数据库分层抽样做趋势图
 社区干货
社区干货
字节跳动数据库的过去、现状与未来
弥补了传统数据库的痛点,带来了高可扩展性、全面自动化、快速部署、节约成本、管理便捷等优势。从 2018 到 2021 年,伴随业务和数据的迅猛增长,字节跳动的分布式数据库系统取得了令人振奋的发展。如下图所示,在这... 数据库团队在设计上采用了分层式架构,由高性能网络连接上层的数据库和底层的分布式存储引擎平台。整个 veDB 的架构遵循的基本哲学是分离。首先是计算和存储的分离。如下图所示,veDB 分为计算层和存储层,其中计...
字节跳动数据库的过去、现状与未来
弥补了传统数据库的痛点,带来了高可扩展性、全面自动化、快速部署、节约成本、管理便捷等优势。从 2018 到 2021 年,伴随业务和数据的迅猛增长,字节跳动的分布式数据库系统取得了令人振奋的发展。如下图所示,在这... 数据库团队在设计上采用了分层式架构,由高性能网络连接上层的数据库和底层的分布式存储引擎平台。整个 veDB 的架构遵循的基本哲学是分离。首先是 **计算和存储的分离** 。如下图所示,veDB 分为计算层和存储...
2022技术盘点之平台云原生架构演进之道|社区征文
下图为SmartOps架构全景: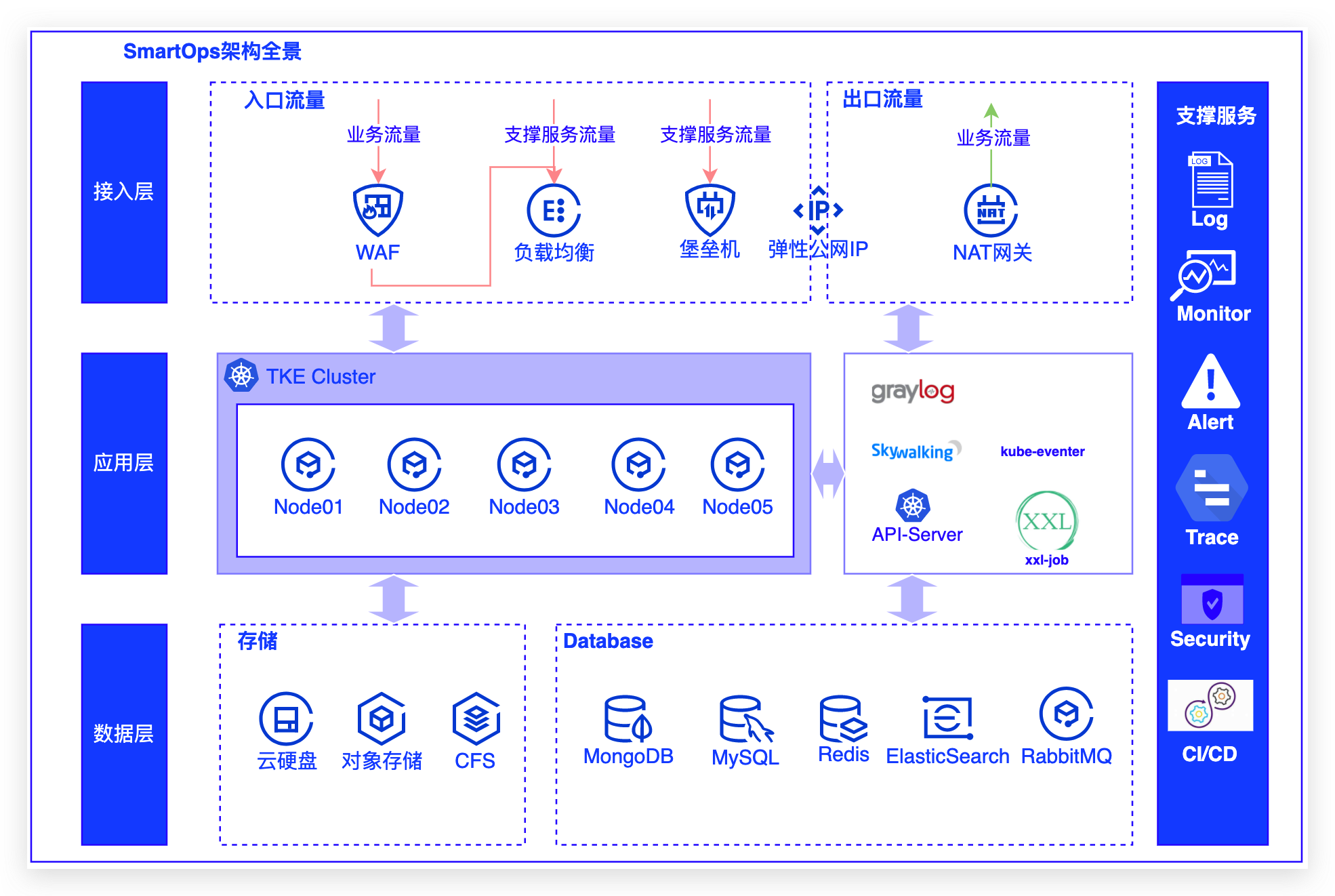- 接入层:通过WAF/SLB,配合NAT网关治理出方向流量,部署有堡垒机进行运维等其他辅助业务进行支撑;- 应用层:采用腾讯TKE进行业务容器部署,配合K8s原生服务注册发现/配置中心/分布式调度中心/日志/监控/告警/链路追踪/DevOps等构筑完整应用体系;- 数据层:存储使用有云硬盘/对象存储/CFS,数据库有Mon...
