java数据库缓存数据同步
 社区干货
社区干货
阿里巴巴的 Java 开发手册(黄山版)来了
## 0. 阅读完本文你将会学会- 写出更优雅高效的Java代码## 1. 前言周六逛B乎的时候正好刷到这样一个问题 **"Java开发手册(黄山版)怎么样?"**,我仔细一看这不是孤尽老师的著作吗?居然已经更新到了黄山版。上次... // 反例: 开发者 A 定义了缓存的 key。 String key = "Id#taobao_" + tradeId; cache.put(key, value); // 开发者 B 使用缓存时直接复制少了下划线,// 即 key 是"Id#taobao" + tradeId,导致出现故障。 String...
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
代码只与缓存交互,由缓存组件来管理自身与数据库之间的数据同步。**### 2.3 Write-Through 同步直写**与 Read-Through 类似,发生写请求时,Write-Through 将写入责任转移到缓存系统,由缓存抽象层来完成缓存数据和数据库数据的更新**,时序流程图如下: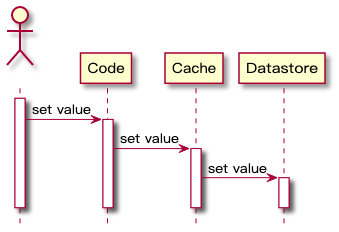`Write-Through` 的主要好处是应用系统的不需要考虑故障处理和重试逻辑,交给缓...
2022技术盘点之平台云原生架构演进之道|社区征文
数据库有MongoDB分片集群/MySQL/Redis/ElasticSearch/RabbitMQ进行各类业务数据计算和存储## 三 流量管控... 数据缓存等,框架网关如Netflix Zuul、Spring Cloud Gateway,云原生网关:Ingress-Treafik/Nginx/APISIX,Kong,Istio,Linked等。由于部分认证鉴权使用Spring Cloud Gateway完成,因此配合云上LB进行流量接入。.
 特惠活动
特惠活动
 java数据库缓存数据同步-优选内容
java数据库缓存数据同步-优选内容
 java数据库缓存数据同步-相关内容
java数据库缓存数据同步-相关内容
达梦数据库数据迁移+数据同步DMHS方案,与传统DBMS数据库Oracle、Mysql有何异曲同工?
达梦数据库数据迁移+数据同步DMHS方案,Mysql数据同步结合canal组件(canal-binlog日志).
EMR-3.9.0发布说明
环境信息版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 系统环境应用程序版本 Hadoop集群 Flink集群 Kafka集群 Pulsar集群 Presto集群 Trino集群 HBase集群 ... 支持按路径配置是否缓存,优化读吞吐,优化Meta RPC执行效率; 组件版本下面列出了 EMR 和此版本一起安装的组件。 组件 版本 描述 zookeeper_server 3.7.0 用于维护配置信息、命名、提供分布式同步的集中式服务。 zo...
EMR-3.0.0版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop集群 Flink集群 Kafka集群 Presto集群 Trino集群 HBase集群 OpenSearch集... 仍然可以通过对应组件的 Public History Server 页面查看组件执行完成的作业运行日志数据。 【组件】针对存算分离场景(数据存储在TOS),我们在当前版本支持在EMR集群外采用全托管模式独立部署Hive Metastore(HMS)服...
功能发布记录(2023年)
HBase 数据源支持火山引擎 HBase 数据库标品数据源配置; Doris 数据源新增支持离线读取 Doris 数据; 新增 VeDB 数据源配置,支持离线读取和写入 VeDB 数据; 新增火山引擎 TLS 数据源配置 实时整库、分库分表同步解... 临时查询 Serverless Flink SQL 实时任务运维 2 数据集成 实时分库分表、实时整库解决方案中新增 DataSail 内置缓存通道; 新增实时数据采集解决方案; 新增 DataSail 数据源配置; TOS 数据源支持离线方式写入数...
数据同步方案
1. 概述 数据集成是稳定高效的数据同步平台,致力于提供丰富的异构数据源之间高速稳定的数据同步能力。 2. 功能介绍 数据集成概览请前往查看:数据集成概述 离线集成:提供的离线数据同步能力,将源端数据库中数据按调度周期同步至目标数据库中,实现目标库和源库的数据对应。详见:离线数据同步 流式集成:提供的流式数据同步能力,将源端数据库中数据实时同步至目标数据库中,实现目标库实时保持和源库的数据对应。详见:流式数据同步 ...
通过 Java SDK 写入日志
请参见安装 Java SDK。 已添加 VOLCENGINE_ACCESS_KEY_ID 等环境变量。环境变量的配置方式请参考配置身份认证信息。注意 推荐通过环境变量动态获取火山引擎密钥等身份认证信息,以免 AccessKey 硬编码引发数据安全风险。 写入日志 场景说明本文档通过示例代码演示如何通过 SDK 写入日志数据到日志服务。Java SDK 支持通过以下方式写入日志: 写入方式 说明 PutLogs 不推荐。日志服务支持通过 PutLogs 接口同步请求的方式上传...
通过 Java SDK 消费日志数据
为了提高数据消费效率,建议通过 Java Consumer 方式消费日志数据。Consumer 支持负载均衡地消费日志主题下所有分区的数据,具有异步消费、高性能、失败重试、优雅关闭等特性。示例代码请参考Consumer 消费日志数据,通过消费组消费日志的详细说明请参考通过消费组消费数据、通过 Java SDK 消费组消费日志。 ConsumeLogs 不推荐。日志服务支持通过 ConsumeLogs 接口同步请求的方式上传日志。消费日志的进度受限于单个 Shard 的读写...
管理跨区域复制(Java SDK)
TOS 支持跨区域复制,您可以将一个地域的对象复制到不同地域的存储桶中。配置跨区域复制规则后,当您在源桶中上传新文件时,TOS 会自动将文件同步至目的桶内。该功能用于满足异地容灾和数据复制的需求。 设置跨区域复制规则您可以通过 TOS Java SDK 的 putBucketReplication 接口设置指定桶的跨区域复制规则。 注意事项设置跨区域复制规则之后,才会同步相应文件。 跨区域复制采用异步复制机制,根据您的文件大小,需要的时间为几分钟至...
上传回调(Java SDK)
发送同步的 POST 回调请求到 CallBack 中指定的第三方应用服务器,在服务器确认接受并返回结果后,才将所有结果返回给客户端。关于上传回调的详细介绍,请参见上传回调。 示例代码从 2.6.0 版本开始,Java SDK 支持在 ... try{ // 上传的数据内容,以 String 的形式 String data = "1234567890abcdefghijklmnopqrstuvwxyz~!@$%^&*()_+<>?,./ :'1234567890abcdefghijklmnopqrstuvwxyz~!@$%^&*()_+<>?,./...
