假阳性和假阴性
 社区干货
社区干货
干货 | A/B实验背后的秘密:样本量计算
可能会造成“假阳性”的实验结论等问题。那么样本太大带来的问题是什么呢?首先我们需要知道样本并不是总体,我们通过样本来替代样本太大会造成实验成本增加,以及产品本身的试错成本等。那么问题来了: **如何确定一个“最小”的样本数量,在保证实验“可靠性”的同时,不会浪费过多流量?**最小样本公式统计学里有最小样本量计算的公式: 特惠活动
特惠活动
 假阳性和假阴性-优选内容
假阳性和假阴性-优选内容
 假阳性和假阴性-相关内容
假阳性和假阴性-相关内容
干货|Hudi Bucket Index 在字节跳动的设计与实践
团队发现定位缓慢的问题来自 Bloom Filter Index 的假阳性。**当 Bloom Filter 发生假阳性时, Hudi 需要确定该 Record Key 是否真的存在**。这个操作需要读取文件里的实际数据一条一条做对比,而实际数据量规模很大,这会导致查询 Record Key 跟 File ID 的映射关系代价非常大,因此造成了索引的性能下滑。- 团队也调研了 Hudi 的另外一种索引方式 Hbase Index。这是一种 HBase 外置存储系统索引。但由于业务方不希望引入 HBase ...
干货 | 实时数据湖在字节跳动的实践
根本原因是Bloom Filter存在假阳性,一旦命中假阳性的case,我们就需要把整个文件组中的主键链读取上来,再进一步地去判断这个数据是否已经存在。通过这种方式来区分这个到底是 update 还是 insert。upsert本身就是update和insert两个操作的结合,如果发现相同组件数据不存在,就进行insert。如果存在,我们就进行 update。而 Bloom Filter由于假阳性的存在,只能加速数据的insert而没有办法去加速update。这就和我们观察到的现象很一致...
Hudi Bucket Index 在字节跳动的设计与实践
团队发现定位缓慢的问题来自 Bloom Filter Index 的假阳性。**当 Bloom Filter 发生假阳性时, Hudi 需要确定该 Record Key 是否真的存在**。这个操作需要读取文件里的实际数据一条一条做对比,而实际数据量规模很大,这会导致查询 Record Key 跟 File ID 的映射关系代价非常大,因此造成了索引的性能下滑。- 团队也调研了 Hudi 的另外一种索引方式 Hbase Index。这是一种 HBase 外置存储系统索引。但由于业务方不希望引入 HBase ...
AB实验背后的秘密:样本量计算 |社区征文
可能会造成“假阳性”的实验结论等问题。 那么样本太大带来的问题是什么呢?首先我们需要知道样本并不是总体,我们通过样本来替代样本太大会造成实验成本增加,以及产品本身的试错成本等。 那么问题来了:**如何确定一个“最小”的样本数量,在保证实验“可靠性”的同时,不会浪费过多流量?** ## 2、最小样本公式统计学里有最小样本量计算的公式:**Bucket Index 是一种基于哈希的...
干货 | 实时数据湖在字节跳动的实践
根本原因是 Bloom Filter 存在假阳性,一旦命中假阳性的 case,我们就需要把整个文件组中的主键链读取上来,再进一步地去判断这个数据是否已经存在。通过这种方式来区分这个到底是 update 还是 insert。upsert 本身就是 update 和 insert 两个操作的结合,如果发现相同组件数据不存在,就进行insert。如果存在,我们就进行 update。而 Bloom Filter 由于假阳性的存在,只能加速数据的insert 而没有办法去加速 update。这就和我们观察到的...
对不起,你做的A/B实验都是错的——火山引擎DataTester科普
这种情况被称为假阳性。 #### 6.实验不显著就不停止实验- A/B实验中,无论A策略与B策略多么相像,他们终归是不一样的。理论上来说,只要样本足够多(比如无穷多时),实验组和对照组策略的任何一点差异都会致使实验结果形成统计显著。- 我们在实验中,应该遵从实验设计,如果实验已经在预期运行周期内达到所需的样本量,但目标指标变化仍然不显著,那这个实验没有必要继续运行了,停止实验换个方向继续尝试。 #### 7.以为...
