,VikingDB ... 不考虑量化损失的话,精度为 100%,但检索耗时会随着数据量线性增长,因此在数据规模比较大的场景,延迟会严重劣化。* **IVF**:预先对全量数据进行聚类,检索时会遍历最相关的聚类簇。剪枝程度中等,精度和延迟也相对处...
边缘计算技术:深度学习与人工智能的融合|社区征文
# 前言“边缘”二字说的是边缘节点。这是一个网络概念,边缘节点是指那些离用户很近的、不在主干网络上的节点。用户在访问网络中的信息时,请求会先到达边缘节点,然后由边缘节点逐步转发到核心节点上。CDN部署的CDN... # 定义一个简单的深度学习模型 class SimpleModel(nn.Module): def __init__(self): super(SimpleModel, self).__init__() self.fc = nn.Linear(10, 1) def forward...
在线学习FTRL介绍及基于Flink实现在线学习流程|社区征文
Online Learning的优化目标是使得整体的损失函数最小化,它需要快速求解目标函数的最优解。现在做在线学习和CTR常常会用到逻辑回归( Logistic Regression),google先后三年时间(2010年-2013年)从理论研究到实际工程... 代理损失函数需要满足以下条件:1. 代理损失函数比较容易求解,最好是有解析解。1. 代理损失函数求得的解,和原函数的解的差距越小越好为了衡量条件2中的两个解的差距,引入regret的概念。如果一个在线学习算法...
探索大模型知识库:技术学习与个人成长分享 | 社区征文
训练方式为自回归语言模型,预训练主要任务为预测下一个单词。optimizer = optim.Adam(model.parameters(), lr=1e-5)# 定义训练循环def train(model, data_loader, criterion, optimizer): model.train() tota...
Kubernetes 生态,从繁荣走向碎片化 | 社区征文
通过 **CRD** 扩展 Kubernetes 用户自定义资源。(2) 通过 **Operators** 实现 Kubernetes 应用生命周期管理。Kubernetes **可扩展性架构及 CNCF 开放式生态发展方向**,在**高速发展期**,**野蛮生长期乃至普及... 通过函数直接调用;**cri-o** 是通过 linux 命令方式调用 runc 二进制文件,在性能上 containerd 更具优势,但是 **cri-o** 集成方式更为合理优雅,比较推荐 **cri-o**。**runc 与 runv:** runc 创建的容器进程,直接...
基于火山引擎微服务引擎 MSE 的全链路灰度落地实践
降低发布变更失败业务损失。本文结合火山引擎[微服务引擎 MSE](https://www.volcengine.com/product/mse)(Microservices Engine)在全链路灰度发布场景的实践探索,介绍全链路灰度发布场景实践方法、方案设计思... **提供流量逻辑隔离概念泳道**。泳道涉及服务实例染色标记、流量匹配规则及发布依赖关联的一组服务。泳道内的服务实例仅接受染色标记流量,并优先将染色流量路由至下游匹配染色标记的目标实例;每个泳道流量相互独立...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
主要包括掩码损失函数与用于预测上下句之间是否有逻辑关系的损失函数。在基于预训练bert模型的基础上,我们可以针对特定场景fine-tune模型,比如文本分类,自然语言推理,文本序列标注,其模型结构如图三所示。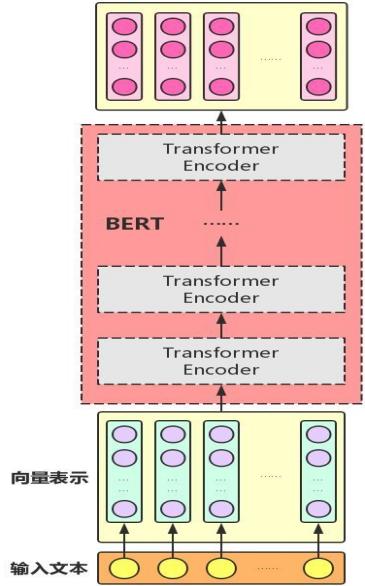 图三 本文实践基于追一科技在天池发布的开源中文比赛数据集,并应用科学空间博主苏剑林发表的...
应用性能前端监控,字节跳动这些年经验都在这了
糟糕的性能会让您的站点损失用户数、转化率和口碑。**错误监控则能够让开发者第一时间发现并修复问题**,单靠用户遇到问题并反馈是不现实的,当用户遇到白屏或者接口错误时,更多的人可能会重试几次、失去耐心然后直接... 性能以及自定义埋点的 APM 服务。基于海量数据的聚合分析,平台可帮助客户发现多类异常问题,并及时报警,做分配处理,同时平台提供了丰富的归因能力,包括且不限于异常分析、多维分析、自定义上报、单点日志查询等,结...
GPU推理服务性能优化之路
CUDA的Kernel函数既可以运行在主机端,也可以运行在设备端。同时主机端与设备端之间可以进行数据拷贝。CUDA Kernel函数:是数据并行处理函数(核函数),在GPU上执行时,一个Kernel对应一个Grid,基于GPU逻辑架构分发成... 对精度损失可以接受误差在0.001(误差定义:median,atol,rtol)范围内。因此我们对该推理服务进行了三项性能优化:a.使用我们提供的GPU与CPU分离的统一框架进行改造。b.对模型转ONNX后,转TensorRT。c.开启FP16模...
