教育目的的哈希表问题
 社区干货
社区干货
分布式数据缓存中的一致性哈希算法|社区征文
一致性哈希算法在分布式缓存领域的 MemCache,负载均衡领域的 Nginx 以及各类 RPC 框架中都有广泛的应用,它主要是为了解决传统哈希函数添加哈希表槽位数后要将关键字重新映射的问题。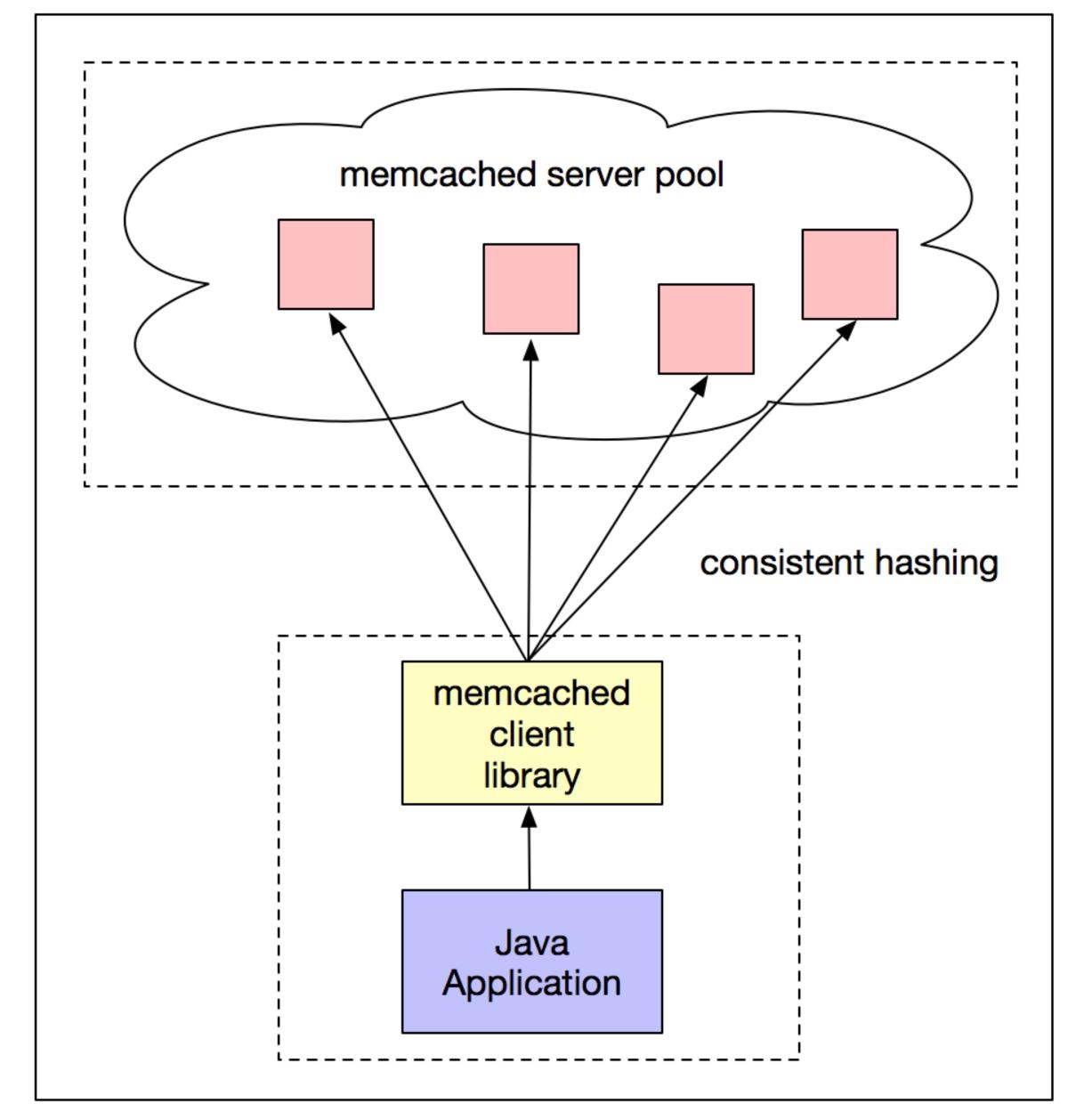本文会介绍一致性哈希算法的原理及其实现,并给出其不同哈希函数实现的性能数据对比,探讨 Redis 集群的数据分片实...
万字长文带你漫游数据结构世界|社区征文
**数据是对客观事务的符号表示**,在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号总称。那为何加上**“结构”**两字?**数据元素是数据的基本单位**,而任何问题中,数据元素都不是独立存在的,它们... 也叫哈希表),是根据键(Key)而直接访问在内存储存位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数...
干货 | 基于ClickHouse的复杂查询实现与优化
若采用哈希表的方式进行去重,第二阶段需在Coordinator单机上去合并各个Worker的哈希表。这个计算量会很重且无法并行。**第二类,由于目前ClickHouse模式并不支持Shuffle,因此对于Join而言,右表必须为全量数据。**无论是普通Join还是Global Join,当右表的数据量较大时,若将数据都放到内存中,会比较容易OOM。若将数据spill到磁盘,虽然可以解决内存问题,但由于有磁盘 IO 和数据序列化、反序列化的代价,因此查询的性能会受到影响。...
基于ClickHouse的复杂查询实现与优化|社区征文
若采用哈希表的方式进行去重,第二阶段需在Coordinator单机上去合并各个Worker的哈希表。这个计算量会很重且无法并行。**第二类,由于目前ClickHouse模式并不支持Shuffle,因此对于Join而言,右表必须为全量数据。** 无论是普通Join还是Global Join,当右表的数据量较大时,若将数据都放到内存中,会比较容易OOM。若将数据spill到磁盘,虽然可以解决内存问题,但由于有磁盘 IO 和数据序列化、反序列化的代价,因此查询的性能会受到影响。...
