关系型数据导入hbase
 社区干货
社区干货
分布式数据库TiDB的设计和架构
能很好的解决复杂的数据运算及表间处理,多用于银行、电信等传统行业复杂业务逻辑场景中,以 Oracle 为代表。此类数据库挑战在于成本高,随着数据量增加,只能通过购买更贵更好的服务器;无法线性扩容,海量数据下处理能力大幅下降。**2008年至2013年**2008年至2013年,随着搜索/社交的发展,数据量爆发增长,传统数据库高成本,无法线性扩容问题日益突显;分布式及分布式非关系型(NoSQL)开始快速发展,如 MongoDB,HBase。但此类数据库的...
字节跳动 NoSQL 的探索与实践
我们知道关系型数据库强调 CAP 理论:Consistency,Availability 和 Partition Tolerance,这三者不可兼得。谈到 NoSQL,我们会引入 BASE 概念:- **Basically Available**:分布式系统在出现故障时允许损失部分可用... HBase、MongoDB 和 InfluxDB。此外自研的平台上提供了 ByteGraph 和 ABase,这两者和字节跳动的业务息息相关,也是内部业务重度依赖的两大产品。## 字节跳动 NoSQL 的最新实践字节跳动的大部分业务数据可归纳为以...
字节跳动 NoSQL 的探索与实践
火山引擎存储&数据库解决方案负责人**## NoSQL 应用的现状什么是 NoSQL?我们知道关系型数据库强调 CAP 理论:Consistency,Availability 和 Partition Tolerance,这三者不可兼得。谈到 NoSQL,我们会引入 BASE 概... 允许数据在一段时间内不一致,但最终要达到一致。NoSQL 大致可以分为以下几类:- KV 类:以 Redis 为代表;- 文档型:以 MongoDB 为代表;- 列存:以 HBase 为代表;- 图、时序等新兴的数据库也都属于 NoSQL 范畴。...
Flink on K8s 企业生产化实践|社区征文
# 背景为了解决公司模型&特征迭代的系统性问题,提升算法开发与迭代效率,部门立项了特征平台项目。特征平台旨在解决数据存储分散、口径重复、提取复杂、链路过长等问题,在大数据与算法间架起科学桥梁,提供强有力的样本及特征数据支撑。平台从 Hive 、Hbase 、关系型数据库等大数据 ODS ( Operational Data store ) 层进行快速的数据 ETL ,将数据抽取到特征平台进行管理,并统一了数据出口,供数据科学家、数据工程师、机器学习工程...
 特惠活动
特惠活动
 关系型数据导入hbase-优选内容
关系型数据导入hbase-优选内容
 关系型数据导入hbase-相关内容
关系型数据导入hbase-相关内容
字节跳动 NoSQL 的探索与实践
火山引擎存储&数据库解决方案负责人**## NoSQL 应用的现状什么是 NoSQL?我们知道关系型数据库强调 CAP 理论:Consistency,Availability 和 Partition Tolerance,这三者不可兼得。谈到 NoSQL,我们会引入 BASE 概... 允许数据在一段时间内不一致,但最终要达到一致。NoSQL 大致可以分为以下几类:- KV 类:以 Redis 为代表;- 文档型:以 MongoDB 为代表;- 列存:以 HBase 为代表;- 图、时序等新兴的数据库也都属于 NoSQL 范畴。...
Flink on K8s 企业生产化实践|社区征文
# 背景为了解决公司模型&特征迭代的系统性问题,提升算法开发与迭代效率,部门立项了特征平台项目。特征平台旨在解决数据存储分散、口径重复、提取复杂、链路过长等问题,在大数据与算法间架起科学桥梁,提供强有力的样本及特征数据支撑。平台从 Hive 、Hbase 、关系型数据库等大数据 ODS ( Operational Data store ) 层进行快速的数据 ETL ,将数据抽取到特征平台进行管理,并统一了数据出口,供数据科学家、数据工程师、机器学习工程...
分布式数据库TiDB的设计和架构
能很好的解决复杂的数据运算及表间处理,多用于银行、电信等传统行业复杂业务逻辑场景中,以 Oracle 为代表。此类数据库挑战在于成本高,随着数据量增加,只能通过购买更贵更好的服务器;无法线性扩容,海量数据下处理能力大幅下降。 **2008年至2013年**2008年至2013年,随着搜索/社交的发展,数据量爆发增长,传统数据库高成本,无法线性扩容问题日益突显;分布式及分布式非关系型(NoSQL)开始快速发展,如 MongoDB,HBase。但此类数据库...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
通常用于进行离线数据处理操作-MapReduce,支持多种不同的执行引擎-Hive on MapReduce、Hive on Tez、Hive on Spark.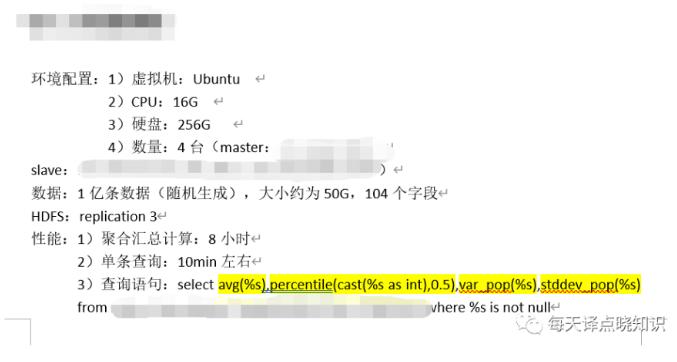**HBase:** 分布式、面向列开源数据库,不同于一般的关系型数据库,HBase基于列的而不是基于行的模式。、文档型 NoSQL 数据库(以 MongoDB 为代表)、宽列型 NoSQL 数据库(以 HBase ...
20000字详解大厂实时数仓建设 | 社区征文
明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要包括订单相关的 binlog 日志,冒泡和安全相关的 public 日志,流量相关的埋点日志等。这些数据部分已采集写入 kafka 或 ddmq 等数据通道中,部分数据需要借助内部...
火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群# 关键技术构建一个好的Data Catalog系统,需要考虑的核心产品设计和技术设计有很多。篇幅所限,本文只概要介绍技术设计中... 将差异的metadata写入Ingestion Service。概念上对齐Flink的sink operator。- **Bridge Job**:组装pipeline,做运行时控制。概念上对齐Flink的Job。当需要接入新的元数据时,通常只需要重新编写Source和Diff Op...
火山引擎上云迁移指南(一):上云迁移背景与流程
模式将数据资产从本地转移到云基础架构,尤其适用于大规模迁移。 || 更换平台 | 高 | 也称为 “修补后迁移”,在不改变应用核心架构的基础上,对应用程序做些简单的云优化。例如将关系型数据库替换成云服务商提供的数... 缓存数据库Redis版 | 火山引擎DTS || ^^ | PostgreSQL | 云数据库PostgreSQL版 | 火山引擎DTS || ^^ | MongoDB | 文档数据库MongoDB版 | 火山引擎DTS || ^^ | HBase | 表格数据库HBase版 | 火山引擎DTS |###...