字节跳动基于 Apache Hudi 构建实时数仓的实践
**Q7:为何会使用Bucket Index?**A7:在使用Bucket Index前我们使用的是Bloom Filter Index,布隆过滤器在小数据量场景使用是没有问题的,但在百TB级别的数据下会有突出的假阳性的问题,当数据不存在的时候会扫描很多非必须的文件造成资源浪费。通过Bucket Index 我们可以直接通过hash值的计算能更加快速的定位数据所在的文件。 ```js火山引擎 湖仓一体分析服务 LAS(Lakehouse Analytics Service)是面向湖仓一体架构的Serverless ...
揭秘|字节跳动基于Hudi的实时数据湖平台
假阳性的问题会导致查询效率变差,而 Hbase Index 会引入额外的外部系统,从而提升运维代价。因此,我们希望能有一个**轻量且高效**的索引方式。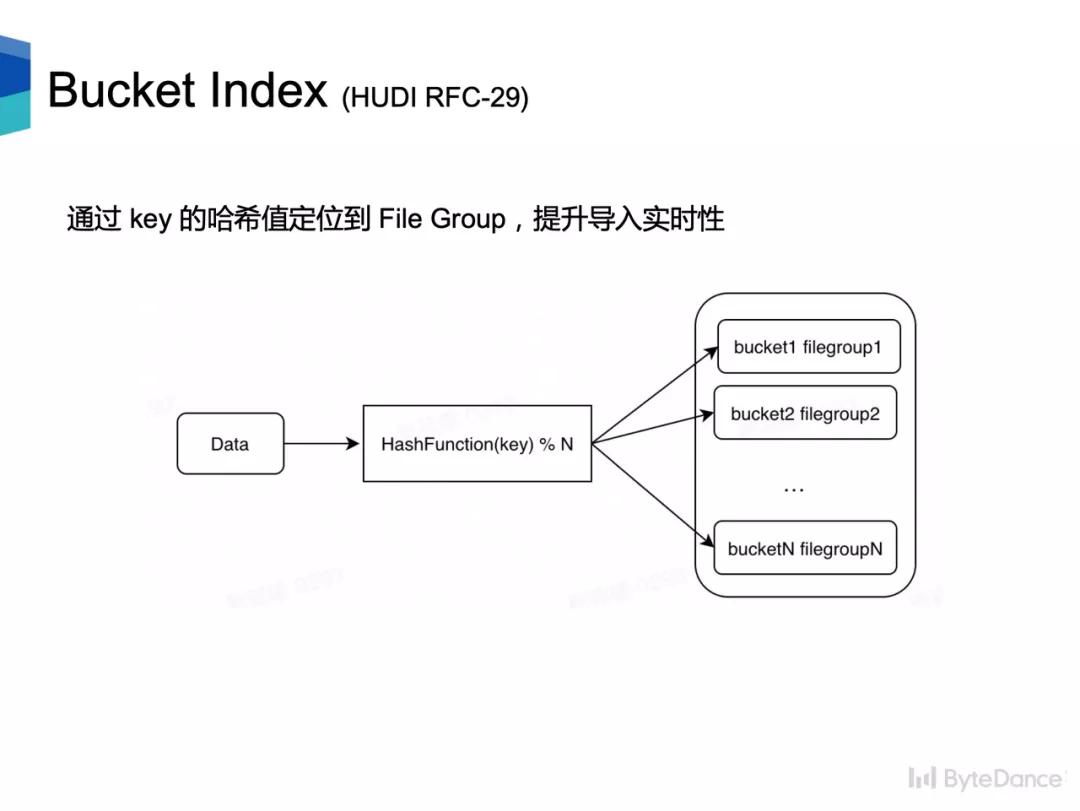**Bucket Index 是一种基于哈希的索引。** 每个分区被分成 N 个桶,每个桶对应一个 file group。对于更新数据,对更新数据的主键计算哈希,再对分桶数取模...
