数据库概念模型独立于er图
 社区干货
社区干货
未来向量数据库的崛起与多元化场景创新 主赛道 | 社区征文
这引进了当今向量数据库系统,能够反转数据解决与分析的方式...随着大模型的兴起,向量数据库越来越成为开发者关注的重点。## 一、概述:”。关系型数据库也是过去几十年里各行各业使用最多最广泛的数据库类型。随着 2000 年之后移动互联网的大规模爆发,催生出了丰富多彩的面向互联网的应用,这些应用共同的特点是并发量非常高,数据量特别大。基于这些互联网的新场景与新需求,又出现了 NoSQL 数据库技术,其理论基础主要是由 Eric Brewer 提出的 CAP 定理以及 Dan Pritchett ...
VikingDB:大规模云原生向量数据库的前沿实践与应用
RAG(Retrival-Augmented Generation) 成为了当前业界最流行的解决方案。RAG 结合检索和生成两个关键组件,通过检索为大模型提供相关数据作为上下文信息。由于向量数据库能够高效存储和检索模型生成的向量,从而提供语... 而向量数据库又是以 embedding 作为核心概念,并围绕其提供存储检索能力的基础软件,因此可以说 **向量数据库是 AI 原生应用程序的基础设施** 。为了更好地胜任 AI 基础设施的角色和贴合大模型的生态,VikingDB ...
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... 每insert/update/delete 一行数据,由于会去更新存在在不同位置的column,会带来IO放大,且为随机IO。# 发展其实在1983年列存概念就在Cantor论文【11】中提出了,85年Copeland and Khoshafian在SIGMOD上首次提出了...
 特惠活动
特惠活动
 数据库概念模型独立于er图-优选内容
数据库概念模型独立于er图-优选内容
 数据库概念模型独立于er图-相关内容
数据库概念模型独立于er图-相关内容
分布式数据库在抖音春晚活动中的应用
## 分布式数据库架构简介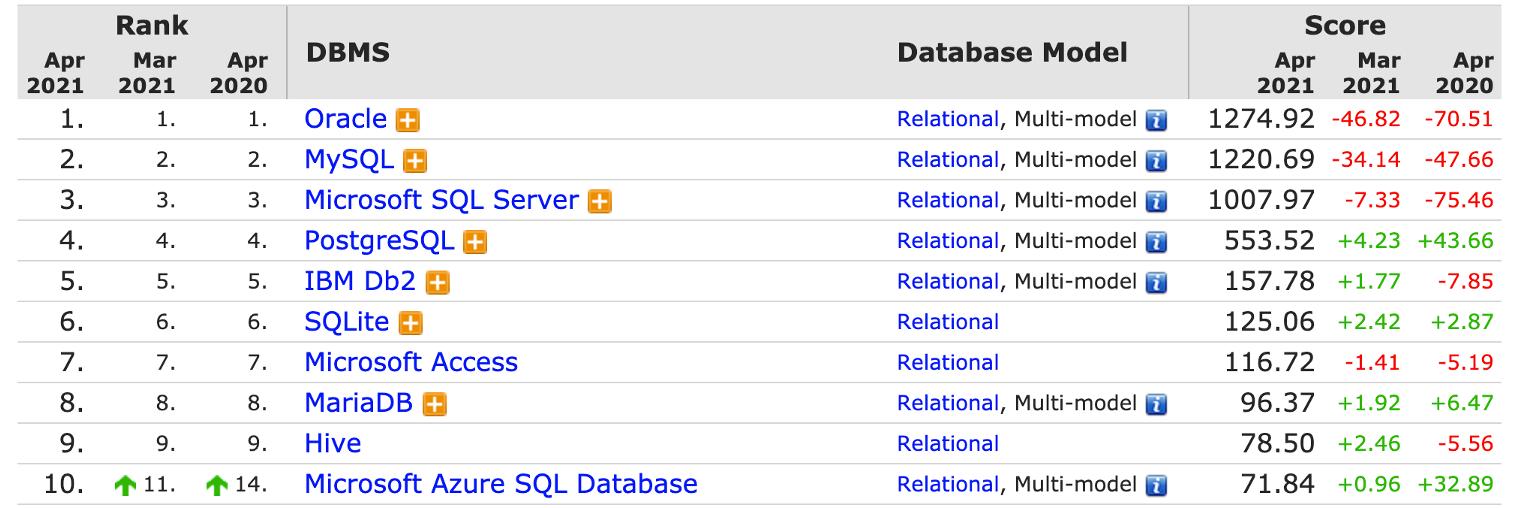相信对数据库感兴趣的同学对上面这张图也不会陌生。这... Buffer Pool- 日志子系统- 事务子系统- 锁子系统可以这么说,缺了上述任意一个模块都很难构建出一个具有完备 ACID 特性的关系型数据库。了解关键子模块后,我们来看看计算层的数据模型。对于用户或...
[数据库论文研读] HTAP行列混存 & 智能转换
概念,基本上可以认为只有read/scan操作。- OLTP应用在存储侧的layout一般为行存,OLAP应用则一般为列存因为OLTP和OLAP的差异,现有的数据分析系统(或者说数据分析的pipeline)一般是部署两套独立的系统。OLTP系... 称为HTAP数据库罢了。这么做的话数据仍然要存两份(row & column),管控面的麻烦从外部转移到内部而已,并没有什么实际的架构创新。**所以,本论文提出了一种新的想法,**不再“分而治之”,而是要构建一个统一的存储层...
一文读懂火山引擎云数据库产品及选型
其理论基础是基于 IBM 研究员 E.F.Codd 博士在 1970 年提出的“关系模型(Relational model)”。关系型数据库也是过去几十年里各行各业使用最多最广泛的数据库类型。随着 2000 年之后移动互联网的大规模爆发,催生出了丰富多彩的面向互联网的应用,这些应用共同的特点是并发量非常高,数据量特别大。基于这些互联网的新场景与新需求,又出现了 NoSQL 数据库技术,其理论基础主要是由 Eric Brewer 提出的 CAP 定理以及 Dan Pritchett...
分布式数据库TiDB的设计和架构
有个新的概念为分布式关系型数据库(NewSQL),它是兼具NoSQL扩展性又不丧失传统关系型数据库ACID特性的分布式数据库。随着互联网向银行、电信、电力等方向的渗透,传统行业数据量迅速提升,需要同时满足低成本、线性扩容及能够处理交易类事务的新型数据库,大数据的存储刚需不可避免。NewSQL的挑战在于,它是基于 Google Spanner/F1 论文,未开源它的代码及技术细节,是基础软件最前沿的领域之一,技术门槛最高。NewSQL 代表产品有Spanner...
一文读懂火山引擎云数据库产品及选型
其理论基础是基于IBM 研究员 E.F.Codd 博士在1970年提出的“关系模型(Relational model)”。关系型数据库也是过去几十年里各行各业使用最多最广泛的数据库类型。随着2000年之后移动互联网的大规模爆发,催生出了丰富多彩的面向互联网的应用,这些应用共同的特点是并发量非常高,数据量特别大。基于这些互联网的新场景与新需求,又出现了NoSQL数据库技术,其理论基础主要是由Eric Brewer提出的CAP定理以及Dan Pritchett提出的BASE原则...
字节跳动自研万亿级图数据库 & 图计算实践
并将介绍图计算相关实践。 自研图数据库(ByteGraph)介绍 从数据模型角度看,图数据库内部数据是有向属性图,其 **基本元素是 Graph 中的点(Vertex)、边(Edge)以及其上附着的属性... 磁盘存储层独立部署,我们详细介绍每一层的关键设计。