 特惠活动
特惠活动
 教育目的的哈希表问题-优选内容
教育目的的哈希表问题-优选内容
 教育目的的哈希表问题-相关内容
教育目的的哈希表问题-相关内容
为君作磐石——人人都能搭建大规模推荐系统
首先会定义出多个优化目标(例如视频的播放时长、点赞、分享,电商的点击、加购、购买等),之后构建一个或多个模型来预估这些目标,最后融合多个目标的预估分来完成排序。 **对推荐系统来说,最核心的工作,便是构建精准... 搭建推荐系统一般会遇到哪些问题?我们先来看一个故事。**A 公司的故事**A 是一家电商公司,他们的产品有 300 万 DAU,有一个 10 人的算法团队,他们在搭建推荐系统的过程中,遇到了不少麻烦,我们具体来看看。...
基于 Flink 构建实时数据湖的实践
Schema 演进是流处理中一个常见的问题,即通过在流作业过程中动态变更目的端的 Schema 保证数据的正确写入。Iceberg 本身对 Schema 变更有很好的支持。在 Iceberg 的存储架构中:Catalog 是不存储 Schema 的,只存储最新的 Metadata 文件位置。 Metadata文件存储着所有 Schema id 到 Schema 信息的映射,以及最新的 Schema id——Current-Schema-id。底下的每个 Manifest 记录一个 Schema id,代表 Manifest 底下的 Parquet 文件用的都...
基于 Flink 构建实时数据湖的实践
Schema 演进是流处理中一个常见的问题,即通过在流作业过程中动态变更目的端的 Schema 保证数据的正确写入。Iceberg 本身对 Schema 变更有很好的支持。在 Iceberg 的存储架构中:Catalog 是不存储 Schema 的,只存储最新的 Metadata 文件位置。Metadata文件存储着所有 Schema id 到 Schema 信息的映射,以及最新的 Schema id——Current-Schema-id。底下的每个 Manifest 记录一个 Schema id,代表 Manifest 底下的 Parquet 文件用的都...
干货 | UniqueMergeTree:支持实时更新删除的ClickHouse表引擎
版本号能用来表示数据的写入顺序。同一批次的数据不包含重复key,但不同批次的数据包含重复key,这就需要在读的时候去做合并,对key相同的数据返回去最新版本的值,所以叫merge on read方案。ClickHouse的ReplacingMergeTree和Doris用的就是这种方案。大家可以看到,它的写路径是非常简单的,是一个很典型的写优化方案。它的问题是读性能比较差,有几方面的原因。首先,key-based merge通常是单线程的,比较难并行。其次merge过程需...
基于 Flink 构建实时数据湖的实践
Schema 演进是流处理中一个常见的问题,即通过在流作业过程中动态变更目的端的 Schema 保证数据的正确写入。Iceberg 本身对 Schema 变更有很好的支持。在 Iceberg 的存储架构中:Catalog 是不存储 Schema 的,只存储最新的 Metadata 文件位置。Metadata文件存储着所有 Schema id 到 Schema 信息的映射,以及最新的 Schema id——Current-Schema-id。底下的每个 Manifest 记录一个 Schema id,代表 Manifest 底下的 Parquet 文件用的都...
干货 | 实时数据湖在字节跳动的实践
其中最主要的两个问题是:首先,数据集市只保留了部分属性,只能解决预先定义好的问题;另外,数据集市中反映细节的原始数据丢失了,限制了通过数据解决问题。从解决问题的角度出发,希望有一个合适的存储来保存这些明细的... 为了解决这个数据难管理的问题,Databricks 提出了一个 Lakehouse 的架构,就是在存储层之上去构建统一的元数据缓存和索引层,所有对数据湖之上数据的使用都会经过这个统一的一层。在这一点上和我们的目标是很相似的,...
eBPF 完美搭档:连接云原生网络的 Cilium
存在的问题:1. 可扩展性差。随着 `service` 数据达到数千个,其控制面和数据面的性能都会急剧下降。原因在于 iptables 控制面的接口设计中,每添加一条规则,需要遍历和修改所有的规则,其控制面性能是`O(n²)`。在... 可无限扩容的哈希表来存储信息。对于南北向负载均衡,Cilium 做了最大化性能的优化。支持 XDP、DSR(Direct Server Return,LB 仅仅修改转发封包的目标 MAC 地址) 1. 多集群的连通性,Cilium Cluster Mesh 支持多...
干货|火山引擎DataTester:5个优化思路,构建高性能A/B实验平台
**现状及问题**实验指标报告页是DataTester系统最核心的功能之一,报告页的使用体验直接决定了DataTester作为数据增长和实验评估引擎在业界的竞争力。该功能具有以下特点:1. **牵连系统多、链路长:** 报告页涉及到控制台(Console)、科学计算模块、查询引擎、OLAP存储引擎。整个链路包括了:DSL到sql转化、后端查询结果缓存处理、查询结果的加工计算、前端查询接口的组装和数据渲染。2. **实现复杂:** 实验指标有多种...
附录
但是问题在于写入。假设客户总用户数量为1000W,则单个节点写完数据的时间为1000W / 5W = 200s。按照用户数量,用户需要导入的标签、属性数,以及用户期望所有导入任务完成时间,可以用如下式子来评估: 节点数量=ROUNDUP(用户数量*(导入标签数+导入属性数+Id mapping关系数)/(tendis的写入qps*3600*期待的导入小时数), 0)*(tendis副本数+1) 3. 全局常用错误码表 错误码 报错信息 解决方法 1010340000004 {"msg":"app 还没有分配此接口...