工业大数据分析与应用——知识总结 | 社区征文
数据库、数据仓储、MOLAP、HOLAP、数据转换工具、数据安全等。 - 大数据分析与发现 - 如数据挖掘、数据统计、基于大数据的业务分析与预测、基于大数据的决策、商业智能、人工智能、数据可视化等。 - 大数据... 不方便用数据库二位逻辑表来表现的数据。### 1.3 大数据的影响* 思维方式上,完全颠覆了传统的思维方式:全样而非抽样、效率而非精确、相关而非因果* 社会发展上,大数据决策逐渐成为一种新的决策方式,大数据应用...
 特惠活动
特惠活动
 数据库分层抽样做趋势图-优选内容
数据库分层抽样做趋势图-优选内容
 数据库分层抽样做趋势图-相关内容
数据库分层抽样做趋势图-相关内容
20000字详解大厂实时数仓建设 | 社区征文
汇总层少建的好处:在汇总统计的时候,往往为了容忍一部分数据的延迟,可能会人为的制造一些延迟来保证数据的准确。举例,在统计跨天相关的订单事件中的数据时,可能会等到 00:00:05 或者 00:00:10 再统计,确保 00:00... mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要包括订单相关的 binlog 日志,冒...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
操作型数据库的数据组织面向事务处理任务,各个业务系统之间各自分离,而数据仓库中的数据是按照一定的主题域进行组织的。 2、集成的【大一统、全链路】 数据仓库中的数据是在对原有分散的数据库[数据抽取](h... 可以对企业的发展历程和未来趋势做出[定量分析](https://wiki.mbalib.com/wiki/%E5%AE%9A%E9%87%8F%E5%88%86%E6%9E%90 "定量分析")和预测。以上是数据仓库的广泛定义,随着企业数字化转型的大浪潮中,我们需要把数...
干货 | 这样做,能快速构建企业级数据湖仓
主要介绍了数据湖仓开源趋势、火山引擎 EMR 的架构及特点,以及如何基于火山引擎 EMR 构建企业级数据湖仓。> > > > :上云迁移背景与流程
> **王志雷**,火山引擎存储&数据库解决方案架构师,专注于存储&数据库产品的解决方案规划、设计和拓展工作。 > **贾伟力**,火山引擎存储&数据库解决方案架构师,专注于存储&数据库产品的解决方案规划、设计和拓展... ### 为什么要做云迁移?#### 上云迁移给企业带来的收益- **节约成本**:企业将生产或测试环境直接部署于云上,借助云上按量使用,弹性伸缩,免运维等特点,且企业无需投入构建机房、服务器等硬件设备和减少运维投入,节...
V2.58.0
PostgreSQL 数据库的直连方式,可以满足用户对数据实时性的要求。 【新增】LAS 连接新增抽取新链路 在数据连接的 LAS 连接中新增抽取新链路, LAS 抽取链路不经过JDBC,改成直接传输数据到 hdfs。如下图所示: 【优化... 对数据做更新;(4)数据集中的维度表模块支持集群迁移,更新后可支持带维度的数据集的迁移;(5)数据集和可视化建模两个模块均支持 decimal 数据格式。 2.2 可视化查询相关【新增】指标趋势图优化 指标趋势图支持添加行...
字节跳动基于数据湖技术的近实时场景实践
即不会事先对它的 schema 做过多的定义,而是在使用的时候才去决定 schema,从而支持上游更丰富、更灵活的应用。2. ## **字节**数据湖Apache Hudi有下面非常重要的特性:- Hudi不仅仅是数据湖的一种存储格式(Table Format),而是提供了Streaming 流式原语的、具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。 - Hudi 支持各类计算、查询引擎(Flink、Spark、Presto、Hive),底层存储兼容各...
数据清洗
离线任务 采样 「待回访用户表」中可能有用户重复出现,对“用户id”去重,每个用户只保留一行数据。 离线任务 数据拆分 将一份数据按照设定比例拆分成两份数据 离线任务 字符串索引 将指定的属性的值映射成数值型索引,使得只能对数值型数据做处理的算子 也可以对属性进行处理。 离线任务 IDMapping算子 根据所选择的ID-Mapping类型,通过ID-Mapping服务转换查询到已经存在的OneID,如未购买CDP产品,此算子将无法使用。 1. 根据输...
超复杂调用网下的服务治理新思路
如果用户想要在域外访问这个数据库,我们需要通过左下角的 Query、ETL 把它转化成一个离线数据库。整个大框是一个 domain,它不同于 DDD 的 domain,它被称为服务域,可以理解成是一组服务的集合。字节跳动内部也参考了... 其中第一个核心叫做服务分层原则。正如前文的微服务架构图所示,服务在经历从上到下的调用后出现了很复杂的调用关系,对此,我们可以依据康威定律对它做一些横向切分,对调用关系进行分层。