数据库流程图的作用
 社区干货
社区干货
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
由缓存组件来管理自身与数据库之间的数据同步。**### 2.3 Write-Through 同步直写**与 Read-Through 类似,发生写请求时,Write-Through 将写入责任转移到缓存系统,由缓存抽象层来完成缓存数据和数据库数据的更新**,时序流程图如下: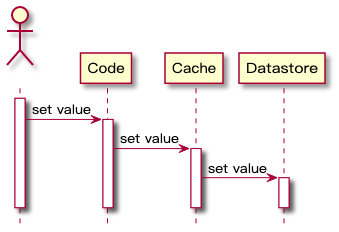`Write-Through` 的主要好处是应用系统的不需要考虑故障处理和重试逻辑,交给缓存抽象层来管理实...
一文读懂火山引擎云数据库产品及选型
> **火山引擎存储&数据库产品解决方案团队**,由资深的存储&数据库解决方案架构师组成。团队致力于帮助企业与组织更好的使用火山引擎云存储与云数据库产品,针对实际业务场景设计最优的解决方案,用专业技术助力组织和企业实现业务成功。## 为什么要做数据库选型### 数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软...
一文了解数据库事务和隔离级别 | 社区征文
## 1. 什么是事务事务是数据库管理系统(DBMS)执行过程中的一个逻辑单位(不可再进行分割),由一个有限的数据库操作序列构成(多个DML语句,select语句不包含事务),要不全部成功,要不全部不成功。如 A 给 B 要划钱,... 只对执行完该语句之后产生的会话起作用,当前已经存在的会话无效。**使用** **SESSION** **关键字(在会话范围影响):**```SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; ```对当前会话的所有后续的...
未来向量数据库的崛起与多元化场景创新 主赛道 | 社区征文
# 向量数据库的崛起与多元化场景创新## 前言:> 在如今的数字时代,数据被称作金子,对企业、科学家和管理者都有很大价值。但是,随着数据规模的不断增长,高效的管理、存储和检索数据变得越来越复杂。这引进了当今... 数据库具有高效的并行处理水准,即便是规模性向量数据,也在短时间内寻找最匹配的结果。因而,优化查询算法,提升数据浏览效率,乃至实现实时数据升级,将是提升并行处理技能的关键问题。**3、高级查询作用**随着用户对...
 特惠活动
特惠活动
 数据库流程图的作用-优选内容
数据库流程图的作用-优选内容
 数据库流程图的作用-相关内容
数据库流程图的作用-相关内容
一文读懂火山引擎云数据库产品及选型
为什么要做数据库选型 **数据库选型的重要性与难点**发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础... 我们把选型方法论和火山引擎云数据库产品能力结合在一起,就可以得到了如下的一张选型流程图,按照流程可以确定应用需要的云数据库类型,供大家参考。- 主键通常与按键排序的作用相同,用于整理数据文件。 分区键 (强制)- 分区键用于决定表中的每行属于哪个数据分区...
[数据库论文研读] HTAP行列混存 & 智能转换
称为HTAP数据库罢了。这么做的话数据仍然要存两份(row & column),管控面的麻烦从外部转移到内部而已,并没有什么实际的架构创新。**所以,本论文提出了一种新的想法,**不再“分而治之”,而是要构建一个统一的存储层... 采用Tile-Based结构的好处:1. 由于加入了统一的抽象层——逻辑Tile层,所以底层存储结构的细节对计算层透明,开发比较友好1. 可向量化,原本很多系统采用的是Volcano模型(open-next-close语义,参考[Volcano](htt...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据,改善用户与数据库的交互方式。#### 2.2 NL2SQL的目标与定位从技术的角度来看,NL2SQL的本质是将用户的自然语言语句转化为计算机可... 最终的损失函数为loss_wc+loss_wo+loss_ws+loss_sel。模型的优化器可使用Adam优化器,是目前深度模型常用的优化器,包含两阶动量对梯度进行处理,其算法流程图如图五。 ByteHouse选择的分布式key-value存储系统,ByteKV和Foundation已经提供了一致性的支持,直接复用即可。- Isolation(隔离性)ByteHouse对用户提供Read Committed(...
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... 作用是提供高性能的 inserts和 updates;1. RS: Read-optimized Store,作用是提供针对读优化的高效查询,仅提供固定格式的insert方法;Tuple Mover 负责批量从WS搬运到RS;Query 需要访问WS和RS,然后合并结果;inse...
一文读懂火山引擎云数据库产品及选型
# 1、为什么要做数据库选型## 1.1、数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软件领域,有三... 我们把选型方法论和火山引擎云数据库产品能力结合在一起,就可以得到了如下的一张选型流程图,按照流程可以确定应用需要的云数据库类型,供大家参考。